Threads and synchronization
Introduction to threads and synchronization.
Introduction to threads and synchronization.
Concurrency refers to the ability of different parts or units of a program, algorithm, or problem to be executed out-of-order or in partial order, without affecting the final outcome. This allows for parallel execution of the concurrent units, which can significantly improve overall speed of the execution in multi-processor and multi-core systems. 1
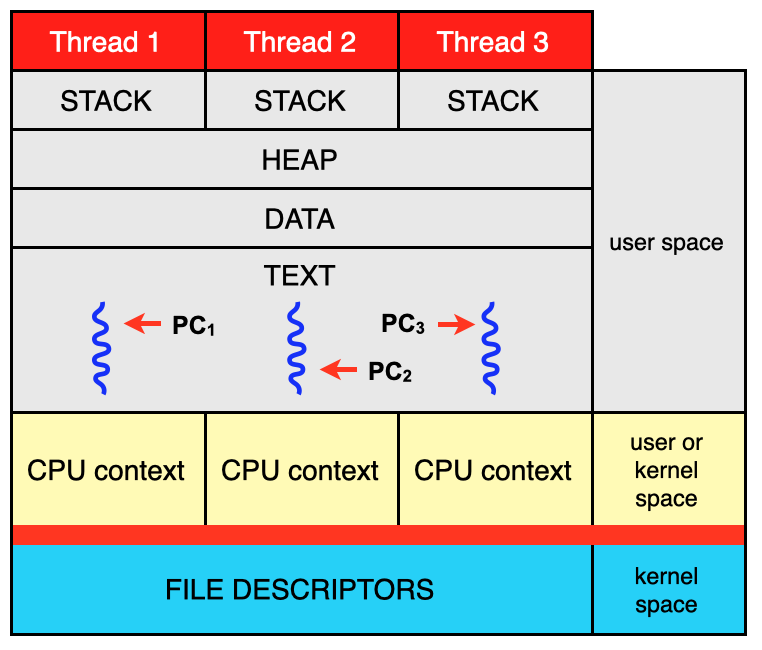
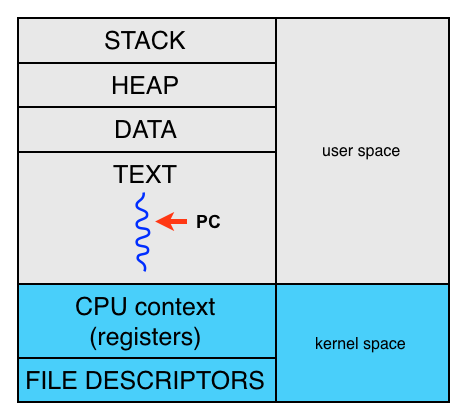
To run a program the operating system must allocate memory and creates a process. A processes has a stack, a heap, a data segment and a text segment in user space. The CPU context and file descriptor table are kept in kernel space. When executing the program, the program counter (PC) jumps around in the text segment.
A process can have one or more threads of execution. Threads share heap, data segment, text segment and file descriptor table but have separate stacks and CPU contexts. Each thread has a private program counter and threads executes concurrently. Depending on how threads are implemented, the CPU contexts can be stored in user space or kernel space. In the below figure a process with three threads is shown.
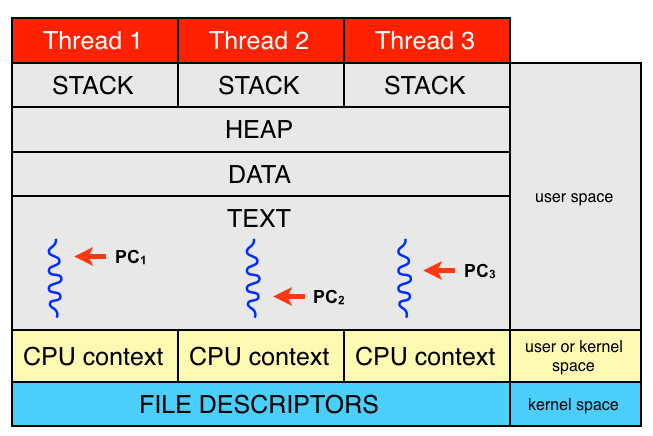
If not explicitly stated otherwise, the term task will be used to refer to a concurrent unit of execution such as a thread or a process.
In concurrent programming, an operation (or set of operations) is atomic if it appears to the rest of the system to occur at once without being interrupted. Other words used synonymously with atomic are: linearizable, indivisible or uninterruptible. 2
Incrementing and decrementing a variable are examples of non-atomic operations. The following C expression,
X++;, is translated by the compiler to three instructions:
X from memory into a CPU register.X and save result in a CPU register.Similarly, the following C expression,
X--;, is translated by the compiler to three instructions:
X from memory into a CPU register.X and save result in a CPU register.X back to memory.A race condition or race hazard is the behaviour of an electronic, software or other system where the output is dependent on the sequence or timing of other uncontrollable events. It becomes a bug when events do not happen in the intended order. The term originates with the idea of two signals racing each other to influence the output first. 3
A data race occurs when two instructions from different threads access the same memory location and:
Concurrent accesses to shared resources can lead to unexpected or erroneous behavior, so parts of the program where the shared resource is accessed are protected. This protected section is the critical section or critical region. Typically, the critical section accesses a shared resource, such as a data structure, a peripheral device, or a network connection, that would not operate correctly in the context of multiple concurrent accesses.4
In computer science, mutual exclusion is a property of concurrency control, which is instituted for the purpose of preventing race conditions; it is the requirement that one thread of execution never enter its critical section at the same time that another concurrent thread of execution enters its own critical section.5
Often the word mutex is used as a short form of mutual exclusion.
Before you continue, you must clone the threads-synchronization-deadlock repository.
From the terminal, navigate to a directory where you want the cloned directory to be created and execute the following command.
git clone https://github.com/os-assignments/threads-synchronization-deadlock.gitNow you should see something similar to this in the terminal.
Cloning into 'threads-synchronization-deadlock'...
remote: Counting objects: 23, done.
remote: Compressing objects: 100% (20/20), done.
remote: Total 23 (delta 1), reused 23 (delta 1), pack-reused 0
Unpacking objects: 100% (23/23), done.To get an overview of the cloned repository, use the tree -d command.
tree -d threads-synchronization-deadlockNow you should see a tree view of the directory strucure.
threads-synchronization-deadlock
├── examples
│ ├── bin
│ ├── obj
│ └── src
├── higher-grade
│ ├── bin
│ ├── obj
│ └── src
└── mandatory
│ ├── bin
│ ├── obj
│ ├── psem
│ └── src
└── psem
14 directoriesIf you run macOS and tree is not installed, use Homebrew to install tree.
brew install treeIn the threads-synchronization-deadlock directory you find the all utility script.
The all utility can be used to run a shell command in all subdirectories,
i.e., run a command in all of the three directories examples, higher grade
and mandatory. In the terminal, navigate to the threads-synchronization-deadlock directory.
For example, you can use the all utility together with make to compile all
programs.
./all makeThe all utility can also be used to delete all objects files and executables.
./all make clean
In this assignment you will study different methods to enforce mutual exclusion.
This assignment make use of atomic operations available only on computers with Intel CPUs running Linux or macOS.
If you are working on Windows or on Linux or macOS but with a non-Intel CPU, you can use the department Linux system for this assignment. You may still use your private computer to access the department Linux system using SSH but make sure to log in to one of the Linux hosts.
mandatory/src/mutex.ccounter is initialized to 0
and then incremented by the threads in set I and decremented by the threads in
set D. The sum of all the increments is equal to the absolute value of the sum
of all the decrements.20 times
by 2. In total the counter will be incremented by 5*20*2 = 200.
There are two threads in set D, each decrementing the counter 20 times by 5. In
total the counter will be decremented by 2*20*5 = 200.0 (the same as value it was initialized with).The provided program will execute 4 different tests. For each test, a different
approach to synchronization will be used by the threads updating the shared
counter variable.
In the terminal, navigate to the mandatory directory. Use
make to compile the program.
makeThe executable will be named mutex and placed in the bin sub directory. Run the program from the terminal.
./bin/mutexAt the end of the program output, a summary of the four tests will be printed.
Run the program several times and study the provided source code.
Identify the critical sections in the program. The critical sections should be as small as possible.
Your task is to make sure that at any time, at most one thread execute in a critical section, i.e., access to the critical sections should be mutual exclusive. You will use three different methods to ensure that updates to the shared counter variable appear to the system to occur instantaneously, i.e., make sure updates are atomic.
In test 0 the threads uses the functions inc_no_syncx and dec_no_sync to
update the shared variable counter. Updates are done with no
synchronization.
You don’t have to change or add any code to these two functions. This test is used to demonsrate the effects of unsynchronized updates to shared variables.
The first synchronization option you will study is to use the
mutex lock provided by the pthreads library to enforce mutual exclusion
when accessing the shared counter variable.
Add the needed synchronization in the functions inc_mutex and dec_mutex to make
the program execute according to the desired behavior.
An alternative to mutex locks is to use the atomic test-and-set built-in provided by the GCC compiler to implement a spinlock.
This part of the assignment make use of atomic operations available only on computers with Intel CPUs running Linux or macOS.
If you are working on Windows or on Linux or macOS but with a non-Intel CPU, you can use the department Linux system for this assignment. You may still use your private computer to access the department Linux system using SSH but make sure to log in to one of the Linux hosts.
You will use the following function to access the underlying test-and-set operation.
*lock to value and returns the previous
contents of *lock.At the beginning of mutex.c you find the following declaration.
/* Shared variable used to implement a spinlock */
volatile int lock = false;Todo:
lock variable to implement the spin_lock() and spin_unlock()
operations.inc_tas_spinlock and dec_tas_spinlock to use use the
test-and-set spinlock to enforce mutual exclusion.A third option is to use the atomic addition and subtraction GCC built-ins.
This part of the assignment make use of atomic operations available only on computers with Intel CPUs running Linux or macOS.
If you are working on Windows or on Linux or macOS but with a non-Intel CPU, you can use the department Linux system for this assignment. You may still use your private computer to access the department Linux system using SSH but make sure to log in to one of the Linux hosts.
You will use the following functions to access the underlying atomic increment and decrement operations.
*counter by n and returns the
previous value of *counter.*counter by n and returns the
previous value of *counter.Change the functions inc_atomic and dec_atomic to use atomic addition and
subtraction to make the program execute according to the desired behavior.
Study the test summary table printed after all tests have completed.
Here are a few examples of questions that you should be able to answer, discuss and relate to the source code of you solution during the code grading.
Explain the following concepts and relate them to the source code and the behavior of the program.
Locks and semaphores:
test-and-set instruction?Performance analysis:
Linux and macOS natively supports different types of semaphores. In order to
have a single (simple) semaphore API that works on both Linux and macOS you will
use a portable semaphore library named psem.
In the psem/psem.h header file you find the documentation of the
portable semaphore API.
A small example program that demonstrates how to use the sempaphores provided by
the psem library.
#include "psem.h"
int main(void) {
// Create a new semaphore and initialize the semaphore counter to 3.
psem_t *sem = psem_init(3);
// Wait on the semaphore.
psem_wait(sem);
// Signal on the semaphore.
psem_signal(sem);
// Destroy the semaphore (deallocation)
psem_destroy(sem)
}
In mandatory/src/psem_test.c you find a complete example program with
two threads (main and a pthread) that synchronize their execution using a psem
semaphore.
In the terminal, navigate to the examples directory. Use
make to compile the program.
makeRun the program from the terminal.
./bin/psem_test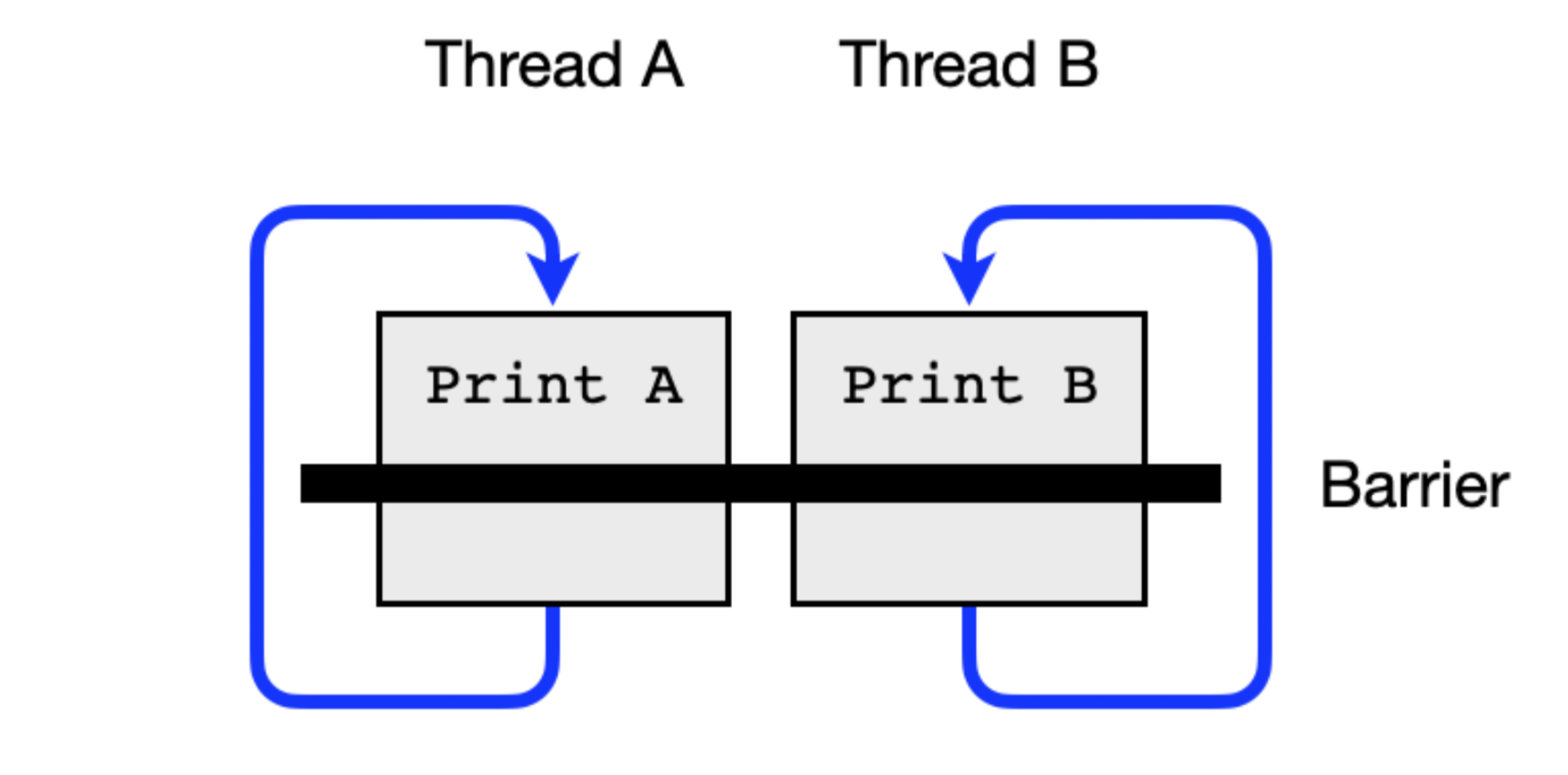
A mutex lock is meant to first be taken and then released, always in that order, by each task that uses the shared resource it protects. In general, semaphores should not be used to enforce mutual exclusion. The correct use of a semaphore is to signaling from one task to another, i.e., a task either signal or wait on a semaphore, not both.
In this assignment you will solve the two thread barrier problem using semaphores. This problem clearly demonstrates the type of synchronization that can be provided by semaphores.
The provided code has been developed and tested on the department Linux system and macOS. Most likely you will be able to use any reasonable modern version of Linux.
mandatory/src/two_thread_barrier.c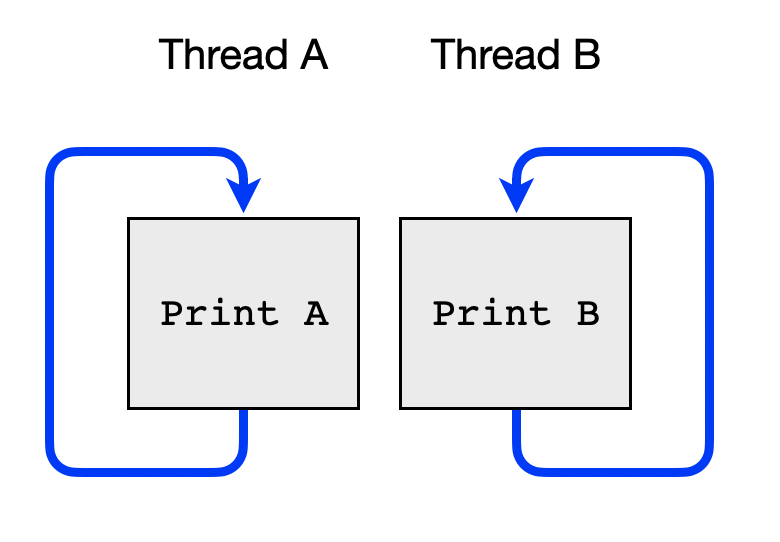
In the terminal, navigate to the mandatory directory.
Use make to compile the program.
makeThe executable will be named barrier and placed in the bin sub directory.
Run the program from the terminal.
./bin/two_thread_barrierRun the programs several times and study the source code. Think about the following questions.
Rendezvous or rendez-vous (French pronunciation: [ʁɑ̃devu]) refers to a planned meeting between two or more parties at a specific time and place. 1
We now want to put in a barrier in each thread that enforces the two threads to have rendezvous at the barrier in each iteration.
For each iteration the order between the threads should not be restricted. The first thread to reach the barrier must wait for the other thread to also reach the barrier. Once both threads have reached the barrier the threads are allowed to continue with the next iteration. Examples of execution traces:
Other names for barrier synchronization are lock-step and rendezvous.
Your task is to use semaphores to enforce barrier synchronization between the two threads A and B.

Before you continue think about the following questions.
Compile:
make, and run the program:
./bin/two_thread_barrierThis is an example of an invalid execution trace when running the two_thread_barrier program.
Two threads A and B doing 5 iterations each in lockstep.
Iteration 0
A
B
Iteration 1
B
A
Iteration 2
B
B <===== ERROR: should have been AThis is an example of a valid execution trace when running the two_thread_barrier program.
Two threads A and B doing 5 iterations each in lockstep.
Iteration 0
A
B
Iteration 1
A
B
Iteration 2
B
A
Iteration 3
A
B
Iteration 4
A
B
SUCCESS: All iterations done in lockstep!In the beginning of two_thread_barrier.c you find the following definitions.
#define ITERATIONS 10 // Number of iterations each thread will execute.
#define MAX_SLEEP_TIME 3 // Max sleep time (seconds) for each thread. Experiment by changing the number of iterations and the max sleep time.
Use the psem semaphores to enforce rendezvous between the two threads. This is how you declare and initialize a portable psem semaphore.
psem_t *semaphore;
semaphore = psem_init(0);How many semaphores are needed to enforce barrier synchronization between two threads?
For simplicity, declare all psem_t semaphore variables globally.
Initialize your semaphore(s) in the beginning of main(). Should the semaphore(s) be initialized with counter value:
At the end of main(), don’t forget to destroy any semaphores you have initialized.
Instead of printing their identity (A or B) directly, the threads uses the provided trace function.
In each iteration thread A calls trace('A') and thread B calls trace('B').
The trace functions prints the thread identity and keeps track of the next valid thread identity
in the traced sequence. If the wrong thread identity is traced an error is reported and the process is terminated.
Here are a few examples of questions that you should be able to answer, discuss and relate to the source code of you solution during the code grading.
This is a new 1 point higher grade assignment replacing the N Thread barrier assignment.
In this higher grade assignment you will do a simple simulation of money transfers between bank accounts.
In order to get the new source files and the updated Makefile for this new
assignment, you need to pull the updates from the GitHub repo.
git pullIn the higher-grade/src directory you find the following files.
The simple bank API is defined in bank.h.
A single bank account is represented by the following C structure.
typedef struct {
int balance;
} account_t;What more is needed to be added to the structure?
These are the functions in the simple bank API.
/**
* account_new()
* Creates a new bank account.
*
* balance
* The initial balance for the new account.
*
* NOTE: You may need to add more parameters.
*
*/
account_t* account_new(unsigned int balance);
/**
* account_destroy()
* Destroys a bank account, freeing the resources it might hold.
*
* account:
* Pointer to a bank account.
*
*/
void account_destroy(account_t* account);
/**
* transfer()
* Attempts to transfer money from one account to another.
*
* amount:
* Amount to transfer.
*
* from:
* The account to transfer money from. Money should only be transferred if
* thee are sufficient funds.
*
* to:
* The account to transfer the money to.
*
* return value:
* Return -1 if not sufficient funds in the from account. Otherwise returns 0.
*
*/
int transfer(int amount, account_t* from, account_t* to);You must add the needed synchronization.
You must make sure to prevent deadlocks.
This is an example of how you can declare and initialize a Pthread mutex lock.
pthread_mutex_t mutex;
if (pthread_mutex_init(&mutex, NULL) < 0) {
perror("Init mutex lock");
exit(EXIT_FAILURE);
}In bank_test.c you find a working program testing your implementation.
Compile:
make, and run the test program:
./bin/bank_testThis is an example showing two rounds of correct synchronization.
Account Amount
------------------
0 500
1 0
2 0
3 200
4 0
5 0
6 0
7 0
8 0
9 0
------------------
Sum: 700
Round 1 of 100
From Amount To Result
7 ---- 200 ---> 8 Insufficient funds
1 ---- 200 ---> 7 Insufficient funds
2 ---- 200 ---> 7 Insufficient funds
0 ---- 150 ---> 4 Ok
3 ---- 200 ---> 0 Ok
Account Amount
------------------
0 550
1 0
2 0
3 0
4 150
5 0
6 0
7 0
8 0
9 0
------------------
Sum: 700
Total amount of money was initially 700 and is now 700.
System invariant (conservation of money) not broken.In this example, everything looks ok in round 4, but in round 5 a race condition is detected.
Round 4 of 100
From Amount To Result
8 ---- 050 ---> 3 Insufficient funds
1 ---- 200 ---> 7 Insufficient funds
4 ---- 100 ---> 6 Insufficient funds
2 ---- 150 ---> 6 Insufficient funds
4 ---- 150 ---> 7 Insufficient funds
Account Amount
------------------
0 500
1 50
2 0
3 50
4 0
5 0
6 100
7 0
8 0
9 0
------------------
Sum: 700
Total amount of money was initially 700 and is now 700.
System invariant (conservation of money) not broken.
Round 5 of 100
From Amount To Result
4 ---- 250 ---> 9 Insufficient funds
9 ---- 150 ---> 3 Insufficient funds
8 ---- 100 ---> 0 Insufficient funds
0 ---- 100 ---> 5 Ok
0 ---- 100 ---> 9 Ok
Account Amount
------------------
0 400
1 50
2 0
3 50
4 0
5 100
6 100
7 0
8 0
9 100
------------------
Sum: 800
Total amount of money was initially 700 and is now 800.
RACE CONDITION: System invariant (conservation of money) broken!You must make sure the simulation never deadlocks. If a deadlock occur, the simulation will halt, for example like this.
Round 57 of 100
From Amount To Result
1 ---- 250 ---> 7 Insufficient funds
6 ---- 150 ---> 3 Insufficient funds
6 ---- 100 ---> 3 Insufficient funds
9 ---- 100 ---> 7 Insufficient funds
8 ---- 100 ---> 5 Ok
Account Amount
------------------
0 50
1 50
2 50
3 50
4 0
5 100
6 0
7 100
8 300
9 0
------------------
Sum: 700
Total amount of money was initially 700 and is now 700.
System invariant (conservation of money) not broken.
Round 58 of 100
From Amount To Result
0 ---- 200 ---> 1 Insufficient funds
2 ---- 050 ---> 7 Ok
3 ---- 200 ---> 7 Insufficient funds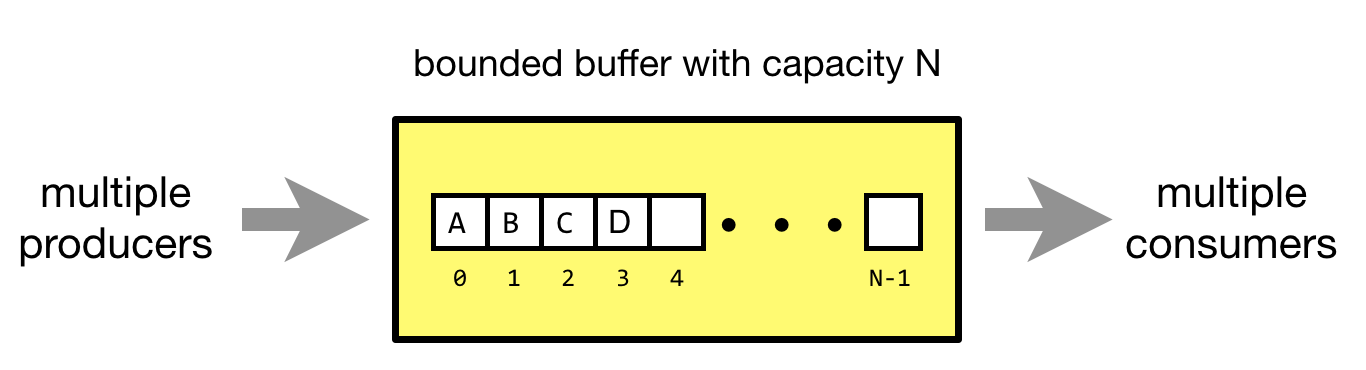
The bounded-buffer problems (aka the producer-consumer problem) is a classic example of concurrent access to a shared resource. A bounded buffer lets multiple producers and multiple consumers share a single buffer. Producers write data to the buffer and consumers read data from the buffer.
Among the slides you find self study material about classic synchronization problems. In these slides the bounded buffer problem is described. Before you continue, make sure to read the self study slides about the bounded buffer problem.
A bounded buffer with capacity N has can store N data items. The places used
to store the data items inside the bounded buffer are called slots. Without
proper synchronization the following errors may occur.
You will implement the bounded buffer as an abstract datatype. These are the files you will use to implement and test your implementation.
mandatory/src/bounded_buffer.h.mandatory/src/bounded_buffer.c file.mandatory/src/bounded_buffer_test.c file. Here you can add your own
tests if you want.mandatory/src/bounded_buffer_test.c program make it easy to
test the implementation for different sizes of the buffer and different numbers
of producers and consumers.The provided code has been developed and tested on the department Linux system and macOS. Most likely you will be able to use any resonable modern version of Linux.
You will us the psem semaphores to synchronize the bounded buffer.
To implement the bounded buffer you will use two C structures and an array of C structures.
The buffer will store tuples (pairs) with two integer
elements a and b. A tuple is represented by the following C struct.
typedef struct {
int a;
int b;
} tuple_t;To implement the bounded buffer a finite size array in memory is shared by a number for producer and consumer threads.
In addition to the shared array, information about the state of the buffer must also be shared.
In the below example three data items B, C and D are currently in the buffer. On
the next write data will be written to index in = 4 . On the next read
data will be read from index out = 1.
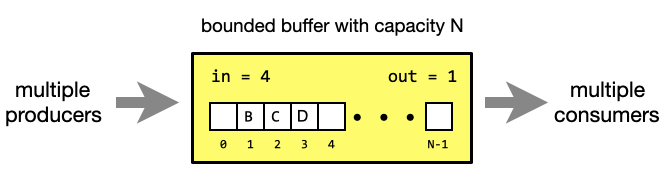
The buffer is represented by the following C struct.
typedef struct {
tuple_t *array;
int size;
int in;
int out;
psem_t *mutex;
psem_t *data;
psem_t *empty;
} buffer_t;The purpose of the struct members are described below.
tuple_t.All updates to the buffer state must be done in a critical section. More specifically, mutual exclusion must be enforced between the following critical sections:
in.out.A binary semaphore can be used to protect access to the critical sections.
Producers must block if the buffer is full. Consumers must block if the buffer is empty. Two counting semaphores can be used for this.
Use one semaphore named empty to count the empty slots in the buffer.
Use one semaphore named data to count the number of data items in the buffer.
A new bounded buffer with 10 elements will be represented as follows.
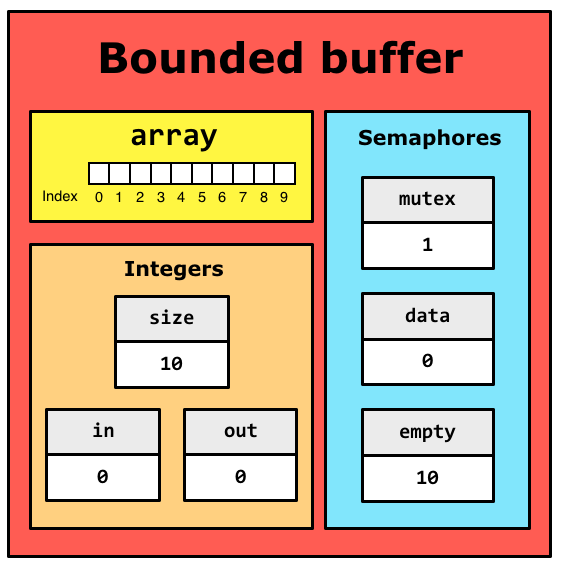
The empty semaphore counts the number of
empty slots in the buffer and is initialized to 10. Initially there are no
data element to be consumed in the buffer and the data semaphore is
initialized to 0. The mutex semaphore will be used to enforece mutex when
updating the buffer and is initialized to 1.
To complete the implementation you must add code at a few places.
Make sure you know how to use pointers to C strutcs before you continue.
You will complete the implementaion step by step.
For each step you will need to add code to a single function in the
mandatory/src/bounded_buffer.c source file. For each step there
is also a test in the mandatory/src/bounded_buffer_test.c source
file that should pass without any failed assertions.
In the terminal, navigate to the mandatory directory. Use make to compile the program.
makeRun the test(s).
./bin/bounded_buffer_testAn example of a failed test where the assertion that the buffer size should be 10 fails.
==== init_test ====
Assertion failed: (buffer.size == 10), function init_test, file src/bounded_buffer_test.c, line 24.When a test passes you will see the following output.
Test SUCCESSFUL :-)You must complete the buffer initialization.
buffer_initinit_testMake sure to initialize all members of the buffer_t struct.
You must complete the buffer destruction.
buffer_destroydestroy_testDeallocate all resources allocated by buffer_init().
psem_destroy() to deallocate all semaphores.NULL after dealloacation to avoid dangling
pointers.buffer_printprint_testAdd code to print all elements of the buffer array.
buffer_putput_testHere you need to:
buffer->in index make sure it wraps around.buffer_getget_testHere you need to:
buffer->out index make sure it wraps around.For this step you only need to run the concurrent_put_get_test. If the test
doesn’t terminate you most likely have made a mistake with the synchronization of
buffer_put and/or buffer_get that result in a deadlock.
It is now time to test the bounded buffer with multiple concurrent producers and
consumers. In mandatory/src/bounded_buffer_stress_test.c you find a
complete test program that creates:
sp producer threads, each producing n items into the bufferc consumer threads, each consuming m items from the bufferFor the test program to terminate, the total number of consumed items (c*m)
must equal the total number of items produced (p*n). Run the stress test.
./bin/bounded_buffer_stress_testThe default stress test will now be exuded. On success you should see output similar to the following.
Test buffer of size 10 with:
20 producers, each producing 10000 items.
20 consumers, each consuming 10000 items.
Verbose: false
The buffer when the test ends.
---- Bounded Buffer ----
size: 10
in: 0
out: 0
array[0]: (7, 9994)
array[1]: (15, 9999)
array[2]: (13, 9998)
array[3]: (4, 9999)
array[4]: (7, 9995)
array[5]: (13, 9999)
array[6]: (7, 9996)
array[7]: (7, 9997)
array[8]: (7, 9998)
array[9]: (7, 9999)
---------------------draft: false
---
====> TEST SUCCESS <====Note the ====> TEST SUCCESS <==== at the end.
The default values for test parameters can be overridden using the following flags.
| Flag | Description | Argument |
|---|---|---|
| -s | Size of the buffer | positive integer |
| -p | Number of producer threads | positive integer |
| -n | Number of items produced by each producer | positive integer |
| -c | Number of consumer threads | positive integer |
| -m | Number of items consumed by each consumer | positive integer |
| -v | Turns on verbose output | no argument |
In the following example, the default buffer size 10 is changed to 3.
./bin/bounded_buffer_stress_test -s 3Experiment with different values for the test parameters.
Here are a few examples of questions that you should be able to answer, discuss and relate to the source code of you solution during the code grading.
array and the in and out array indexes.array and the in and out array indexes.A thread library provides programmers with an API for creating and managing threads. Support for threads must be provided either at the user level or by the kernel.

Kernel level threads are supported and managed directly by the operating system.
Advantages
Disadvantages
User level threads are supported above the kernel in user space and are managed without kernel support.
Advantages
Disadvantages
In general, user-level threads can be implemented using one of four models.
All models maps user-level threads to kernel-level threads. A kernel thread is similar to a process in a non-threaded (single-threaded) system. The kernel thread is the unit of execution that is scheduled by the kernel to execute on the CPU. The term virtual processor is often used instead of kernel thread.
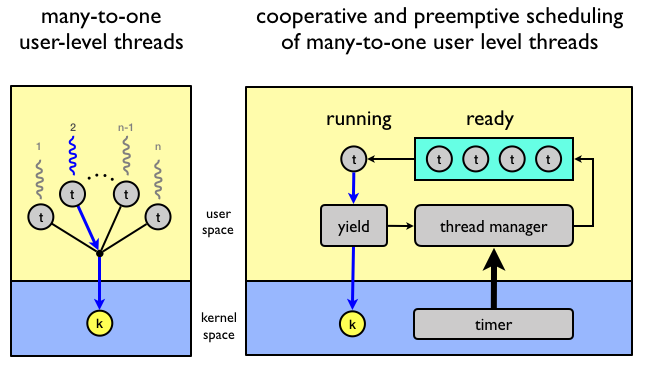
In the many-to-one model all user level threads execute on the same kernel thread. The process can only run one user-level thread at a time because there is only one kernel-level thread associated with the process.
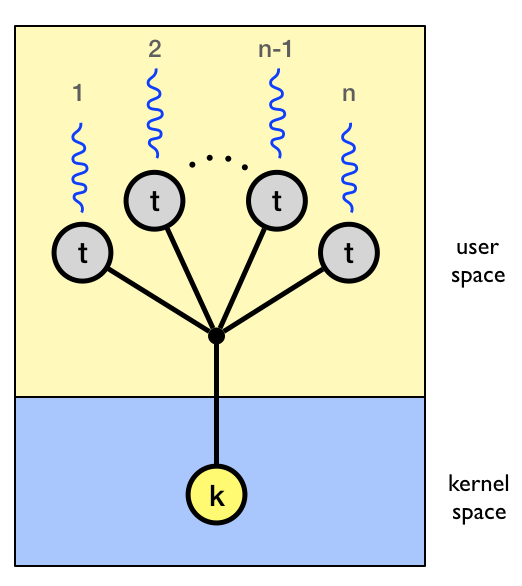
The kernel has no knowledge of user-level threads. From its perspective, a process is an opaque black box that occasionally makes system calls.
In the one-to-one model every user-level thread execute on a separate kernel-level thread.
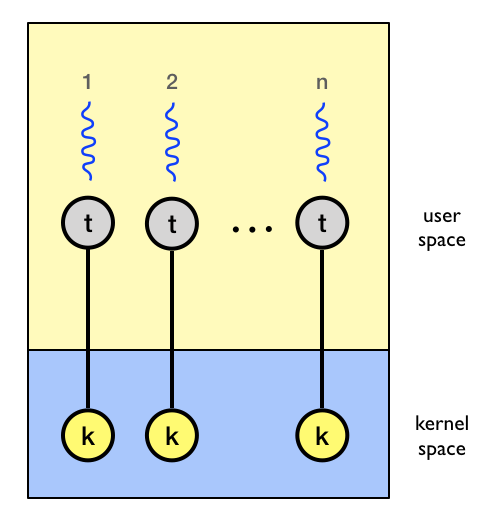
In this model the kernel must provide a system call for creating a new kernel thread.
In the many-to-many model the process is allocated m number of kernel-level threads to execute n number of user-level thread.
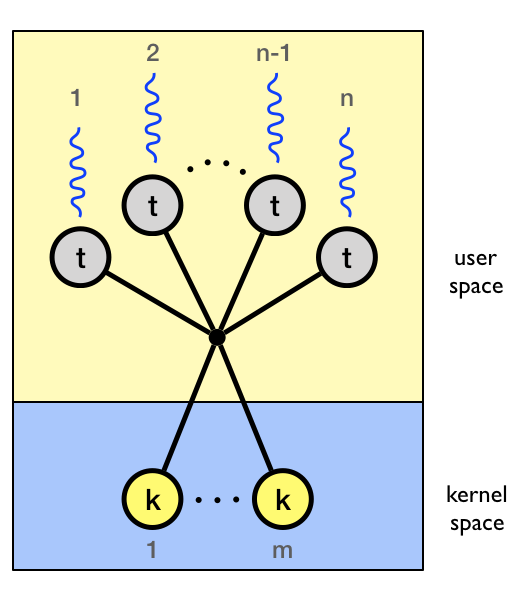
The two-level model is similar to the many-to-many model but also allows for certain user-level threads to be bound to a single kernel-level thread.
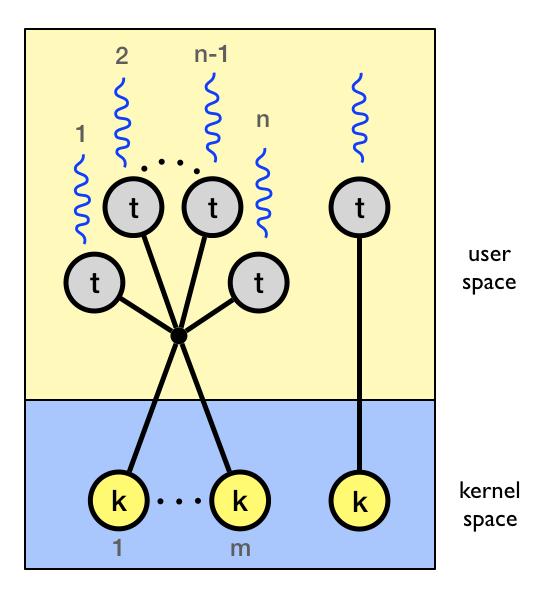
In both the many-to-many model and the two-level model there must be some way for the kernel to communicate with the user level thread manager to maintain an appropriate number of kernel threads allocated to the process. This mechanism is called scheduler activations.
The kernel provides the application with a set of kernel threads (virtual processors), and then the application has complete control over what threads to run on each of the kernel threads (virtual processors). The number of kernel threads (virtual processors) in the set is controlled by the kernel, in response to the competing demands of different processes in the system.1
The kernel notify the user-level thread manager of important kernel events using upcalls from the kernel to the user-level thread manager. Examples of such events includes a thread making a blocking system call and the kernel allocating a new kernel thread to the process.1
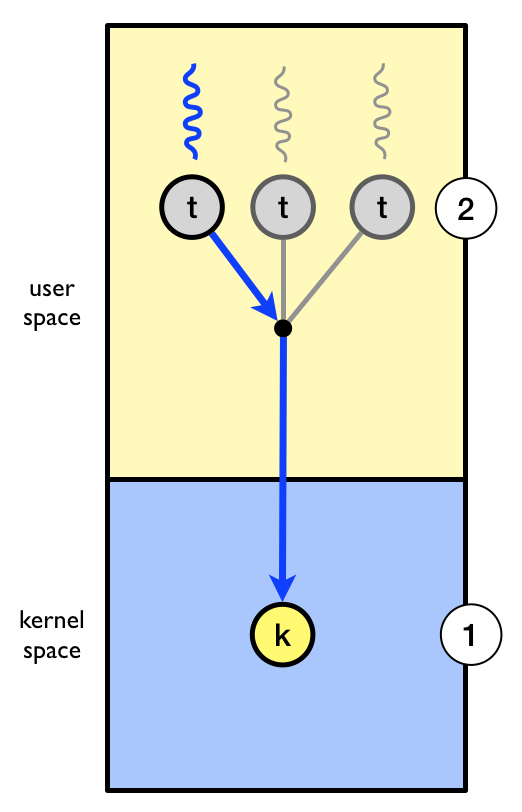
Let’s study an example of how scheduler activations can be used. The kernel has allocated one kernel thread (1) to a process with three user-level threads (2). The three user level threads take turn executing on the single kernel-level thread.
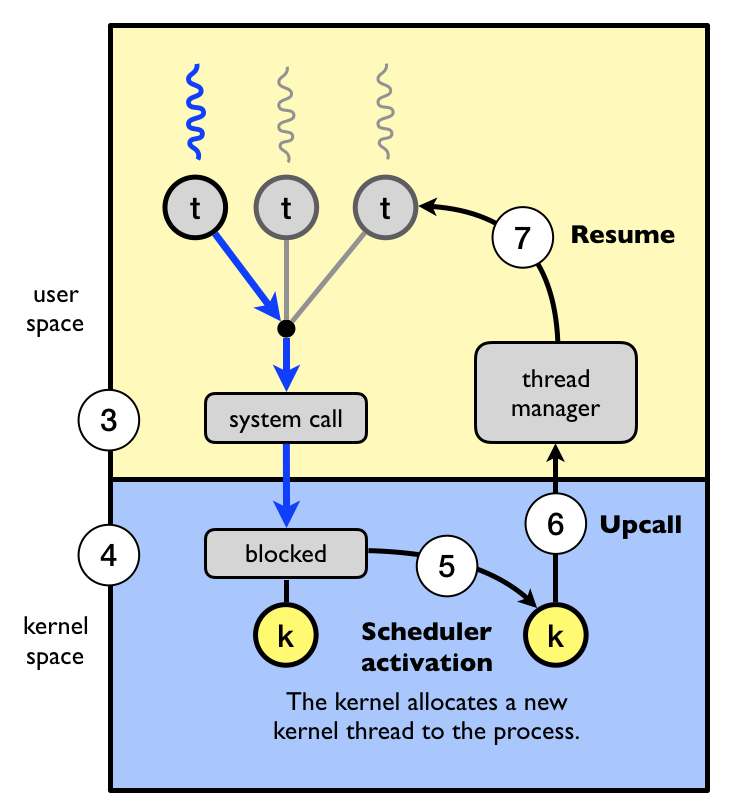
The executing thread makes a blocking system call (3) and the the kernel blocks the calling user-level thread and the kernel-level thread used to execute the user-level thread (4). Scheduler activation: the kernel decides to allocate a new kernel-level thread to the process (5). Upcall: the kernel notifies the user-level thread manager which user-level thread that is now blocked and that a new kernel-level thread is available (6). The user-level thread manager move the other threads to the new kernel thread and resumes one of the ready threads (7).
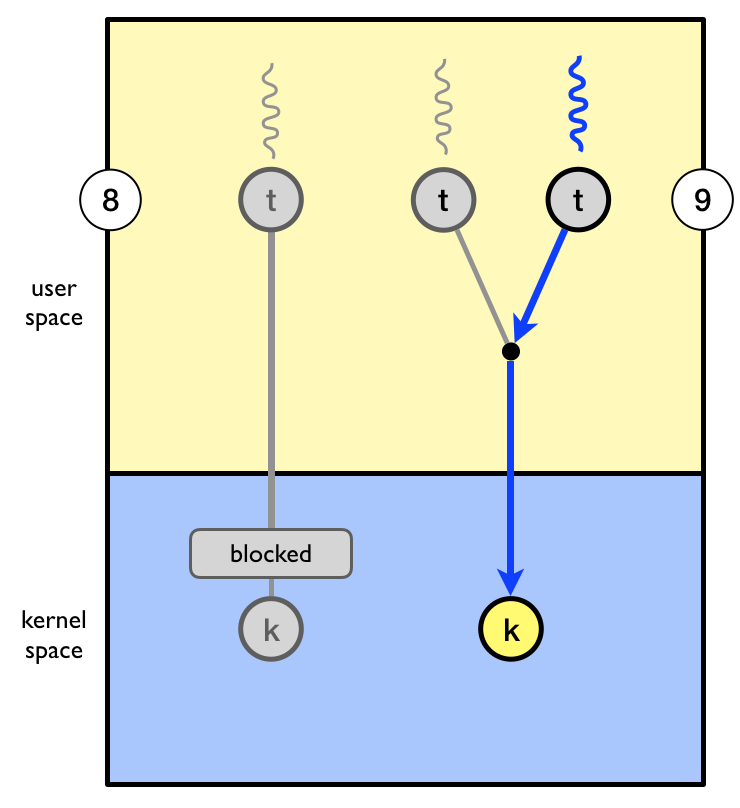
While one user-level thread is blocked (8) the other threads can take turn executing on the new kernel thread (9).
Scheduling of the usea-level threads among the available kernel-level threads is done by a thread scheduler implemented in user space. There are two main methods: cooperative and preemptive thread scheduling.
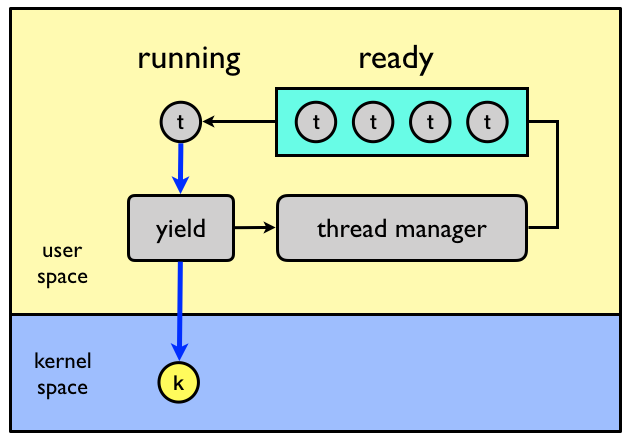
The cooperative model is similar to multiprogramming where a process executes on the CPU until making a I/O request. Cooperative user-level threads execute on the assigned kernel-level thread until they voluntarily give back the kernel thread to the thread manager.
In the cooperative model, threads yield to each other, either explicitly (e.g., by
calling a yield() provided by the user-level thread library) or implicitly (e.g., requesting a
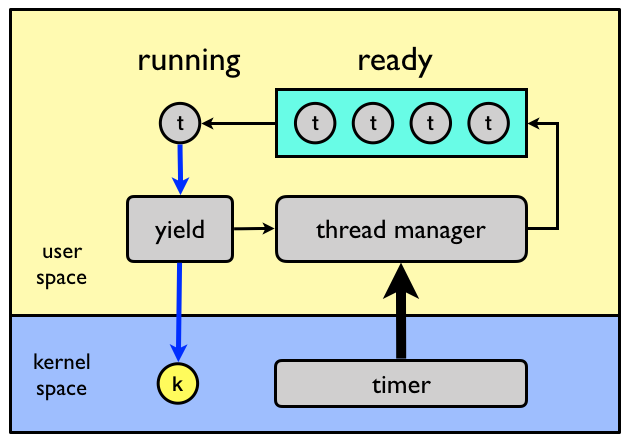
lock held by another thread). In the below figure a many-to-one system with
cooperative user-level threads is shown.
The preemptive model is similar to multitasking (aka time sharing). Multitasking is a logical extension of multiprogramming where a timer is set to cause an interrupt at a regular time interval and the running process is replaced if the job requests I/O or if the job is interrupted by the timer. This way, the running job is given a time slice of execution than cannot be exceeded.
In the preemptive model, a timer is used to cause execution flow to jump to a central dispatcher thread, which chooses the next thread to run. In the below figure a many-to-one system with preemptive user-level threads is shown.
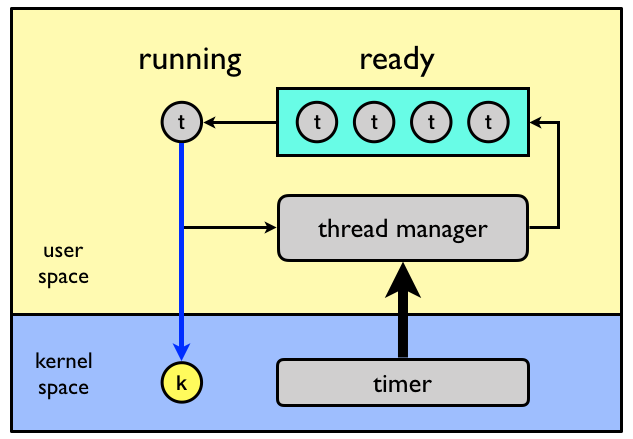
A hybrid model between cooperative and preemptive scheduling is also possible
where a running thread may yield() or preempted by a timer.
In this assignment you will implement a simplified version of many-to-one user level threads in form of a library that we give the name Simple Threads.
Before you continue make sure you’ve read the implementing threads page. Among the slides in Studium you also find self study material about implementing threads.
You should already have cloned the threads-and-synchronization repository.
The ucontext.h header file defines the ucontext_t type as a structure that
can be used to store the execution context of a user-level thread in user space.
The same header file also defines a small set of functions used to manipulate
execution contexts. Read the following manual pages.
In examples/src/contexts.c you find an example program demonstrating
how to create and manipulate execution contexts.
Study the source. To compile, navigate to the examples directory in the terminal, type make
and press enter.
makeTo run:
./bin/contextsIn higher-grade/src you find the following files.
Study the source and pay attention to all comments.
In the terminal, navigate to the higher-grade directory. Use make to
compile.
makeRun the test program.
./bin/sthreads_testThe program prints the following to terminal and terminates.
==== Test program for the Simple Threads API ====For grade 2 points you must implement all the functions in the Simple Threads API
except done() and join. This includes cooperative scheduling where
threads yield() control back to the thread manager.
The test program’s main() thread and all threads
created by main() share a single
kernel-level thread. The threads must call yield() to pass control to the thread
manager. When
calling yield() one of the ready threads is selected to execute and changes
state from ready to running. The thread calling yield() changes state from
running to ready.
For grade 4 you may assume the main thread and all other threads are non-terminating loops.
For 3 points, you must also implement the done() and join() functions in the
Simple Threads API. In addition to cooperative scheduling with yield() you must also implement
preemptive scheduling.
If a thread doesn’t call yield() within its time slice it will be preempted
and one of the threads in the ready queue will be resumed. The preempted thread
changes state from running to ready. The resumed thread changes state from ready
to running.
To implement preemptive scheduling you need to set a timer. When the timer expires the kernel will send a signal to the process. You must register a signal handler for the timer signal. In the signal handler you must figure out a way to suspend the running thread and resume one of the threads in the ready queue.
In examples/src/timer.c you find an example of how to set a timer.
When the timer expires the kernel sends a signal to the process. A signal
handler is used to catch the timer signal.