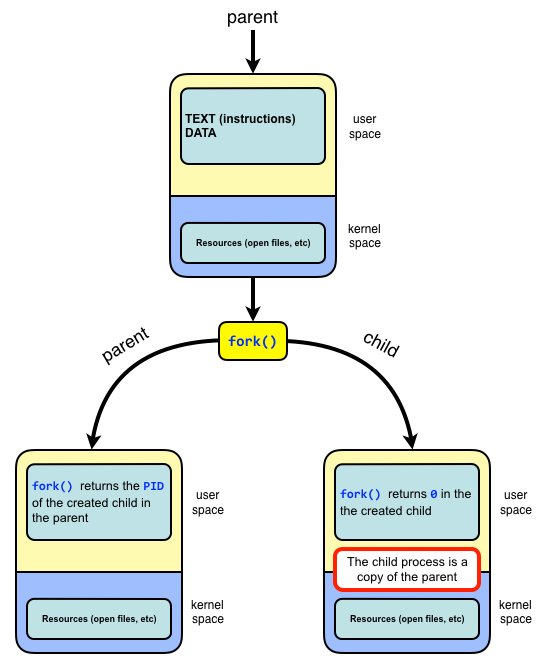
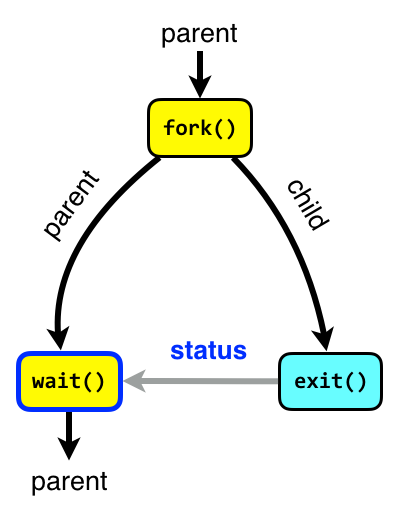
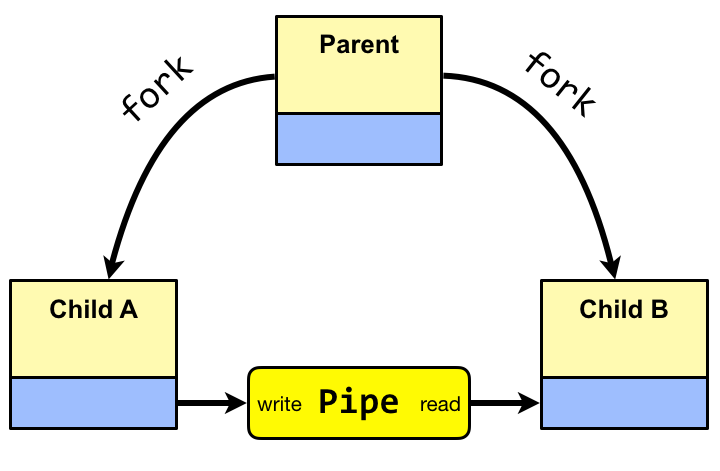
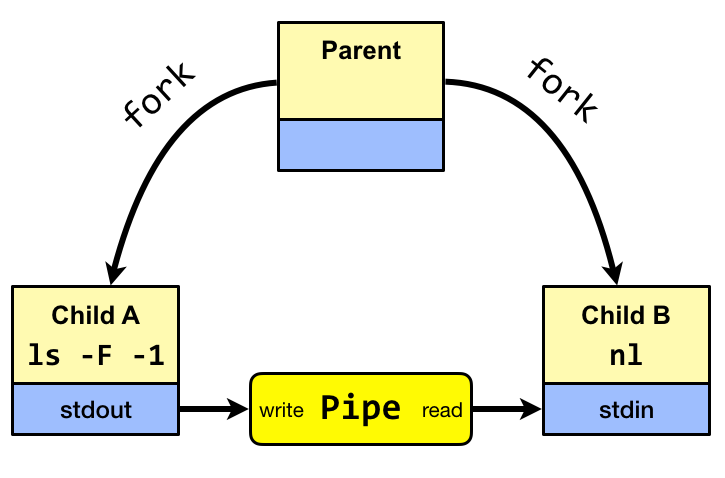
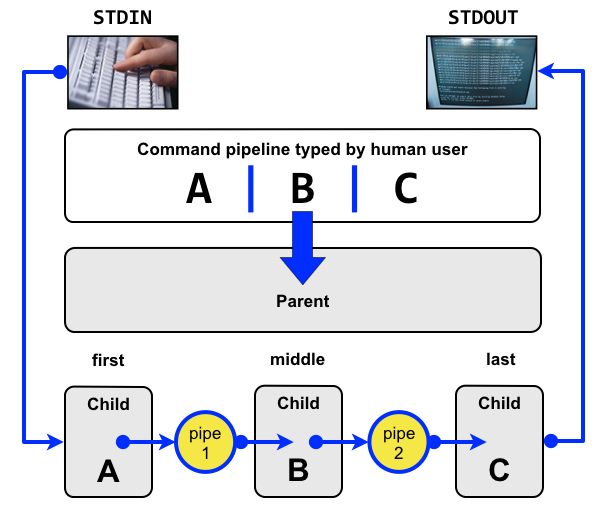
Our studies will be based on principles of the Unix and
Linux operating systems.
For all assignments, you will use Git to clone provided source code from repositories on GitHub.
Mips assembly will be used to study the fundamental principles of how
the operating system interacts with the hardware. To edit and execute Mips assembly programs we will use Mars (Mips
Assembler and Runtime Simulator).
Make will be used to compile all C programming assignments.
Unix
Unix is a family of multitasking,
multiuser computer operating systems that derive from the original AT&T Unix,
developed in the 1970s at the Bell Labs research center by Ken Thompson, Dennis
Ritchie, and others1.
Linux
Linux is a name which broadly denotes a
family of free and open-source software operating system distributions built
around the Linux kernel. The defining component of a Linux distribution is the
Linux kernel, an operating system kernel first released on September 17,
1991 by Linus Torvalds2.
Linux is a Unix-like and
mostly POSIX-compliant computer operating
system2. As of May 2015 it is estimated that 96.55% of all web servers
runs Linux 3.
The basic principles of Unix and Linux
Unix has a very long history both in industry and academia. Compared to
proprietary operating systems such as Microsoft
Windows and
macOSX detailed information about the
design and implementation of Unix and Linux is much easier to find. As a
consequence, Unix/Linux is well suited when studying and learning the core
principles of operating systems.
In the the operating systems courses at Uppsala University both Unix and Linux
will be used to introduce the basic principles of operating systems.
Toolbar
At the top of each page you find the toolbar with the following buttons.
This button will only appear if the main menu to the left is hidden. Press this button to show
the main menu.
View the table of contents menu for the page.
Show printer friendly version of the current page and all its subpages.
Suggest edits of the page by making a pull request on GitHub.
Navigate to the next page in the hierarchy.
Navigate to the previous page in the hierarchy.
Main menu
To the left of each page you find the main menu. If the main menu is hidden, press the icon in the toolbar at the top of the page. The following
symbols are used in the main menu.
Instructions on how to download source code from GitHub.
Mandatory assignment.
Optional assignment for higher grade.
At the bottom of the main menu you find these two buttons.
Switch between viewing the website in dark mode or light mode.
Clear the markings of the pages
you have visited.
Shell commands and code snippets
Shell commands to be entered in the terminal are shown in boxes like this.
make # Run make to compile
If you hover over a shell command box, a copy button will appear
in the upper right corner. Press this button to copy the shell command in the box. Now you
can paste the copied command at the shell prompt in your terminal and press
enter to execute the command.
Code snippets are also shown in boxes. For example like this.
int a =127; // A global variable.
intmain(void) {
int b =42; // A local variable.
}
If you hover over a code snippet box, a copy button will appear in the upper
right corner of the box. Press this button to copy the context of the box. Now
you can paste the code snippet in your code editor.
Mars will run on any system (including Windows) as long as you have Java
installed. If you prefer, you may download and
install Mars on your private computer.
You will not be able to access the graphical desktop environment.
But, you can start graphical applications from the command line (shell) if you use X
forwarding together with SSH.
SSH with X forwarding on Linux, macOS and Windows
Read more here about how to install SSH with X forwarding support on your
system.
In the below example, a user with user name abcd1234 uses the ssh command
with the -X option to enable X forwarding to log in to the department Linux
server trygger.it.uu.se.
ssh -X abcd1234@trygger.it.uu.se
One you are logged in, you can start graphical applications from the Linux
shell. You can for example run Mars.
mars
To edit C source code you can for example use the VS Code source code
editor remotely.
code
Linux inside Windows
If you are using Windows and don’t like working remotely with the Deparment
Linux system, nor do you want to install Linux alongside Windows on
your computer (dual boot), consider one of the following options.
Install VirtualBox and run a virtual Linux machine. This tutorial will cover how to install
VirtualBox and set up your first virtual machine, show you how to get Ubuntu and
prepare for installation, and walk you through an installation of Ubuntu.
Prerequisites
To prepare for the tutorials and programming assignments you should make sure to go through the material in this section.
Subsections of Prerequisites
Microsoft 365 Education
As a student at Uppsala University you have a Microsoft 365 Education account.
Microsoft 365 Eduction is a collection of tools and services for students. Examples of what is included in Microsoft 365 Education.
Microsoft Office Desktop for your computer.
Works with Windows and Mac.
Includes, but is not limited to Word, Excel, Outlook and Powerpoint.
Email, calendar and address book.
OneDrive up to 100 GB storage.
Activate multi-factor authentication (MFA)
To get access to Microsoft 365 Education you must first activate multi-factor
authentication (MFA).
After you activated MFA you can read more here to get started with Microsoft 365
Education.
Windows
In all computer rooms on campus Ångströmslaboratoriet you find computers with
Windows.
Log in
If the computer is on, the power button lights up in the bottom right corner of the screen. Wake up the computer
by moving the mouse or pressing any of the keys on the keyboard.
If the power button is not lit, you need to press the power button to
to turn on the computer.
To log in to Windows, enter the username of your
student account in the form abcd1234 and Password A.
It may take a little while to log in, but after a while the desktop will
appear.
Local files
Files you store on the university’s computers are stored locally on the very
computer you are logged on to. If you store a file on computer A, you will not
be able to access it from computer B. It is also not guaranteed that a file you
store locally on computer A will still be there the next time you log on to
computer A.
File explorer
Among the icons in the taskbar you find the file explorer.
When you click on the file explorer icon, a new window opens.
In the file explorer you can se all local files and folders.
Log out
At the bottom of the desktop you find the taskbar.
To log out, cllick on Windows symbol (1) in the taskbar.
Click on your name (2).
Click on Sign out (3).
OneDrive
Instead of storing your files locally on one of the university’s
computers, you should always use OneDrive. With OneDrive you can store
your files in one place, share them with others and access them from any device
connected to the Internet.
With OneDrive you can work on one of the university’s computers, save a file in
OneDrive and later access the file in OneDrive from your private computer.
File explorer
Among the icons in the taskbar you find the file explorer.
When you click on the file explorer icon, a new window opens.
Activate OneDrive
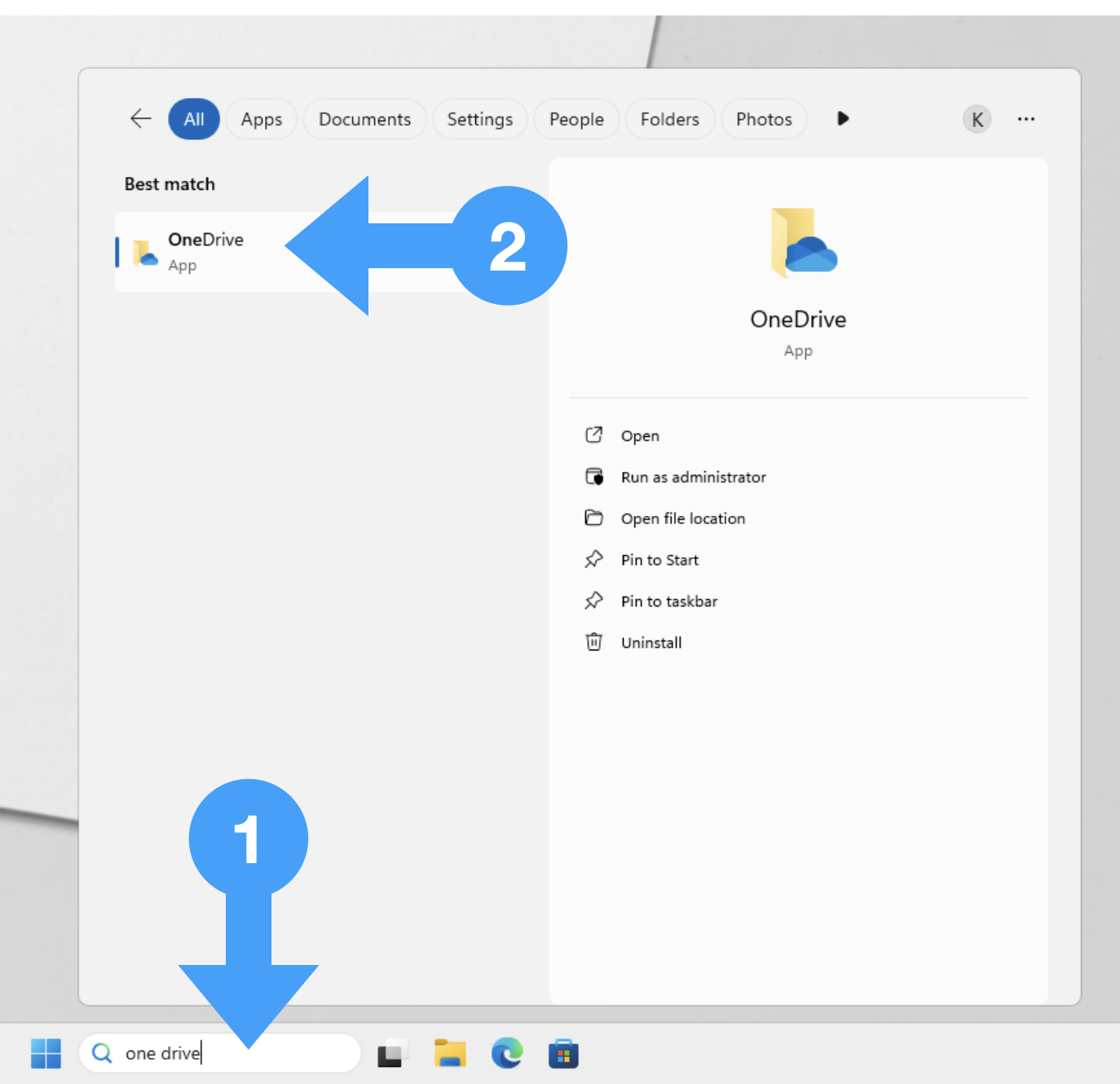
If you find OneDrive in the File explorer, click on OneDrive.
If you don’t find OneDrive in the File explorer, search for One Drive in the taskbar (1) and click on OneDrive App (2).
You must now provide your email address on the form
firstname.lastname.1234@student.uu.se.
Next, press Sign in. Before you can use OneDrive, you must sign in with your Student account and
MFA on your mobile phone.
When you log in for the first time, the following window appears.
You can press Next a few times to learn more about OneDrive or you can
simply close this window.
Try to use OneDrive
Press the Windows key and search for Notepad to launch this program and
enter some text.
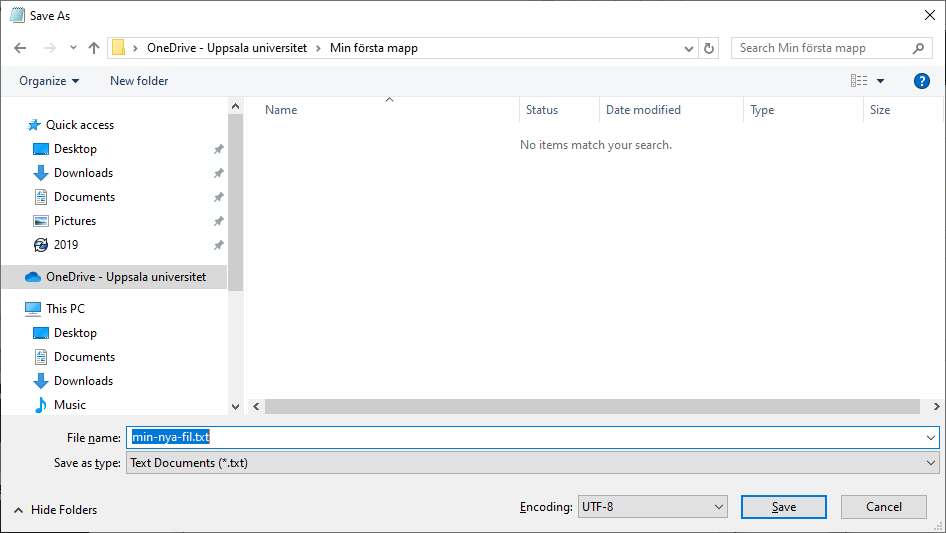
In the meny, click on File and then Save As….
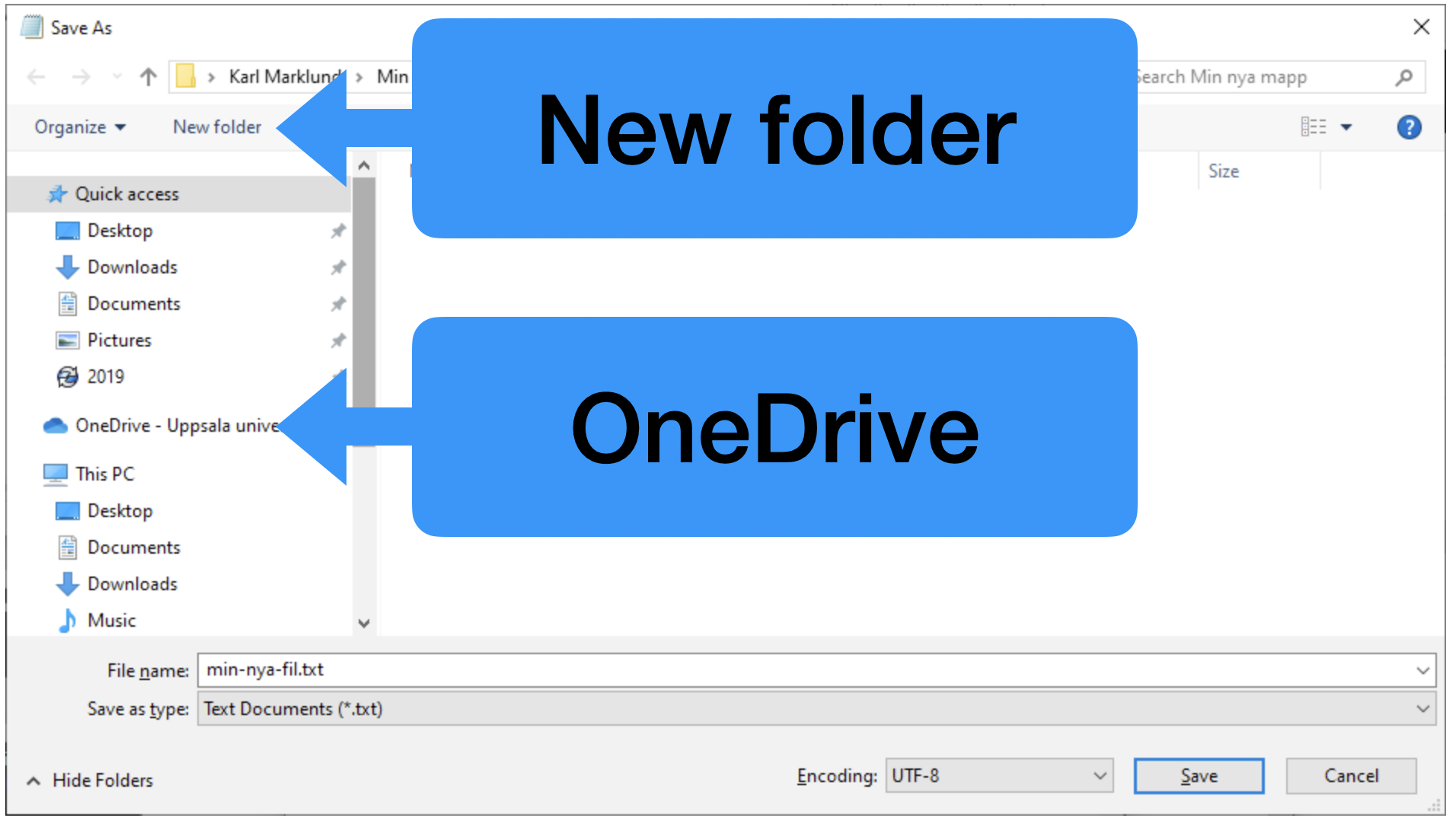
Now the File explorer opens. First click on OneDrive and then on New
folder to create a new folder in OneDrive.
Give the new folder a name, for example My First Folder. In the field File
name, enter the name of the new file, for example my-new-file.txt.
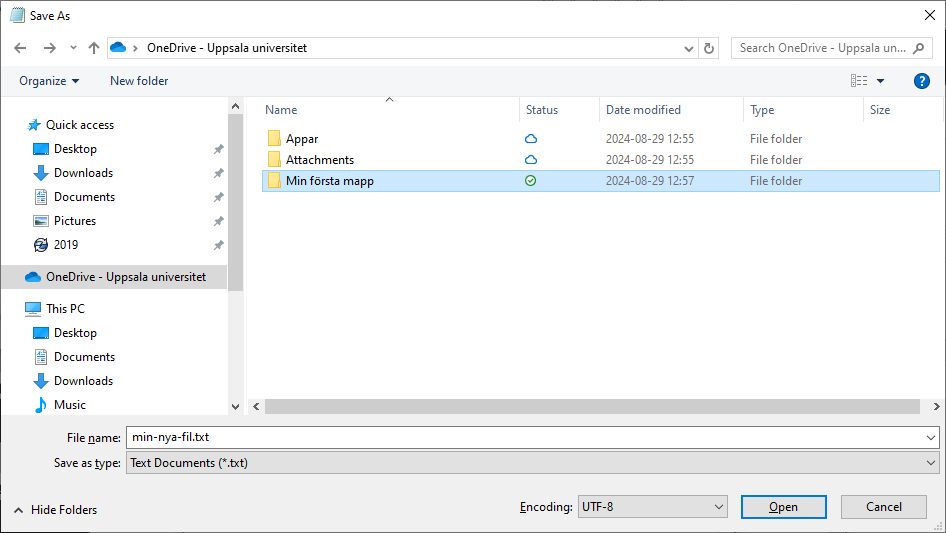
Click on Open.
Click on Save. You have now saved the file in the new folder in OneDrive.
The new file is now stored in the My First Folder folder in OneDrive and you
can access it via OneDrive on any computer connected to the internet, for
example your private Windows computer.
OneDrive on your platform
If you are using Windows 10 or Windows 11, OneDrive is already installed. OneDrive is not only available on computers with Windows. You can also download OneDrive for macOS,
iOS and Android.
Access OneDrive in the web browser
An alternative to activate OneDrive in the file explorer on a computer with Windows is to access OneDrive directly in a web browser by signing in to OneDrive here.
Here you find information on how to log in to the University’s Linux system
from one of the computer rooms for students on Campus Ångströmlaboratoriet.
Windows in all computer rooms
In all computer rooms on campus Ångstrumslaboratoriet you find computers with
Windows.
ThinLinc
On campus Ångströmlaboratoiet there are a number of large computers (servers) running
Linux somewhere in a basement. As a student, you will never physically interact
with these server computers. Instead, you log in to these servers from Windows
to get access to the Linux desktop environment on the same screen as Windows. The system used
for this is called ThinLinc.
Access Linux from Windows
To access the Linux system, you must first log into Windows and from
Windows use ThinLinc Client to log in to a Linux server.
Log in to Windows
Log in to Windows with your student account on
the form abcd1234 and Password A.
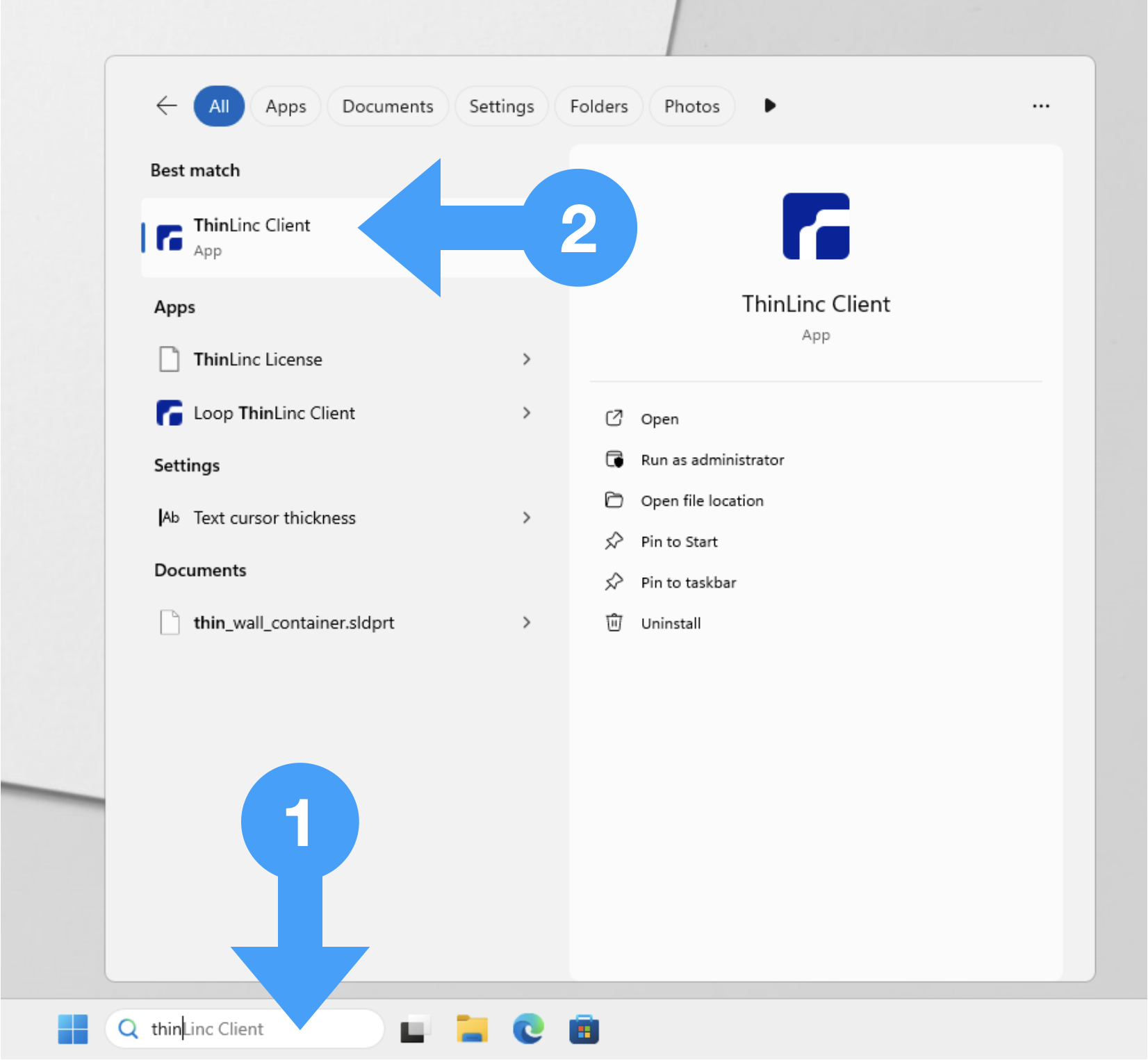
Start the ThinLinc Client
Search for ThinLinc in the taskbar (1).
Klick och ThinLinc Client (2).
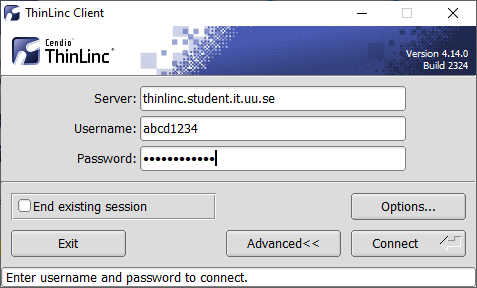
Log in to Linux with the ThinLinc Client
Click on the ThinLinc Client icon in the taskbar to log in to the Linux
system. Enter the following login information.
Server:thinlinc.student.it.uu.se.
Username: Your student account username on the form abcd1234.
Password: Your Password A.
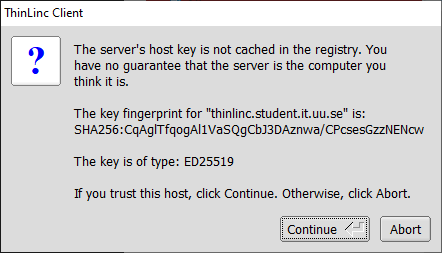
Click Connect to login. The first time you log in, you may see
the following message.
If you see the above message, click on Continue.
The Linux desktop
After a successful login, new window will open with the Linux desktop environment.
You can maximize or resize this window, just like for any other window in
Windows. Thus, in the Linux desktop window in Windows you interact with the
Linux system that is actually running on a remote server.
From the Applicatinos menu at the top left of the desktop: Applications → Accessories → Terminal.
By pressing the keyboard shorcut CTRL + ALT + T .
After a few seconds a new terminal window should open.
In the upper left corner of the white area of the terminal window you see
abcd1234@arrhenius:~$ . This it the shell prompt with your username on the form
abcd1234 and the name of the Linux server you are
connected to, in this example arrhenius. The shell prompt you see might be
different.
The shell prompt
In the above example, the prompt shows the username of the logged in user abcd1234
together with the name of the physical Linux server arrhenius used. You should
see your own user name. If you are logged into a different physical Linux server
you will also see a different server name in the prompt.
It is also possible to tweak the prompt to show custom
information such as your username, local time etc.
No shell prompt in instructions
Since the appearance of the shell prompt might vary, in all further instructions
the shell prompt will be omitted and commands you enter att the shell prompt will be
presented in a box like this.
ls -F # Example shell command
If you hover over the box above, a copy button will appear
in the upper right corner. Press this button to copy the text in the box. Now you
can paste the copied command at the shell prompt in your terminal and press
enter to execute the command.
Log out from the Linux system
There are two options for logging out from the Linux system. To log out of Linux you can:
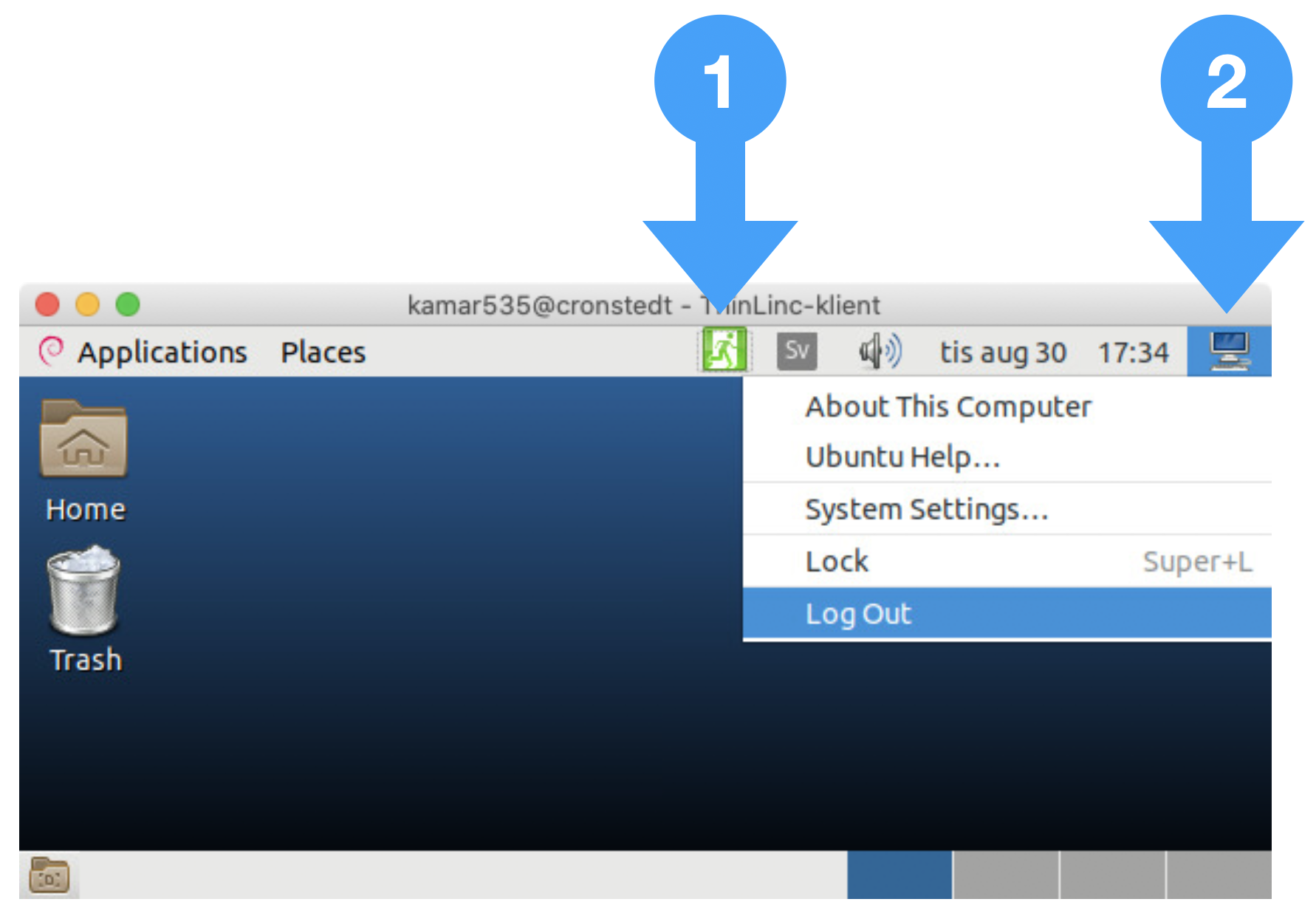
Click on the icon with a person walking through a door at the top.
Click on the icon with a computer at the top right and then select Log Out
to log out.
After you log out, the Linux window closes. If you logged out by mistake
you must restart the ThinLinc Client and
login again to continue working with Linux.
Remote login to the department Linux system with SSH
You can access the [department Linux System ][dep-linux] remotely using
SSH to login to one of the student servers.
You will not be able to access the graphical desktop environment.
But, you can start graphical applications from the command line (shell) if you use X
forwarding together with SSH.
SSH with X forwarding on Linux, macOS and Windows
Read more here about how to install SSH with X forwarding support on your
system.
In the below example, a user with user name abcd1234 uses the ssh command
with the -X option to enable X forwarding to log in to the department Linux
server trygger.it.uu.se.
ssh -X abcd1234@trygger.it.uu.se
One you are logged in, you can start graphical applications from the Linux
shell. You can for example run Mars.
mars
To edit C source code you can for example use the VS Code source code
editor remotely.
A shell is a user interface for access to an operating system’s services. Most
often the user interacts with the shell using a
command-line interface (CLI). The terminal is a program that opens a graphical window and lets you interact
with the shell.
Background
Originally, a computer terminal was an electronic or electromechanical hardware
device used for entering data into, and displaying data from, a computer or a
computing system. The terminal of the first working programmable, fully
automatic digital Turing-complete computer, the Z3 (1941), had a keyboard and a
row of lamps to show results.1
Early computers where huge machines taking up a lot of space. Commonly a system
consisted of multiple cabinets, for example one cabinet for the main processor
unit, one or more cabinets for tape drives, one cabinet for each disk drive, one
cabinet for a punched card reader and one cabinet for a high speed printer. In the
below image, a Univac 9400 system (1967) consisting of multiple cabinets is
shown.
A Univac 9400 mainframe computer data center on display in the Techikum29 museum. Photographby technikum29.
Teletypewriter (TTY)
Early user terminals connected to computers were electromechanical
teleprinters or teletypewriters (TeleTYpewriter, TTY). In the above image of the
Univac 9400 system, the cabinet marked UNICAC 9400 is the main
processor cabinet. The terminal is the machine looking like a huge typewriter
placed on the desk to the left of the main processor cabinet. Another example of an early terminal is
the Teletype Model 33 ASR (1963) shown below.
A model 33 ASR terminal from the Teletype Corporation on display at the Computer History Museum, Mountain View, California, USA. Photographby Arnold Reinhold.
Video display terminal
As technology improved, teleprinter terminals was replaced by video display
terminals. One example of such a video display terminal is the DEC VT100 (1978)
shown below.
Note that the DEC VT100 terminal shown above is not a computer. The DEC
VT100 terminal was
only used for input and output to and from a connected computer. In the below image DEC VT52 video terminal (1974) is connected to a PDP 11/55 computer (1975).
A terminal emulator is a program that emulates a video terminal within some
other display architecture.2 Today, the term terminal is
often used synonymously with a terminal emulator running a shell.
On this page you find a small collection of useful shell commands when working
in the terminal. You will also learn about shell variables, the command
history and how to read manual pages in the terminal.
Your username (whoami)
Every user on the Linux system has a unique username. The whoami command will show your username.
Type whoami at the shell prompt.
whoami
Press enter to execute the command. Now the result will be printed on the next
line in the terminal and a new shell prompt will appear on the line after that.
abcd1234
In the above example the username of the logged in user abcd234 is printed as
the result of the whoami command.
Username
In all examples and instructions you should replace abcd1234 with your actual username.
Print working directory (pwd)
The shell has a concept of a current working directory. The pwd (print working
directory) command prints the full path of the current working directory.
Type pwd at the shell prompt.
pwd
Press enter to execute the command.
/home/abcd1234
In the above example the current working directory /home/abcd1234 is printed
as the result of the pwd command.
Home directory
On the Linux system each user has a private home directory to where she/he
can save files and create sub directories.
When you first log in to the Linux system the home directory will be used as the
current working directory in the shell.
For user abcd1234 the full path to the home directory is /home/abcd1234.
List files and directories (ls)
To list the files and directories in the current working directory the ls command can be used. The name ls is a short form of list (files).
Type ls at the shell prompt.
ls
Press enter to execute the ls command. You should see something similar to the
below as result but you might see other files and folders listed.
foo.txt Desktop public_html
In the above example the only content in the current working directory is the
text file foo.txt and two sub directories Desktop and public_html. You may see
many more directories and files.
Distinguish between files and folders (ls -F)
To get some more information about files and folder various options can be given
to the ls command. One useful option is -F that marks directories
with a trailing slash /.
ls -F
You should now see something similar to this.
foo.txt Desktop/ public_html/
Visualize a directory as a tree
The tree command displays the contents of the current directory and
subdirectories as a tree structure.
tree
The output takes a graphical form which will resemble the following example:
In the above example, there are three files (README.md, one.txt and
two.txt) and one sub directory (sub) in the current working directory. In
the sub directory sub there is a single file three.txt.
You can provide tree with the path to a directory to visualize its content.
tree sub
Now, only subtree of the sub directory is shown.
sub/
└── three.txt
0 directories, 1 file
Install tree on macOS
If you run macOS and tree is not installed, use Homebrew to install tree.
brew install tree
Change directory (cd)
The cd command navigates to a different folder. The name cd means change directory.
First print the current working directory.
pwd
This will show the path of the current working directory, for example.
/home/abcd1234
To navigate to the Desktop folder, type cd Desktop at the shell prompt and press
enter.
cd Desktop
Print the current working directory to confirm.
pwd
You should now see your absolute path to your Desktop directory.
/home/abcd1234/Desktop
Note how the current working directory changed from /home/abcd1234 to
/home/abcd1234/Desktop as the result of the cd Desktop command.
The directory above the current working directory can be referred to using ...
To navigate to the parent directory, type cd .. and press enter.
cd ..
Now, execute the pwd command again.
pwd
And, you are back in your home directory.
/home/abcd1234
Note how the current working directory changed back from /home/abcd1234/Desktop
to /home/abcd1234 as the result of the cd .. command.
Print content of file to the terminal (cat)
The cat command can be used to print the content of a file to the terminal.
Assume you have the following file named foo.txt in the current working directory.
The first line of the file.
The third line. The second line is empty.
The last line of the file.
You can now print the content of foo.txt to the terminal using the cat command.
cat foo.txt
Now, the content of the file foo.txt will be printed out in the terminal.
The first line of the file.
The third line. The second line is empty.
The last line of the file.
The name cat is a short form
of concatenate which means to
join together. If more than one argument is given to cat the contents of the
provided files will be joined together and printed to the terminal.
In the below example cat is used to concatenate the file foo.txt with itself.
cat foo.txt foo.txt
This will output the contents of the file foo.txt twice.
The first line of the file.
The third line. The second line is empty.
The last line of the file.
The first line of the file.
The third line. The second line is empty.
The last line of the file.
One useful option to the cat command is -n:
cat -n foo.txt
, which prefixes each line with a line number.
1 The first line of the file.
2
3 The third line. The second line is empty.
4 The last line of the file.
Count words, lines and bytes (wc)
The wc command counts the number of words, lines and bytes.
wc foo.txt
In this example the file foo.txt has four lines of text with a total of 20 words and 98 bytes.
4 20 98
In the above example we see that the file foo.txt contains for lines, 20 words and 98 bytes.
Filter (grep)
The grep command searches its input for a pattern and prints all lines in the
input that contains that pattern.
To search for the the string X in the input type grep X at the shell prompt
and press enter.
grep X
Note that we don’t get back the shell prompt. This is because the grep command is still running waiting for input.
The grep command will now read input from the terminal and print back all
lines containing the character X.
Now type Hello and press enter.
Hello
There is no X in the string Hello and therefore grep will not print back the string Hello to the terminal.
Type Hello mr X and press enter and watch what happens.
Hello mr X
Hello mr X
Once you type Hello mr X the grep command will print Hello mr X right back to
the terminal since it contains a matching X.
Lets try a few more lines and observe what happens.
abc
abcXdef
abcXdef
xxx
xXx
xXx
Only lines containing a matching X will be echoed back to the terminal.
No more input
To tell grep that you are done (no more input), press Ctrl D (press and hold
down the control key and while you still hold down the control key press the
D key).
Press Ctrl D. Now grep terminates and you get back to the shell prompt.
To filter the lines in a file, the name of the file can be given together with a search pattern to grep.
Assume you have the file foo.txt in your current directory. Using cat:
cat foo.txt
, prints the contents of the file to the terminal:
The first line of the file.
The third line. The second line is empty.
The last line of the file.
In the below example only lines containing of in the file foo.txt will be printed to the terminal.
grep of foo.txt
The above command will result in the following being printed to the terminal.
The first line of the file.
The last line of the file.
Filter the output of ls using grep (ls | grep)
The usefulness of grep might not obvious at this point. To make grep useful
we will combine grep with ls to filter the output of ls.
First we use ls to list all files and folders.
ls
foo.txt Desktop public_html
If we are only interested in files (and folders) with names ending in .txt we
can combine ls and grep to using the pipe character |.
ls | grep .txt
In this example, only the foo.txt files matches the .txt pattern.
foo.txt
In the above example, first the ls command executes but it does not print its
result back to the terminal. Instead, the result of the ls command becomes the
input to the grep command. The only file or folder name containing .txt is
foo.txt.
Piping commands together
Using the pipe character | the output of the command to the left becomes the
input to the command to the right. This is called piping the two commands
together.
Compressed file archives (tarballs)
It is often useful to compress multiple files and folders into a single file
that can later be decompressed and expanded to get back the original files and
folders. There exists many file formats for compressed file archives.
Windows users commonly use the zip file format.
Unix users commonly use the tar file format.
Tarball
The name tarball is often used to refer to a tar archive file.
Download the following gziped compressed tar archive (tarball) to your home folder:
Verify that you have the tarball in your current working directory
From the terminal, make sure you have the downloaded tarball in the current
working directory. If you have many files in the current working directory you can
use ls together with grep to search for files with names matching .tar.
ls | grep .tar
Hopefully you will see the downloaded tar ball in the result.
archive.tar.gz
In the above example the output of ls is piped together with grep to filter the
output of ls to only print any files (or folders) containing .tar. You
should see archive.tar.gz among the results.
Sneak peek inside a tarball (tar tf)
To see the contents of a tarball without extracting all the files you can use
tar with options t and f.
tar tf archive.tar.gz
In this example this is the content of the archive.tar.gz tar ball.
In the above example we see that the tarball archive.tar.gz contains the top
level directory archive with sub folder sub_folder. In the top level directory
archive there are two files (large.txt and small.txt) and in the sub folder
sub_folder there is a single file (small.txt).
Unpack a tarball (tar xvfz)
To unpack and extract the contents of a gzipped tarball we need to use the xvfz
options together with the tar command.
tar xvfz archive.tar.gz
Now the name of each directory/file that is extracted is printed to the terminal.
x archive/
x archive/large.txt
x archive/small.txt
x archive/sub_folder/
x archive/sub_folder/info.txt
Now the tarball have been unpacked. Use ls to see what happened to the current
working directory.
ls | grep archive
Now you should have both the tar ball archive.tar.gz and the extracted
archive in your working directory.
archive
archive.tar.gz
In the above example we now have a new directory named archive inside the
current working directory.
Use cd to “step inside” the archive directory.
cd archive
Next, use ls -F to list the content in this directory.
ls -F
This is the content of the archive folder.
large.txt
small.txt
sub_folder/
Using the -R option ls will be run recursively stepping inside every sub-directory.
ls -R
The contents of the archive folder viewed recursively.
In the result printed by ls -R a single period . means the current working
directory.
Print text back to the terminal (echo)
To print anything to the terminal simply type echo followed by the text you want
to print.
echo Hello
The text Hello now appears in the terminal.
Hello
Note that Hello is echoed back to the terminal as the result of executing the
echo Hello command before the shell prints the next command prompt.
Shell variables
The shell can set and read variables. Sometimes it is useful to use the value of
a built-in shell variable to make a command more generic and/or portable.
Remember that the command woami can be used to print your username.
whoami
In this example your username is abcd1234.
abcd1234
$USER
An alternative to woami is to use echo together with the shell variable
USER. In order for echo to know if you want to print the string "USER" or
the value of the shell variable USER shell variables must be prefixed with $
or enclosed within ${ }.
This:
echo Hello USER
, results in:
Hello USER
But this:
echo Hello $USER
, results in:
Hello abcd1234
And this:
echo Hello ${USER}
Results in:
Hello abcd1234
$HOME
Another useful shell variable is HOME with the full path to the home directory
for the logged in user. You can use echo to check the value of the HOME variable.
echo $HOME
In this example the result is:
/home/abcd1234
Command history
Often you type and run a command in the terminal and later you wants to run the
very same command again. To prevent you from having to type the same thing again
the shell keeps a history of executed command. To navigate the history, simply
press the up-arrow to move backwards in history and press the down-arrow to move
forward in history.
Try the following command in the terminal:
pwd
, resulting in:
/home/abcd1234
And now this command:
whoami
, resulting in:
abcd1234
If you want to repeat the whoami command, simply press the up-arrow key once.
Instead if you wish to run the pwd command again, press the up-arrow key twice.
Reading manual pages (man)
For more information about command you can always refer to the corresponding
built in manual page. For example, to read the manual page for the ls command
simply type man ls and press enter at the shell prompt.
man ls
This will print the manual one page at a time to the terminal. To view the next
page, press the space bar. To quit, press q.
To learn more about the build in manual pages read the manual page about the man
command.
man man
A summary of useful control keys when reading man pages.
Source code for all tutorials and assignments will be made available in
various repositories on GitHub. To
download source code you will use Git to clone repositories to your
Department Linux user account or to your private computer.
Check if you already have Git installed
Open a terminal, type git --version and press enter.
git --version
If git is installed you will something similar to this as a result in the
terminal.
git version 1.9.1
If git is not installed you will something similar to this as a result in the
terminal.
git: command not found
Install Git
If git is not installed on your system, install git by following
these
instructions.
Example GitHub repository
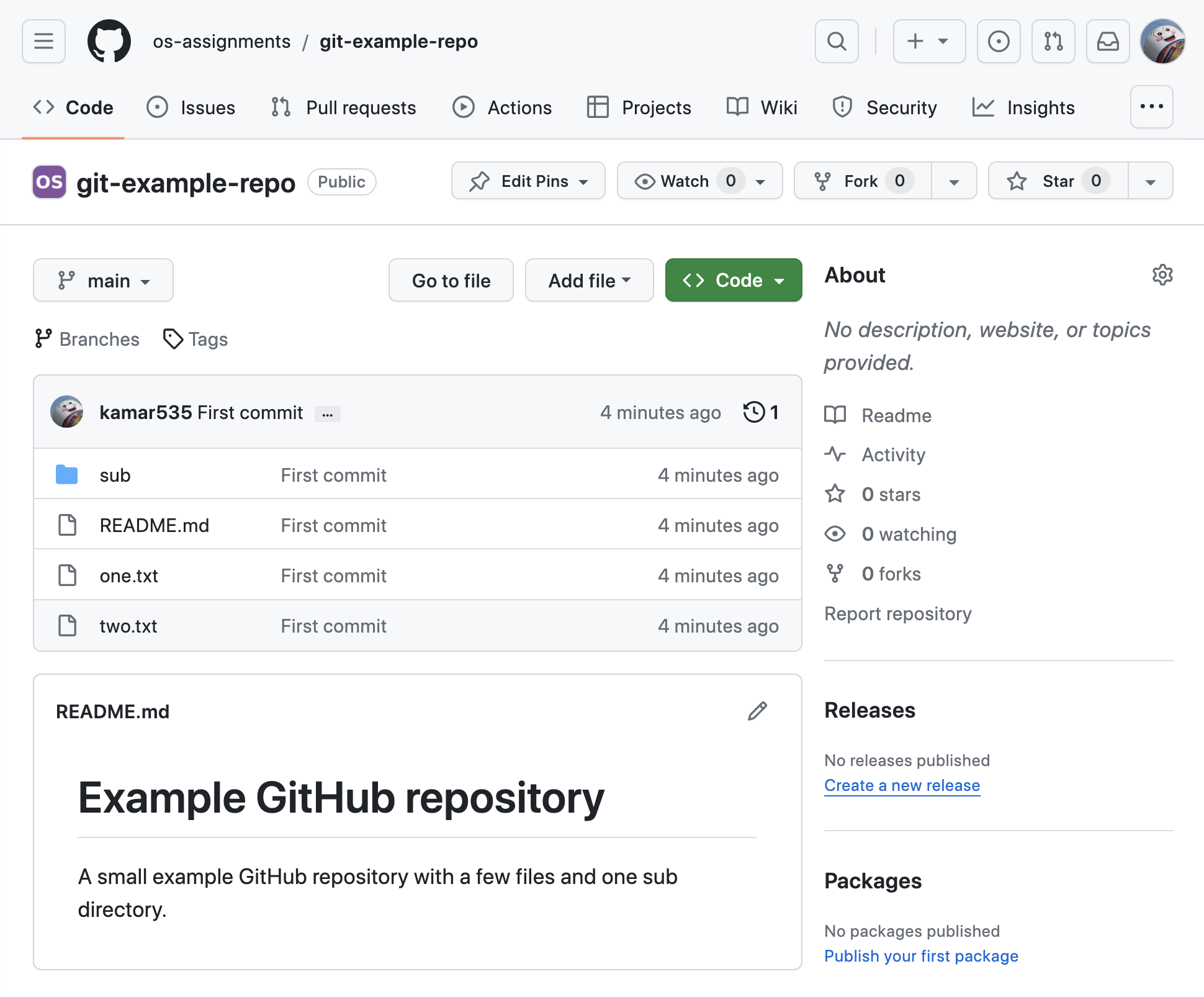
Let’s look at the following example GitHub repository.
The repository contains the folder sub and the files README.md, one.txt
and two.txt. The sub folder contains a single file named third.txt.
By clicking on a file, for example the one.txt file, you will see the content of the file.
A small text file.
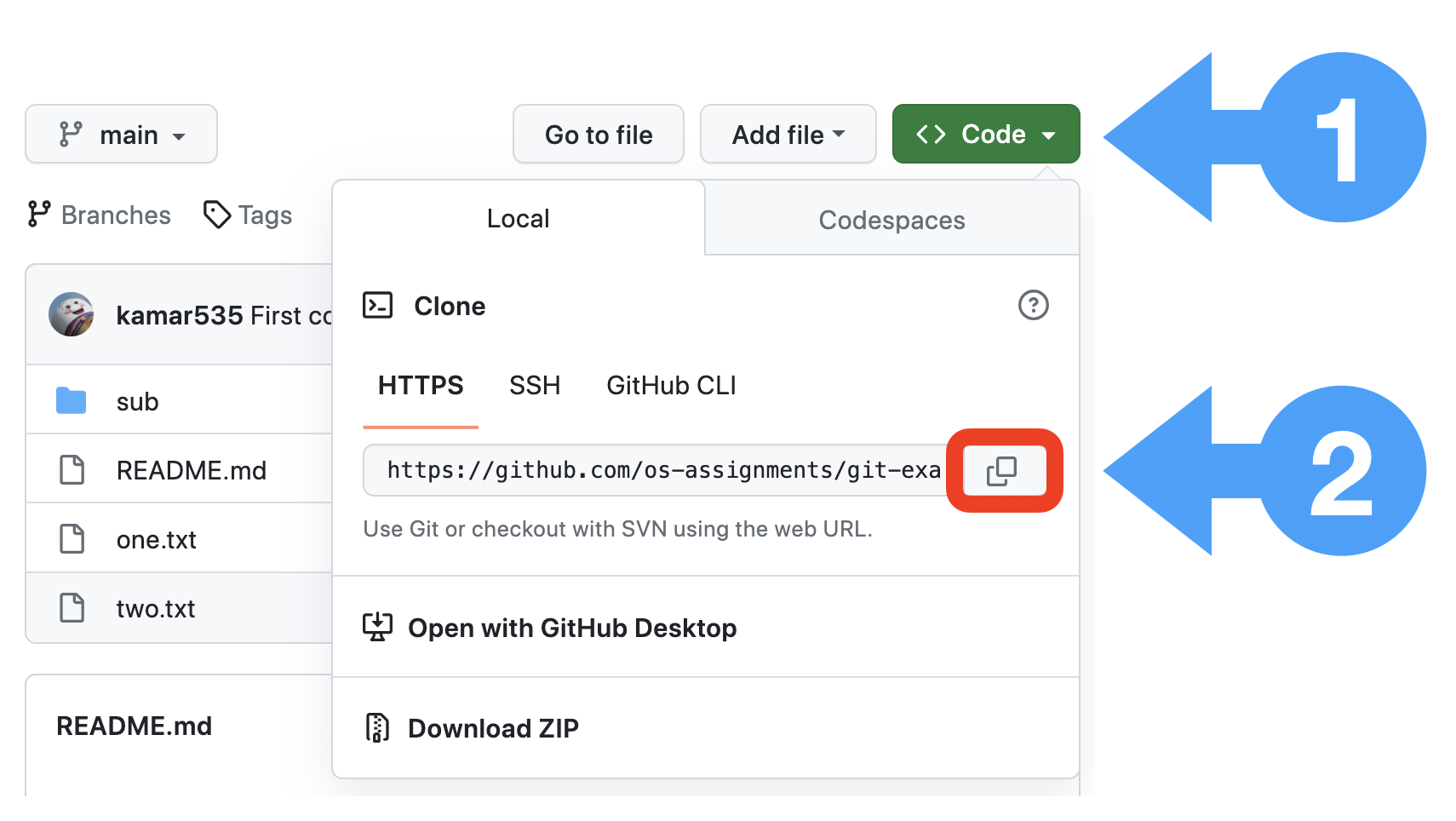
Cloning a repository
Click on the green button named Code (1). Now a small pop-up will
appear showing the repository URL. To copy the repository URL click on
copy-to-clipboard icon (2) to the right of the URL.
From the terminal, navigate to a directory where you want the cloned directory
to be created. To clone the example repository, type git clone followed by a space and paste the repository URL.
Note the first line Cloning into 'git-example-repo'.... This tell
you that the cloned repository is found in the newly created directory git-example-repo
within the current working directory.
Investigate the cloned directory
To get an overview of the cloned repository, use the tree command.
tree git-example-repo
The tree command will print out a tree view showing all files and folders in
the git-example-repo directory.
From the above we see that in the git-example-repo we find the files
README.md, one.txt and two.txt. In the same directory we also find a sub
directory named sub. Within the sub directory we find a single file named
three.txt.
Mips and Mars
In order to study how the operating system interacts with the
hardware, Mips assembly will be used.
To edit and execute Mips assembly programs we will use Mars (Mips
Assembler and Runtime Simulator). Mars is available on the department Windows and Linux system.
Mars will run on any system (including Windows) as long as you
have Java installed. If you prefer, you may download
and install Mars on your private computer.
Subsections of Mips and Mars
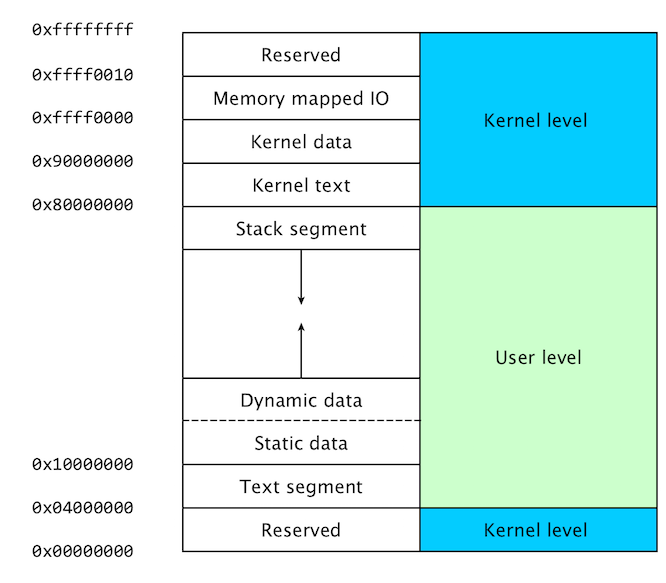
Mips memory layout
To execute a MIPS program memory must be allocated. The MIPS computer can
address 4 Gbyte of memory, from address 0x0000 0000 to 0xffff ffff. User memory
is limited to locations below 0x7fff ffff. In the below figure the layout of the
memory allocated to a MIPS program is shown.
The purpose of the various memory segments:
The user level code is stored in the text segment.
Static data (data known at compile time) use by the user program is stored
in the data segment.
Dynamic data (data allocated during runtime) by the user program is stored
in the heap.
The stack is used by the user program to store temporary data during for
example subroutine calls.
Kernel level code (exception and interrupt handlers) are stored in the
kernel text segment.
Static data used by the kernel is stored in the kernel data segment.
Memory mapped registers for IO devices are stored in the memory mapped IO
segment.
Clone repository
Before you continue, you must clone the mips-examples repository.
Use the git command
From the terminal, navigate to a directory where you want the cloned directory
to be created and execute the following command.
This is a short guide on how to launch and use Mars.
Mars is installed both on the department Windows system and the department Linux system.
Mars will run on any system (including Windows) as long as you
have Java installed. If you prefer, you may download
and install Mars on your private computer.
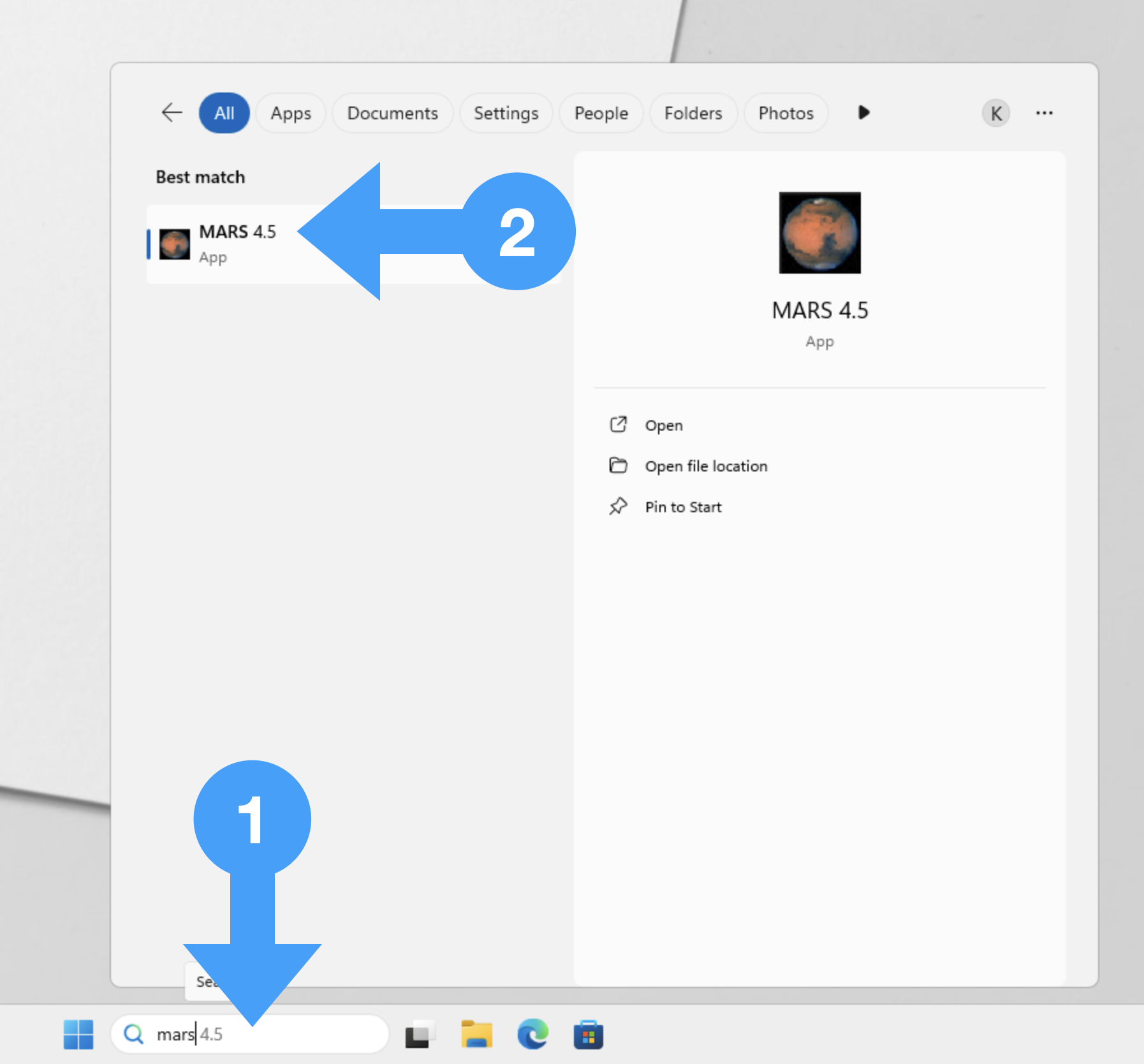
Run Mars from the department Windows system
Log in in to Windows. Search for Mars in the taskbar (1) and click on Mars (2).
Run Mars from the department Linux system
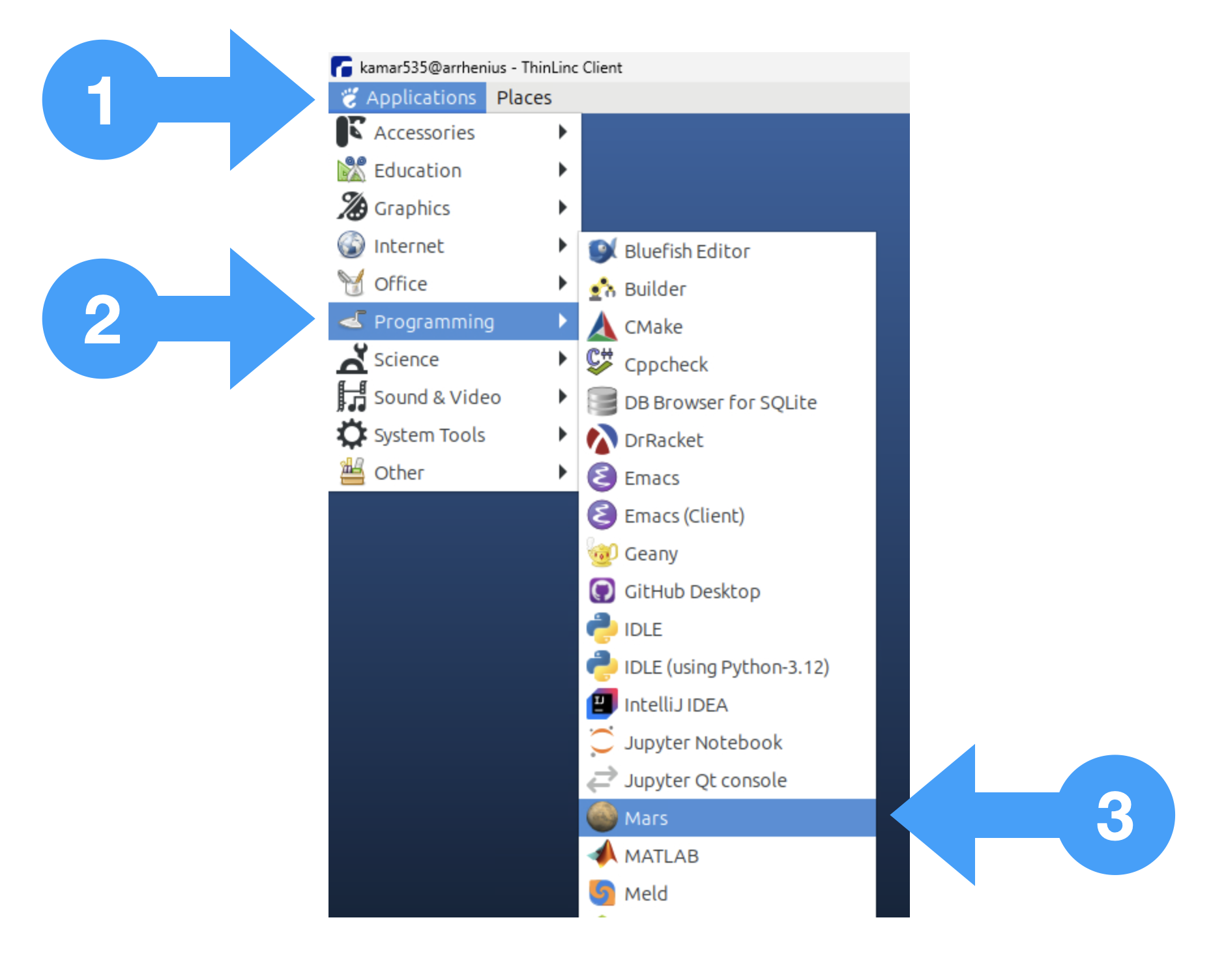
Log in to the department Linux system. From the Applications menu (1), select Programming (2) and then Mars (3).
Hello Mars
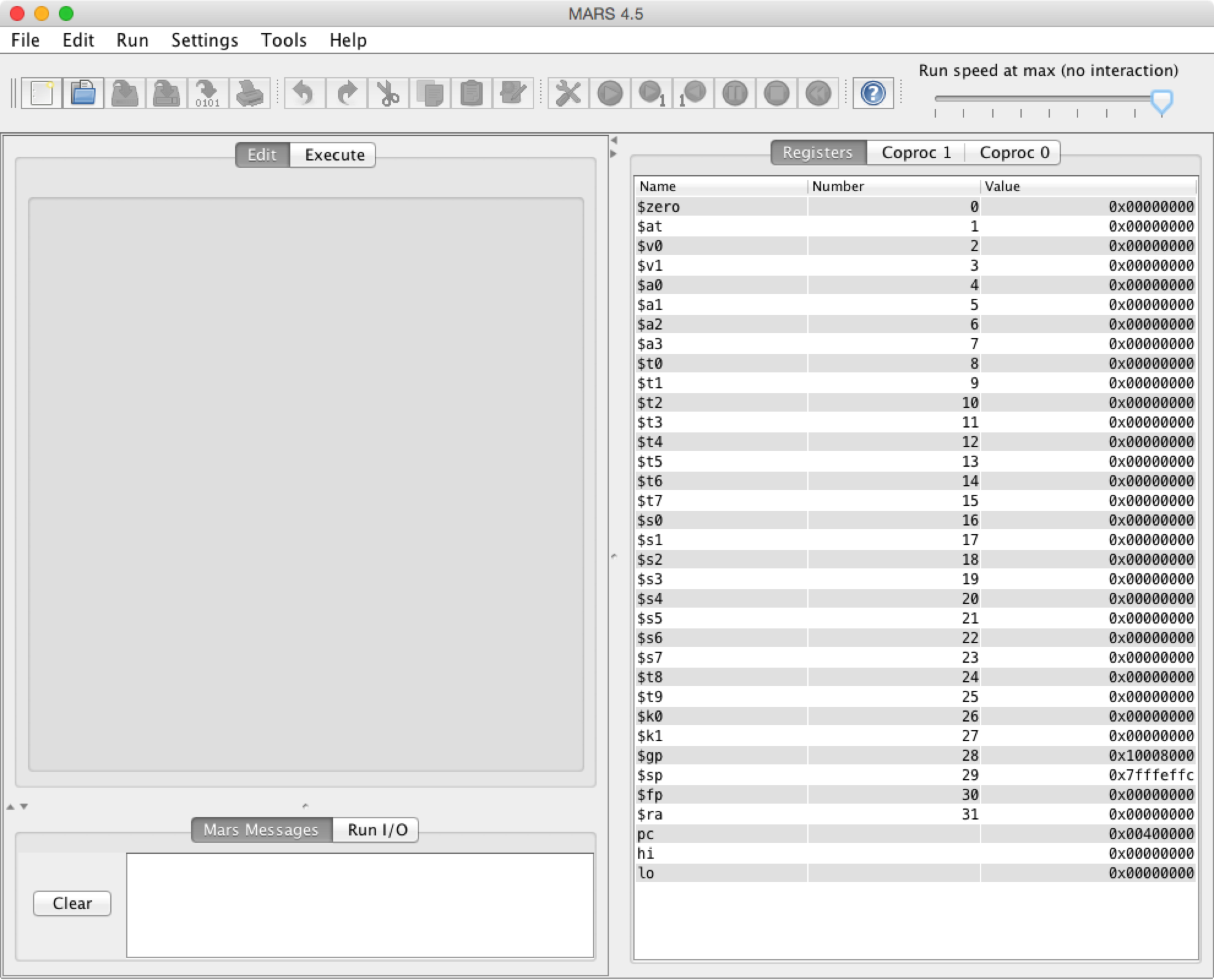
When you successfully start Mars you should see something similar to this.
IDE overview
Mars is an Integrated Development Environment (IDE) for Mips Assembly
Language Programming.
Top level menu
At the top you find the top level menu: File, Edit, Run, Settings, Tools and
Help.
Tools and operations
Under the top level menu a collection of icons show some of the most commonly
used tools and operations. The most important of these controls are described in
the below table.
Control
Description
Load a file.
Assemble the program in the Edit tab.
Save the current file.
Run the assembled program to completion (or breakpoint).
Execute a single instruction (single-step).
Undo the last instruction (single-step backwards).
Adjust the execution speed.
Edit and Execute
In the middle left you find two tabs: Edit and Execute.
The Edit tab will be used to edit assembly code.
The Execute tab shows the Text Segment (machine instructions) and
Data Segment during execution.
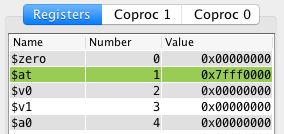
Registers
To the right you find the registers pane. Here the contents of all registers are
shown. There are three register tabs:
General purpose registers.
Coprocessor 0 registers.
Coprocessor 1 registers.
Mars Messages and Run I/O
In the lower left corner there are two tabs: Mars Messages and Run I/O.
The Mars Messages tab is used for displaying assembly or runtime errors and
informational messages. You can click on assembly error messages to highlight
and set focus on the corresponding line of code in the editor.
The Run I/O tab is used at runtime for displaying console output and
entering console input as program execution progresses.
The mips-examples repository
Before you continue you should already have cloned the
mips-examples repository.
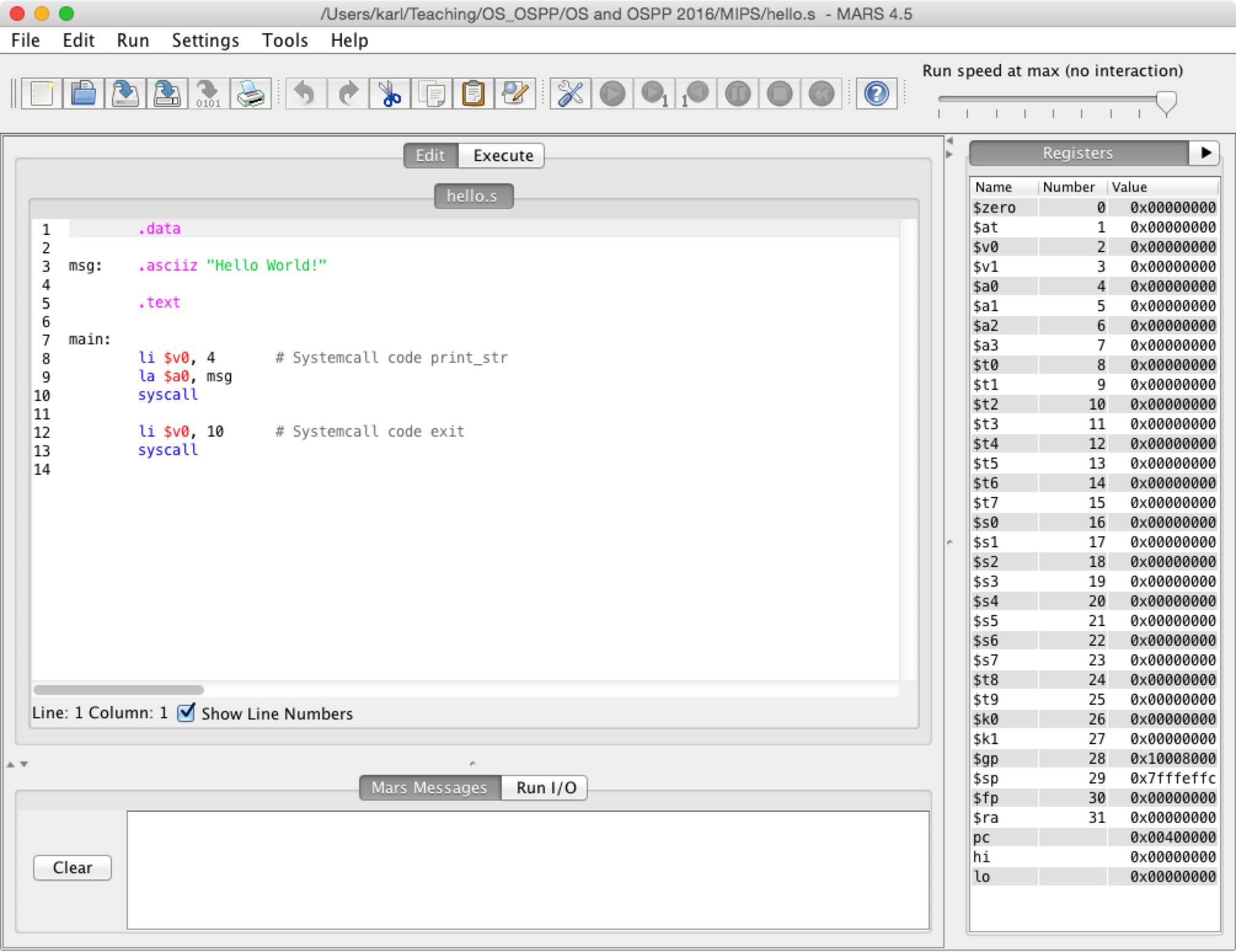
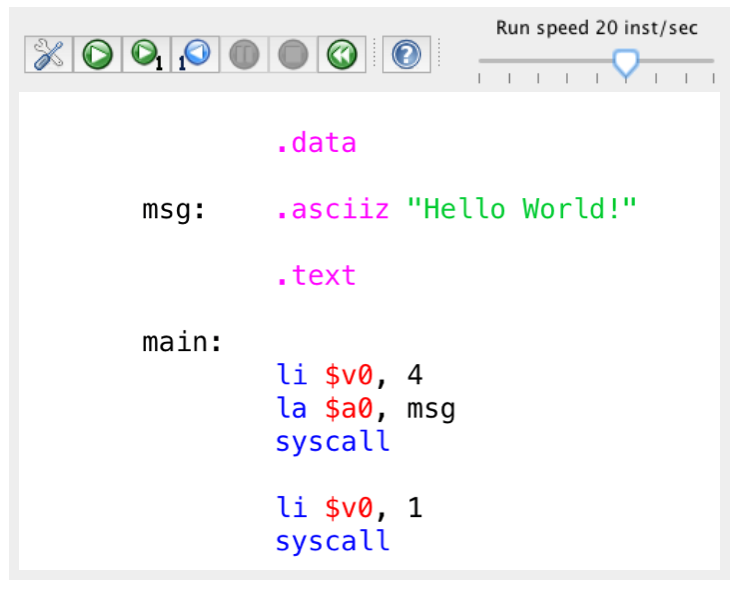
Load hello.s into Mars
Among the examples programs in the misp-exmples repository you find hello.s.
Open the file hello.s in the Mars simulator by selecting Open from the File menu.
You should now see something similar to this.
After you loaded a program, the source code is available for edit in the Edit pane.
Change font colors
The default font colors might not be the most pleasing on your eyes. Especially
the font color for comments may be hard to read. From the top menu, follow these steps to change
the font colors:
Settings
Editor …
Now a window named Text editor settings will open.
To the right you find the Syntax styling options.
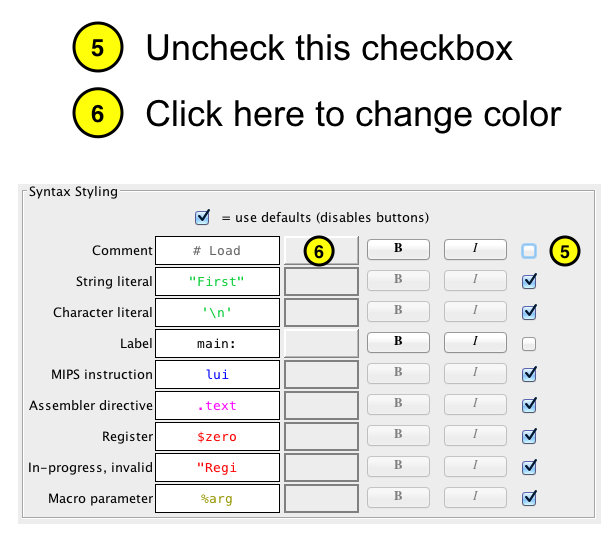
Un-check the checkbox to override the default font.
Click on the button to the right of the font preview to change the color of
the font.
Click on the button Apply and close in the lower left corner of the window to
apply your settings.
Assemble
To translate the Mips assembly source code to executable machine instructions an
assembler is used.
Assemble the file by clicking on the icon with the screwdriver and wrench.
Mars Messages
You should see something similar to the following in the Mars Messages display
pane.
After a successful assembly, the generated machine code instructions together
with the source code instructions are shown in the Execute pane.
Run to completion
Click on the play icon to run the program to completion.
Run I/O
In the the Run I/O display window you should see the following output.
Hello World!
-- program is finished running --
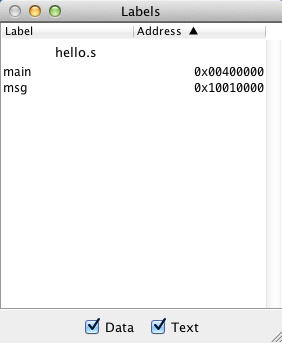
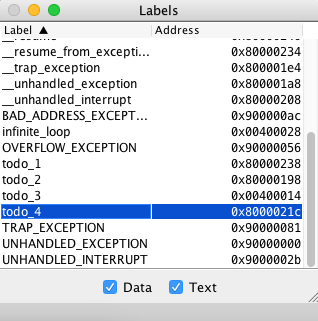
Symbol table
From the Settings menu, select Show Label Window (symbol table). Now, the
following window should appear.
The symbol table shows the actual memory addresses of all labels. For example,
we see that the label main is a mnemonic for the memory address 0x00400000.
When you click on a label in the symbol table, the address of the label is
highlighted in the text or data segment.
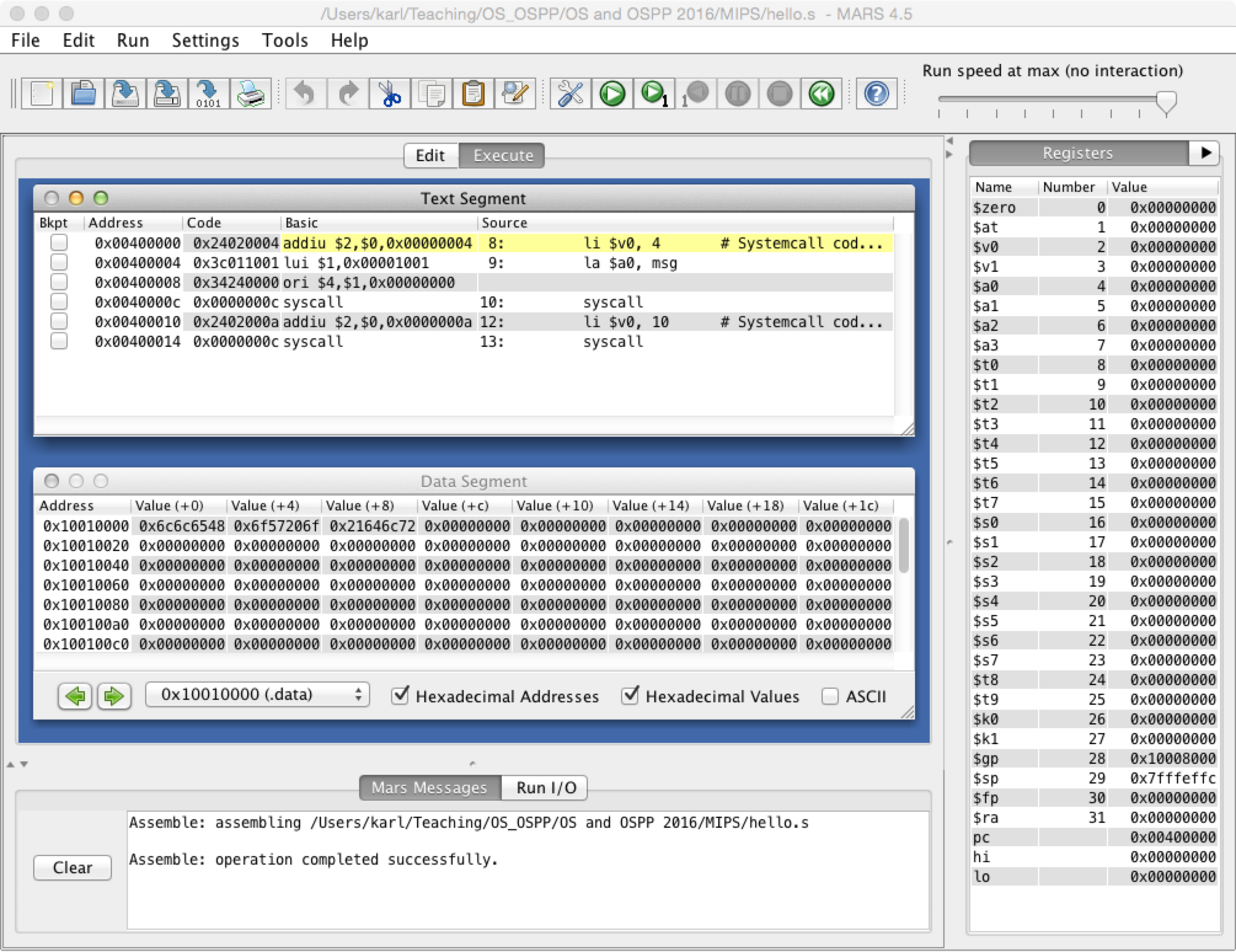
Text segment
In the symbol table, click on the label main.
Now the following row should be highlighted with a blue border in the Source
code column in the Text segment area in the Execute tab.
li$v0, 4# Systemcall code print_str
If you look at the source code (press the Edit tab) you see that this is the
instruction following directly after the label main.
Data segment
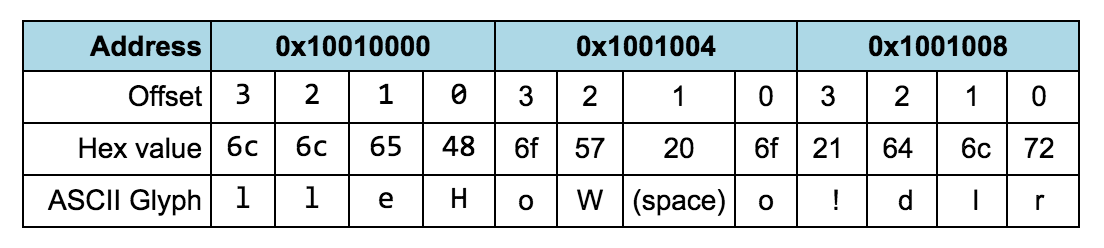
In the symbol table, click on the label msg.
Now address 0x10010000 should be highlighted with a blue border in the
Data Segment area in the Execute tab. The value store at this address is
0x6c6c6548.
If you study the data segment in detail you see that the string "Hello World!"
is stored byte for byte starting at address 0x10010000.
Breakpoints and debugging
A very usefull feature of Mars is the ability to set breakpoints. Breakpoints
together with single-stepping and backward single-stepping are very powerful when trying to understand or
debugging a program.
Assemble the file.
Make sure to view the Execute tab. In the Text segment, click the Bkpt
(breakpoint) checkbox at address 0x00400000.
This will set a breakpoint on the syscall instruction.
Click on the play icon to run the program.
The execution
will now halt at the breakpoint (the syscall instruction).
Click on the single-step icon to continue the execution one instruction at the time.
Click on the single-step-backwards icon to run the execution backwards one instruction at the time.
To help you refresh your MIPS assembly skills you are strongly encouraged to
study this small collection of example programs. Each program demonstrates a
small collection of features of the MIPS assembly language.
The mips-examples repository
Before you continue you should already have cloned the
mips-examples repository. If you have not done this already,
follow these instructions before you continue.
For each of the example files in the repository:
Read the source code.
Load the program in MARS and single step the program.
Try to understand how the program works.
Add your own experiments.
hello.s
File
hello.s
Description
A small “Hello World” program.
Assembly directives
.data, .asciiz and .text
Instructions
li and la.
System calls
print_string and exit.
basics.s
File
basics.s
Description
The basics of MIPS assembly.
Assembly directives
.data, .text, .space, .word and .asciiz.
Instructions
li, la, lw, add, addi, sw and move.
System calls
print_string, print_int, print_char and exit.
jump_and_branches.s
File
jump_and_branches.s
Description
Unconditional and conditional branches.
Implemented control structures
if-then-else and infinite loop.
Assembly directives
.data, .text, and .asciiz.
Instructions
j, blt and bge.
arrays.s
File
arrays.s
Description
Allocation and usage of arrays.
Data structures
Array of integers and array of strings.
subroutines.s
File
subroutines.s
Description
A short introduction to the basic use of subroutines.
A very good introduction to Mips assembly programming which also includes
detailed documentation for the MIPS R2000 assembly language instruction set.
C programming
To study operating system concepts we will use the C programming language.
Subsections of C programming
Important concepts
To study operating system concepts we will use the C programming language. To be
able to understand the tutorials and solve the programming assignments you will
need to be familiar with the following C programming concepts.
Basic data types such as int and char.
Arrays.
Strings (array of char).
Basic use of the #define directive.
Basic use of printf() to print text to the terminal.
For the tutorials and programming assignments you will be required to use
the
C programming language.
If you are new to C or need to refresh you knowledge there are plenty of
resources available on the web. On this page you find a small collections of
recommended links.
A short introduction to C programming
C Programming
Introduction (PDF) is a
comprehensive set of slides introducing the basic concepts of C programming
put together by Md Tahseen Anam, teaching assistant on the OS (1DT044) course, autumn 2020.
The online C book: This is the
online version of The C Book, second edition by Mike Banahan, Declan Brady and
Mark Doran, originally published by Addison Wesley in 1991.
C for java programmers
C and C++ for Java Programmers:
If you are familiar with the Java programming language already but are new to
the C programming language, this might be for you.
C for Java Programmers (PDF):
This is another introduction to the C programming language for people who
already know Java.
C programming exercise
Before starting working on the tutorials and programming assignments you should make sure you
are familiar with a few important C programming concepts.
To test your C programming skills you are encouraged to solve the programming
exercise described below.
Clone repository
Before you continue, you must clone the c-address-book repository.
From the terminal, navigate to a directory where you want the cloned directory
to be created and execute the following command.
The functions you need to implement are already declared in address_book.h.
You should also define the structures you will need in address_book.h. You are
free to create more functions if you want.
address_book.c
In the file address_book.c you should implement the functions declared in
adress_book.h.
main.c
The main() function, which is the entry point of your program will be in a
file called main.c.
Representing a person
Create a struct Person that will be used to represent a person. This struct
should store:
The full name
The age
The phone number
It is up to you to choose the right datatypes for the fields of the structure.
Representing the address book
Create a structAddress_book that will contain a pointer to an
array of structPerson, as well as the size of this array (the number
of persons in the address book).
Printing a person
Create a function print_person() that takes a pointer to a Personstructure and
prints its details on the standard output.
A possible output for a person named
John Doe, 42 years old, with the phone number +46712345678:
Name: John Doe
Age: 42Phone number: +46712345678
Printing an address book
Create a function print_address_book() that takes a pointer to an address book
and prints its details on the standard output. Make use of the print_person()
function you just created.
A possible output for an address book containing two
entries is:
==== Address book (2 entries)=====Name: John Doe
Age: 42Phone number: +46712345678
Name: Foo Bar
Age: 24Phone number: +46787654321
Creating an address book
We will now read information from the user and store it into an address book.
Create a create_address_book() function. This function should:
Create (dynamically) an empty address book.
Read from the standard input the number of persons that the user intends to put into the address book.
Dynamically allocate an array of structPerson of the correct size and store a pointer to it in the address book. You are not allowed to use Variable Length Arrays!
In a loop, read from the standard input the information you need for every person to be stored in the address book. Assume that the inputs are correct, so you are not expected to validate them.
Return the address book.
Hints: Dynamic allocation is done with malloc(). Reading from the standard input can be done using scanf() or fgets().
Fundamental concepts
Fundamental principles of how the operating system interacts with the hardware.
Subsections of Fundamental concepts
Initial definitions
CPU
The central processing unit (CPU) is the electronic circuitry within a computer
that carries out the instructions of a computer program by performing the basic
arithmetic, logical, control and input/output (I/O) operations specified by the
instructions. 1
Register
A processor register is a quickly accessible location available to a computer’s
central processing unit (CPU). Registers usually consist of a small amount of
fast storage. 2 A CPU only has a small number of registers.
Memory
Memory refers to the computer hardware integrated circuits that store
information for immediate use in a computer; it is synonymous with the term
“primary storage”. 3 The memory is much slower than the CPU register but
much larger in size.
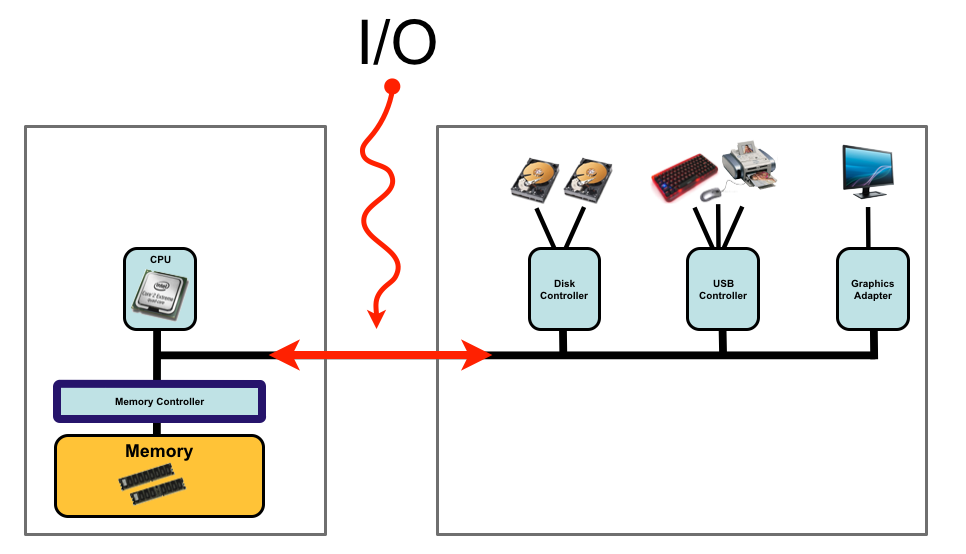
Computer system
A typical computer system consists of a CPU, memory and external devices such as
hard drives (disks), keyboard, screens, mouse and printers. The CPU and the
device controllers can execute in parallel, competing for memory cycles. To
ensure orderly access to the shared memory, a memory controller is provided
whose function is to synchronize the access to the memory.
Input/Output (I/O)
In computing, input/output or I/O (or, informally, io or IO) is the communication
between an information processing system, such as a computer, and the outside
world, possibly a human or another information processing system. Inputs are the
signals or data received by the system and outputs are the signals or data sent
from it. The term can also be used as part of an action; to “perform I/O” is to
perform an input or output operation. 4
For our purposes, any transfer of information between the CPU/Memory and any of the
external devices is considered I/O.
Usually I/O operations does not make use of the CPU but are handled by the external
devices.
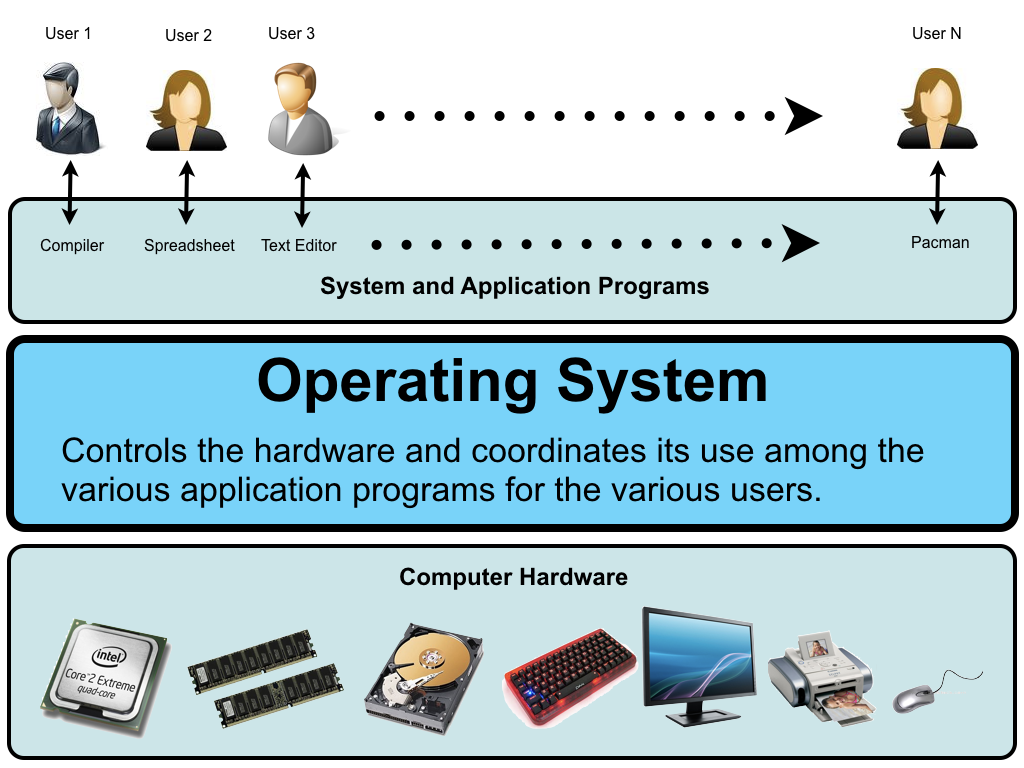
Operating system
An operating system (OS) is system software that manages computer hardware and
software resources and provides common services for computer programs. 5
The OS controls the hardware and coordinates its use among the various application
programs for the various user.
Program, executable and process
In order to execute a program, the operating system must first create a process
and make the process execute the program.
Program
A set of instructions which is in human readable format. A passive entity
stored on secondary storage.
Executable
A compiled form of a program including machine instructions and static data
that a computer can load and execute. A passive entity stored on secondary
storage.
Process
An executable loaded into memory and executing or waiting. A process typically
executes for only a short time before it either finishes or needs to perform I/O
(waiting). A process is an active entity and needs resources such as CPU time,
memory etc to execute.
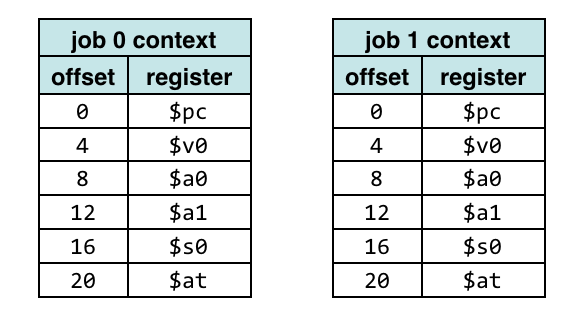
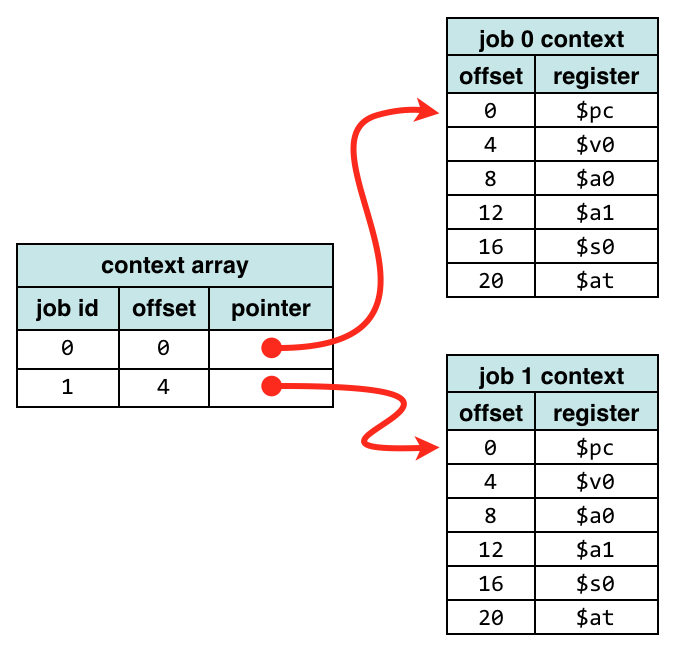
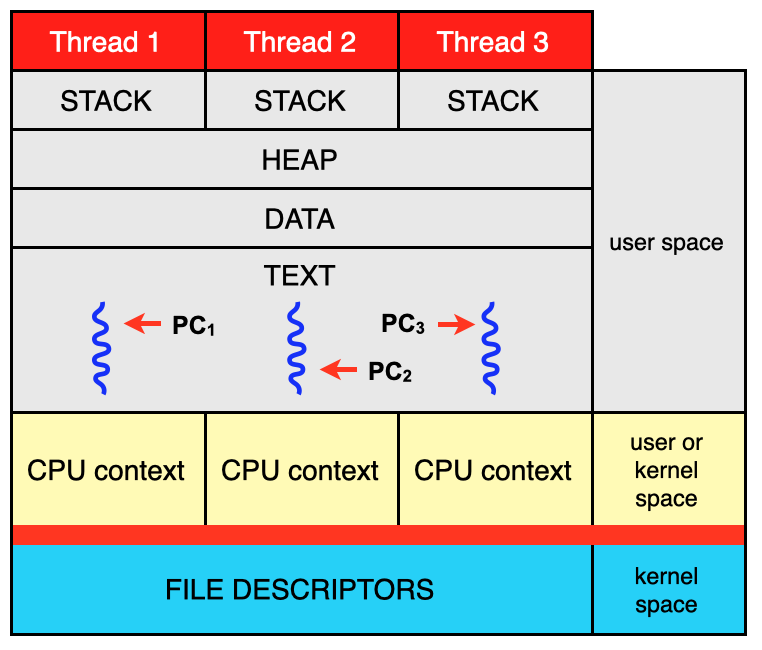
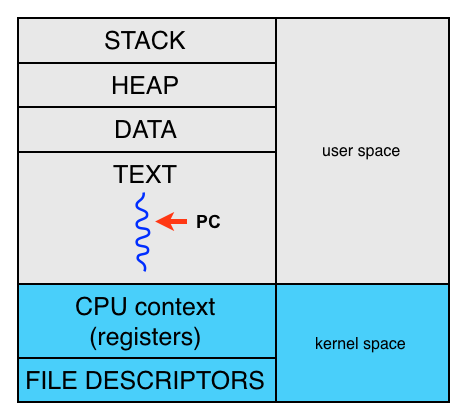
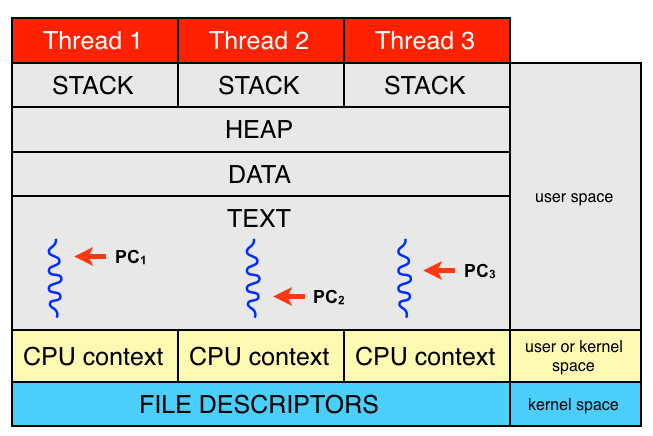
CPU context (CPU state)
At any point in time, the values of all the registers in the CPU defines the
CPU context. Sometimes CPU state is used instead of CPU context.
More generally, a task context is the minimal set of data used by a task (which
may be a process or thread) that must be saved to allow a task to be
interrupted, and later continued from the same point. 6
Kernel
The kernel is a computer program that is the core of a computer’s operating
system, with complete control over everything in the system. 7
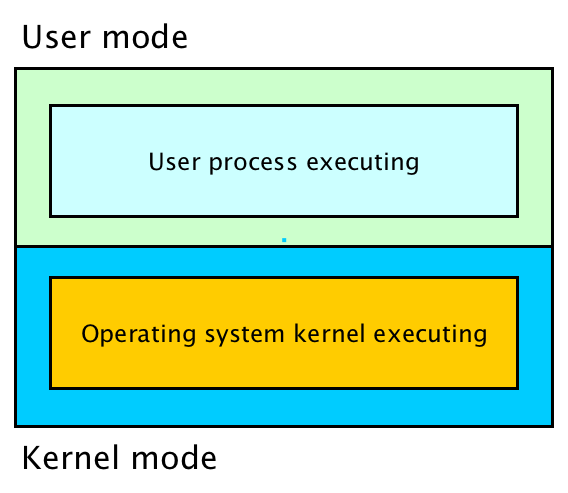
Dual mode operation
In order to protect the operating system from user processes two modes are
provided by the hardware: user mode and kernel mode.
Dual mode operation place restrictions on the type and scope of operations that
can be executed by the CPU. This design allows the operating system kernel
to execute with more privileges than user application processes.
Synchronous and asynchronous events
Synchronous means happening, existing, or arising at precisely the same time. 8
Asynchronous simply means “not synchronous”.
If an event occurs at the same instruction every time the program is executed with the
same data and memory allocation, the event is synchronous. An synchronous event
is directly related to the instruction currently being executed by the CPU. On
the other hand, an asynchronous event is not directly related to the instruction
currently being executed by the CPU.
Exceptions and interrupts
Interrupts and exceptions are used to notify the CPU of events that needs
immediate attention during program execution.
Exceptions and interrupts are events that alters the normal sequence of
instructions executed by a processor. Such events correspond to electrical
signals generated by hardware circuits both inside and outside the CPU chip.
Exceptions are internal and synchronous
Exceptions are used to handle internal program errors.
Overflow, division by zero and bad data address
are examples of internal errors in a program.
Another name for exception is trap. A trap (or exception) is a
software generated interrupt.
Exceptions are produced by the
CPU control unit while executing instructions and are considered to be
synchronous because the control unit issues them only after terminating the
execution of an instruction.
Interrupts are external and asynchronous
Interrupts are used to notify the CPU of external events.
Interrupts are generated by hardware devices
outside the CPU at arbitrary times with respect to the CPU clock signals and are
therefore considered to be asynchronous.
Key-presses on a keyboard might happen at any
time. Even if a program is run multiple times with the
same input data, the timing of the key presses will
most likely vary.
Read and write requests to disk is similar to key
presses. The disk controller is external to the executing
process and the timing of a disk operation might
vary even if the same program is executed several
times.
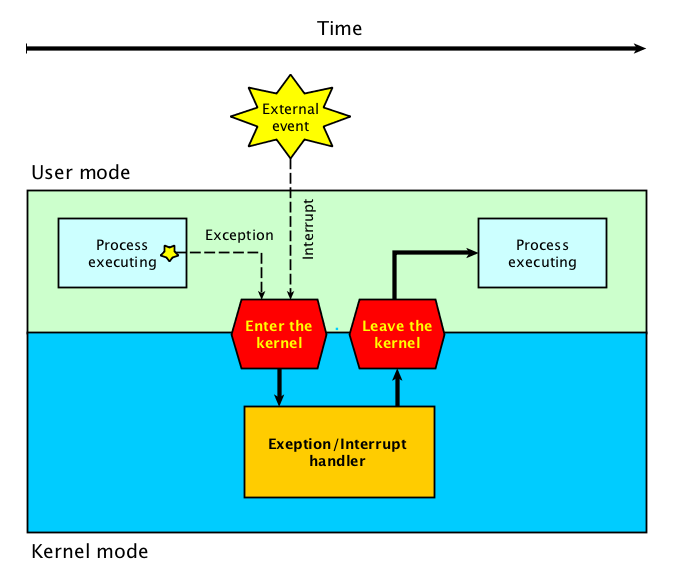
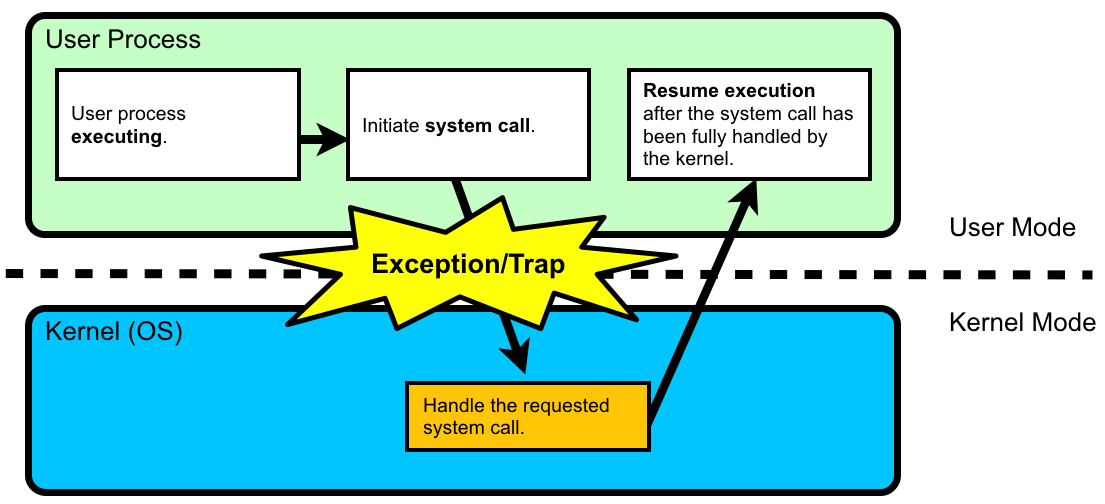
Exception and interrupt handler
When an exception or interrupt occurs, execution transition from user mode to
kernel mode where the exception or interrupt is handled. When the exception or
interrupt has been handled execution resumes in user space.
System call
A user program requests service from the operating system using system calls.
System calls are implemented using a special system call exception. Another name
for exception is trap.
What should be done when an exception or interrupt occurs?
Overview
When an exception or interrupt occurs, execution transition from user mode to
kernel mode where the exception or interrupt is handled. When the exception or
interrupt has been handled execution resumes in user space.
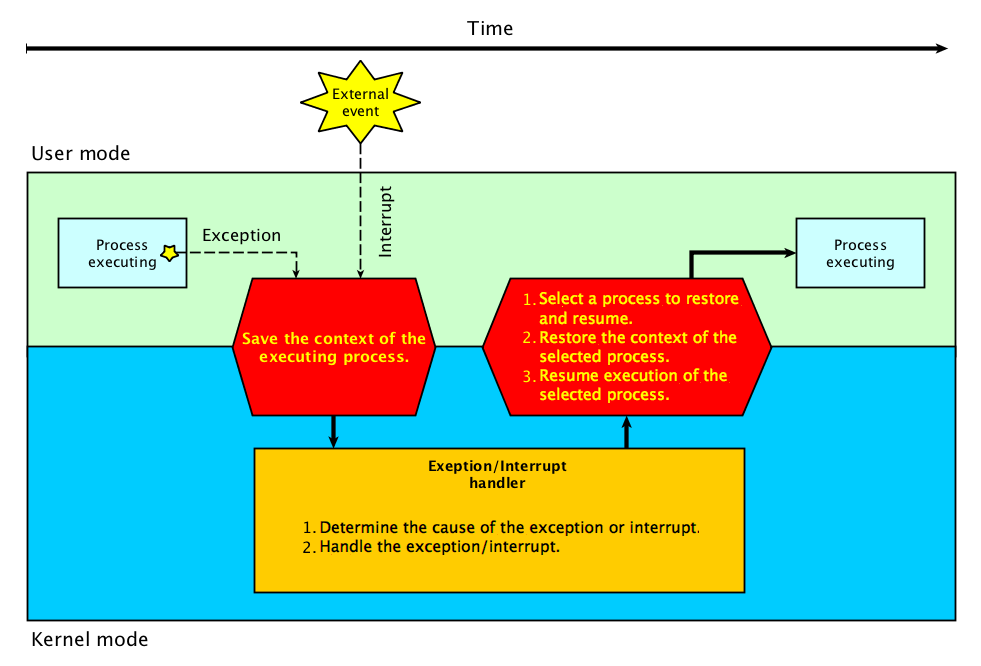
Details
When an exception or interrupt occurs, execution transition from user mode to
kernel mode where the exception or interrupt is handled. In detail, the
following steps must be taken to handle an exception or interrupts.
While entering the
kernel, the context (values of all CPU registers) of the currently executing process must first be saved to
memory.
The kernel is now ready to handle the exception/interrupt.
Determine the cause of the exception/interrupt.
Handle the exception/interrupt.
When the exception/interrupt have been handled the kernel performs the following
steps:
Select a process to restore and resume.
Restore the context of the selected process.
Resume execution of the selected process.
CPU context (CPU state)
At any point in time, the values of all the registers in the CPU defines the
context of the CPU. Another name used for CPU context is CPU state.
Saving context
The exception/interrupt handler uses the same CPU as the currently executing
process. When entering the exception/interrupt
handler, the values in all CPU registers to be used by the exception/interrupt
handler must be saved to memory. The saved register values can later restored before resuming
execution of the process.
Determine the cause
The handler may have been invoked for a number of reasons. The handler thus
needs to determine the cause of the exception or interrupt. Information about
what caused the exception or interrupt can be stored in dedicated registers or
at predefined addresses in memory.
Handle the exception/interrupt
Next, the exception or interrupt needs to be serviced. For instance, if it was a
keyboard interrupt, then the key code of the keypress is obtained and stored
some where or some other appropriate action is taken. If it was an arithmetic
overflow exception, an error message may be printed or the program may be
terminated.
Select a process to resume
The exception/interrupt have now been handled and the kernel.
The kernel may choose to resume the same process that was executing prior to
handling the exception/interrupt or resume execution of any other process
currently in memory.
Restoring context
The context of the CPU can now be restored for the chosen
process by reading and restoring all register values from memory.
Resume
The process selected to be resumed must be resumed at the same point it was
stopped. The address of this instruction was saved by the machine when the
interrupt occurred, so it is simply a matter of getting this address and make
the CPU continue to execute at this address.
Waiting for keyboard input
Humans are very slow compared to the CPU. No matter how fast you are,
the CPU will be able to execute a huge number of instructions between every
key-press you make.
How can we make the CPU wait for a human user to press a key on the
keyboard?
Is it possible to make the CPU do something useful while waiting for user
input?
Polling
To detect a key-press, one option is to repeatedly check the state of the input
device until the device has detected a key press. Usually such a device will use
one bit in a special device register to signal whether no input has occurred
(bit = 0) or if new input is available (bit = 1).
Polling refers to actively sampling the status of an external device at
regular intervals. Polling requires the use of the CPU to check the status of an
external device. Polling also refers to the situation where a device is
repeatedly checked for readiness, and if it is not the computer returns to a
different task between checking the status.
Polling is most often used in terms of input/output (I/O), and is also referred
to as polled I/O or software driven I/O.
More generally, polling can be summarized as follows.
A program cannot proceed until an external device becomes ready.
The program checks the status of the external device.
If the device is not ready, the program either:
Do some work not depending on the status of the device for a short amount
of time, then go back to step 2.
Gives the CPU to another program, and then when the operating system gives
it the CPU back again, go back to step 2.
The device is now ready, go to step 3.
The program can now proceed and take appropriate action.
Busy waiting
If the program continuously polls the device without doing anything in between
checks, it’s called a busy-waiting.
Repeatedly checking the status of the input device require the use of the CPU.
Using a conditional loop the CPU can repeatedly load the value of the status
register to check if new input is available. While waiting for input the CPU
doesn’t do any other work, the CPU is busy-waiting.
Polling ≠ Busy-Waiting
The term polling is sometimes used synonymously with busy-waiting but you
should be aware of the differences between polling and busy-waiting.
Interrupts
Interrupts are used to signal events external to the program (timers,
serial ports, keyboard input etc). Interrupts are generated by other hardware
devices outside the CPU at arbitrary times with respect to the CPU clock signals
and are therefore considered to be asynchronous.
A user program executes in user mode (text segment). When an interrupt happens,
control is automatically transferred to the interrupt handler executing in
kernel mode (ktext segment).
An alternative to both polling and busy-waiting is to make the input device
generate an interrupt every time new input is available. Using interrupts makes
it possible for the CPU to do something useful, for example execute
another program, while waiting for user input.
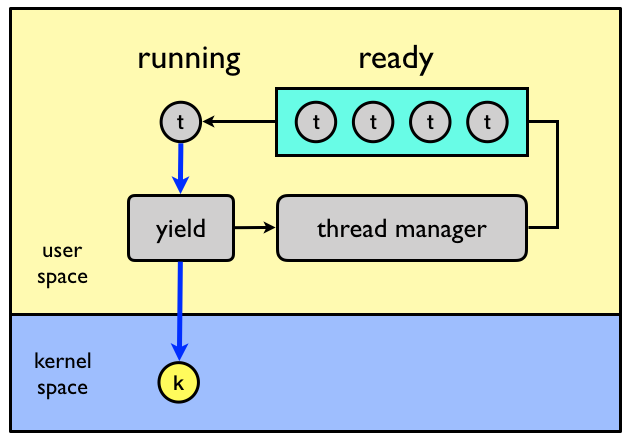
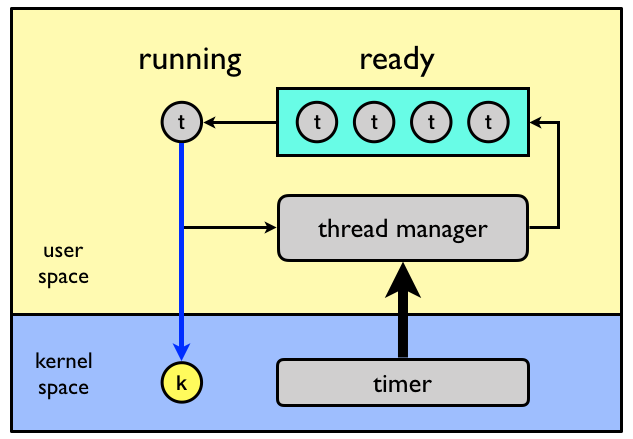
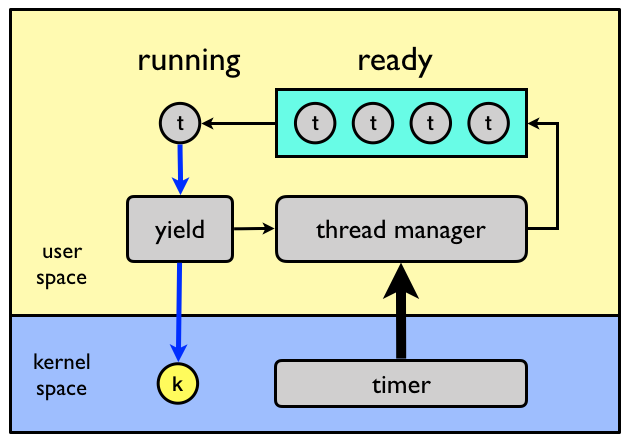
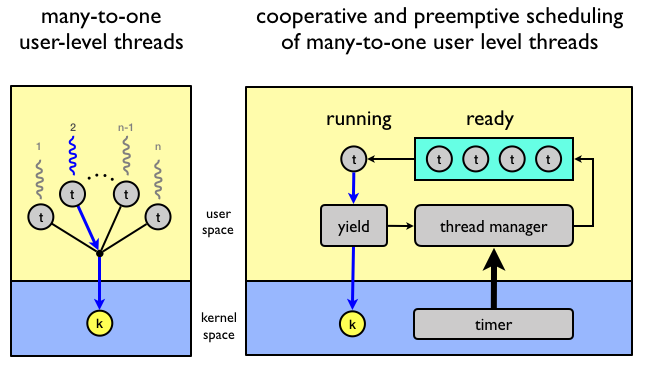
Multiprogramming
In general, I/O operations does not make use of the CPU but are handled by external devices.
Compared to the CPU, I/O operations are very slow and while waiting for I/O the CPU
is idle doing nothing. To overcome this problem multiprogramming was
invented.
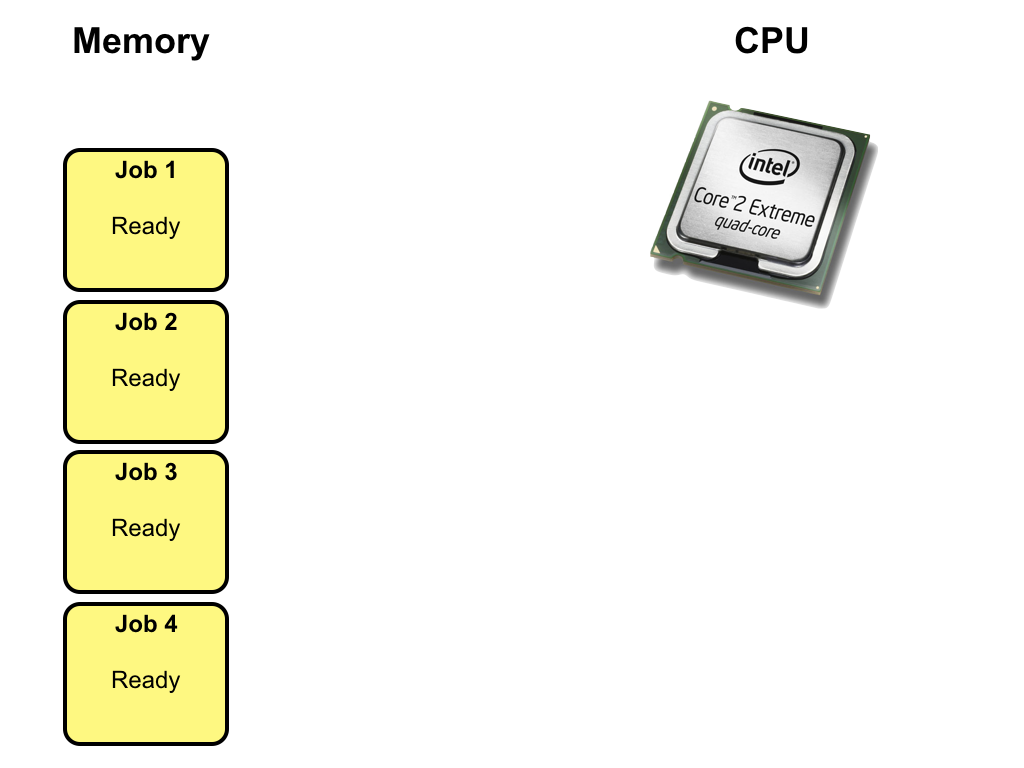
Job
In systems using multiprogramming a program loaded to memory and ready
to execute is called a job.
Execute another job while waiting for I/O
The simple idea is to always have one job execute on the CPU by changing job when an I/O request is made.
States
In a multiprogramming system, a job can be in one of three states.
Running
The job is currently executing on the CPU. At any time, at most one job can be in this state.
Ready
The job is ready to run but currently not selected to do so.
Waiting
The job is blocked from running on the CPU while waiting for an I/O request to be
completed.
State transitions
In a multiprogramming system, a the following state transitions are possible.
From
To
Description
Running
Waiting
When a running job requests I/O, the job changes state from running to waiting.
Waiting
Ready
When an I/O requests completes, the job waiting for the request to complete changes state from waiting to ready.
Ready
Running
When an I/O requests completes, one of the ready jobs are selected to run on the CPU and changes state from ready to running.
The problem is, how will the system know when an I/O request is completed?
Interrupts
To implement multiprogramming interrupts are used to notify the system of
important events such as the completion of an I/O request.
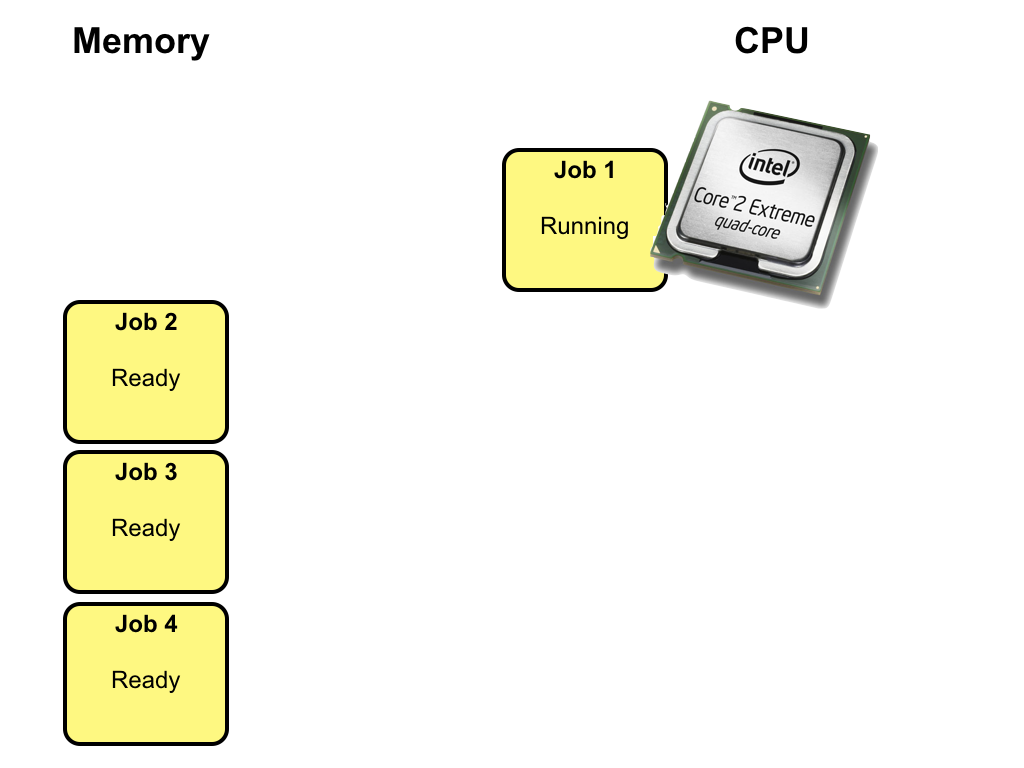
Step by step
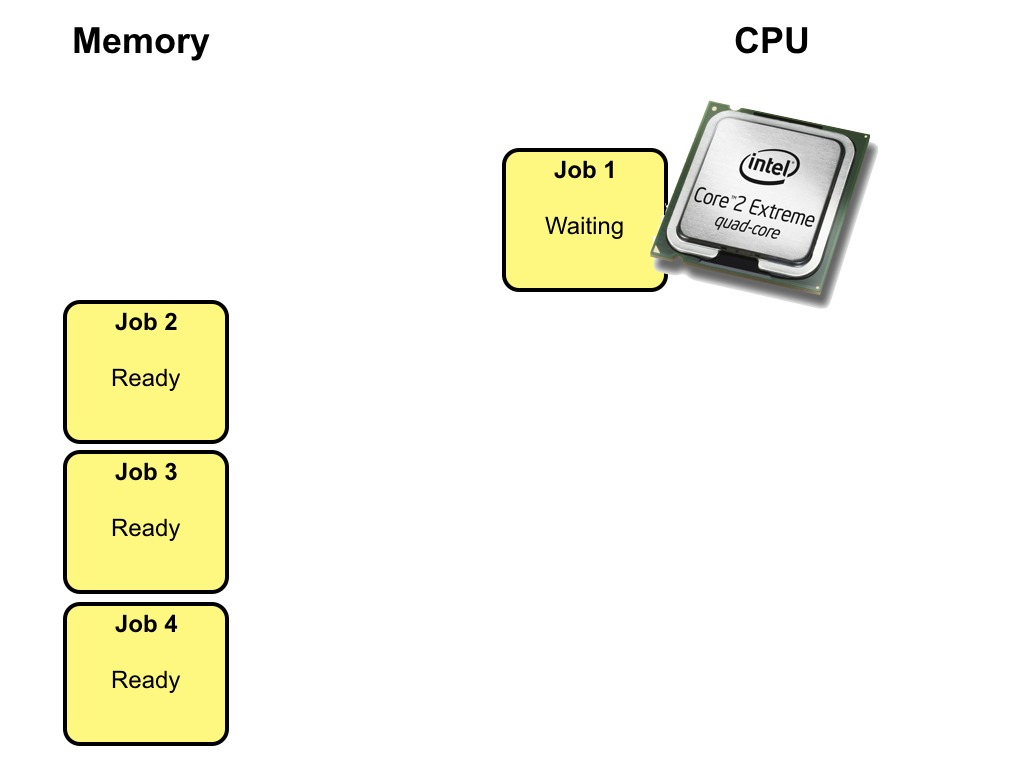
In a multiprogramming system, several jobs are kept in memory at the same time.
Initially, all jobs are int the ready state.
One of the ready jobs is selected to execute on the CPU and changes state from
ready to running. In this example, job 1 is selected to execute.
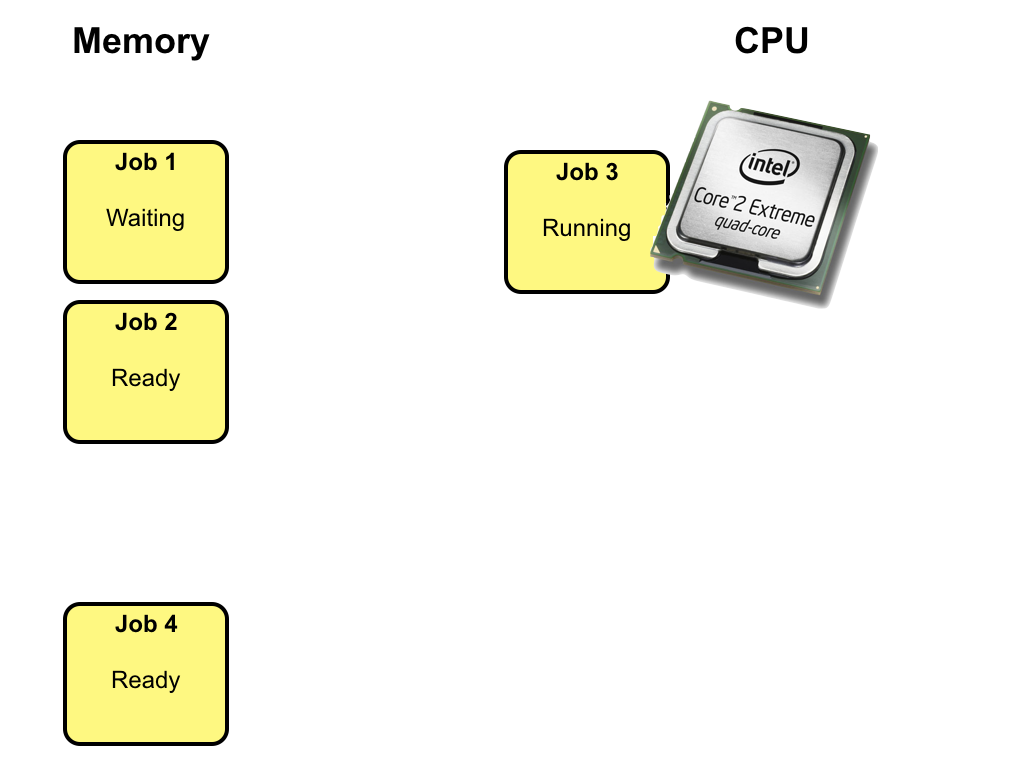
Eventually, the running job makes a request for I/O and the state changes from
running to waiting.
Instead of idle waiting for the I/O request to complete, one of the ready jobs is
selected to execute on the CPU and have its state change from ready to running.
In this example job 3 is selected to execute.
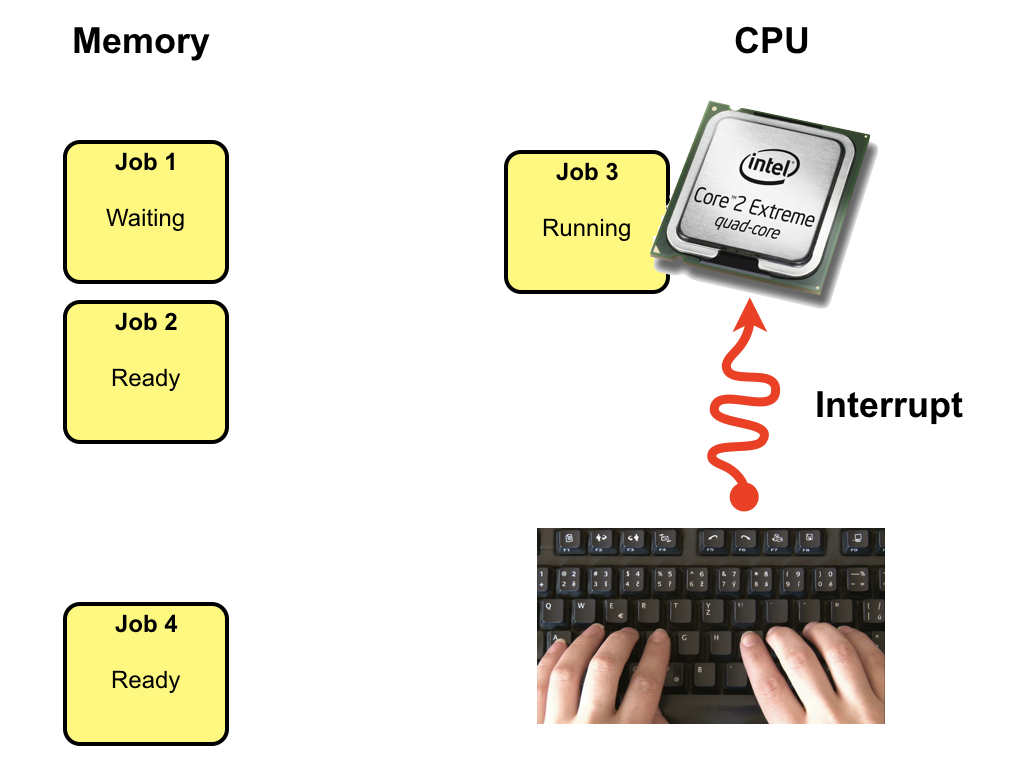
Eventually the the I/O request job 1 is waiting for will complete and the CPU will be
notified by an interrupt. In this example, job 1 was waiting for a keypress on
the keyboard.
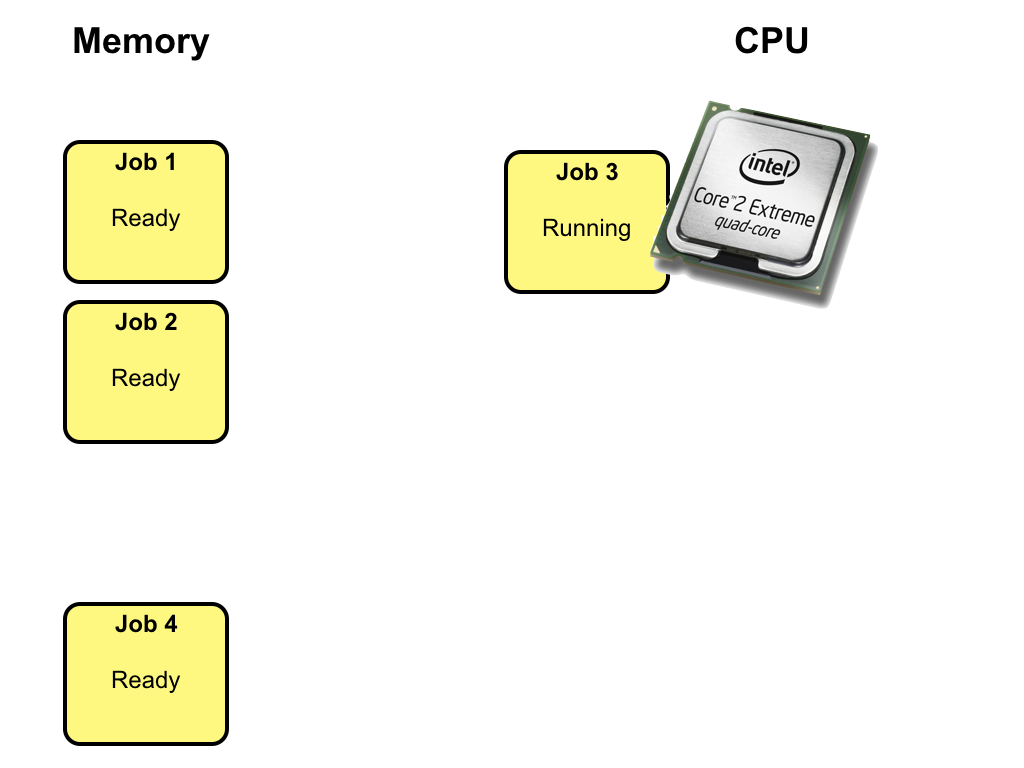
The state of the waiting job (job 1) will change
from waiting to ready.
System call design
As an example of how multiprogramming handles I/O requests we will study how to
wait for the user to input data from the keyboard.
Key-presses are asynchronous and external
A user pressing a key on a keyboard is not an internal event, nor is a
key-press synchronous, a keypress can happen at any time independent of the
executing program.
Normally the operating system is responsible for handling user input and output.
When a user program requests service from the operating system this is
implemented as system calls.
System calls
System calls forms an interface between user programs and the
operating system.
We will start by to study how to implement a system call that lets the user input a single
character from the keyboard. Next we will study how to implement a system call
that lets the user input a string from
the keyboard.
Read character system call design
Let’s sketch the design for a system call similar to the C
library function getc that allows a program to read a single single character typed by a human user on
the keyboard.
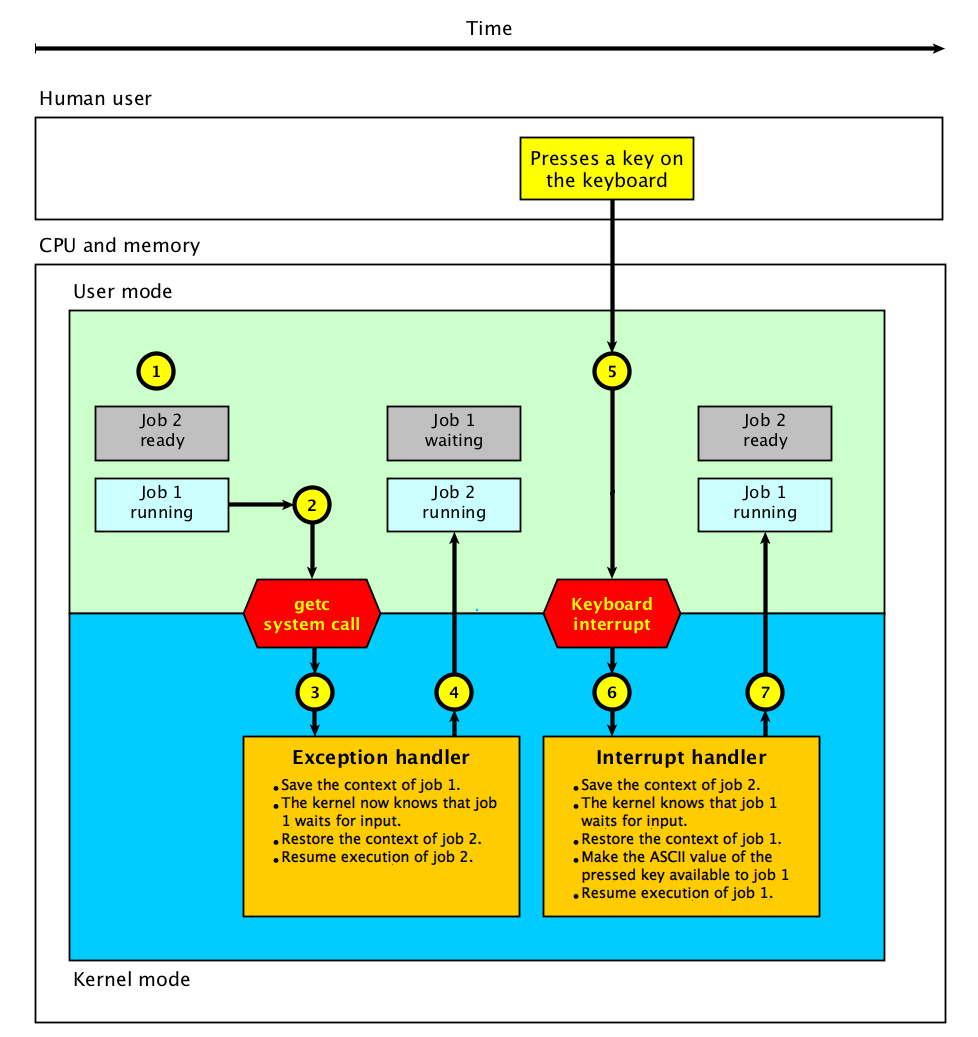
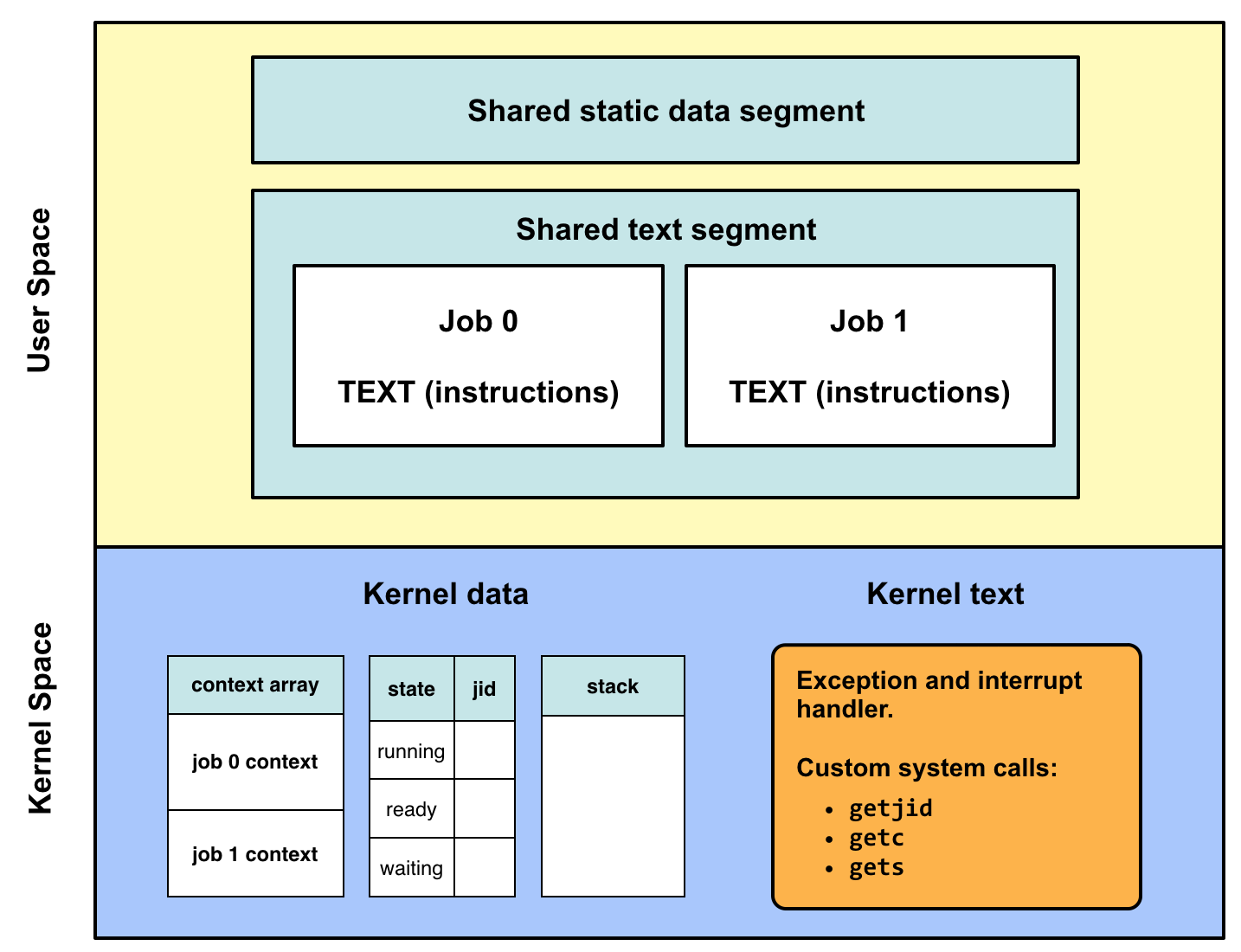
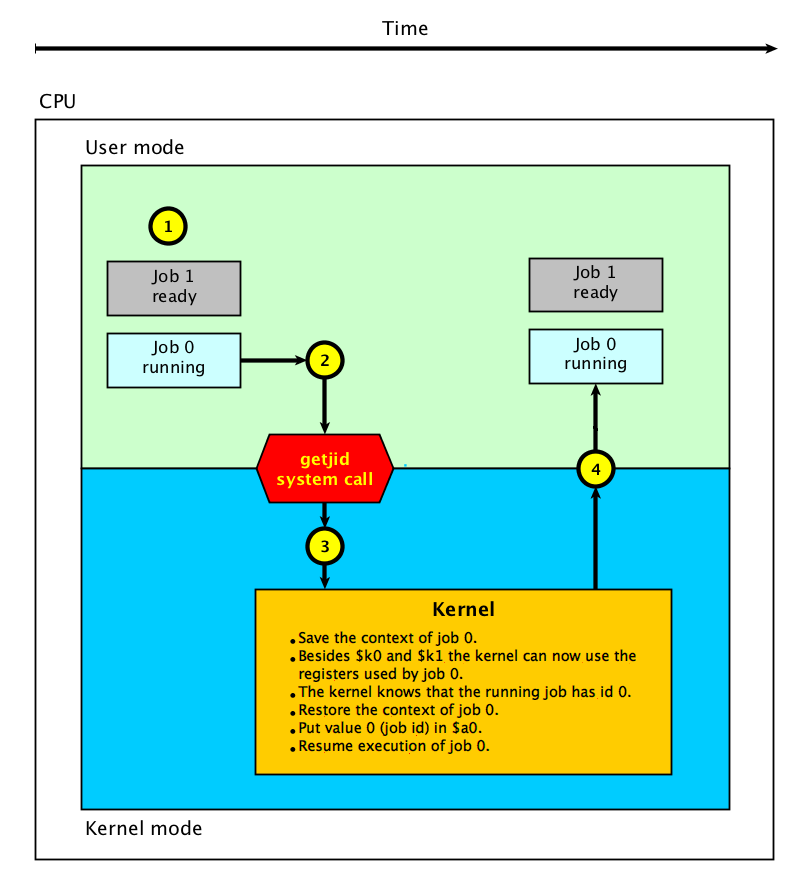
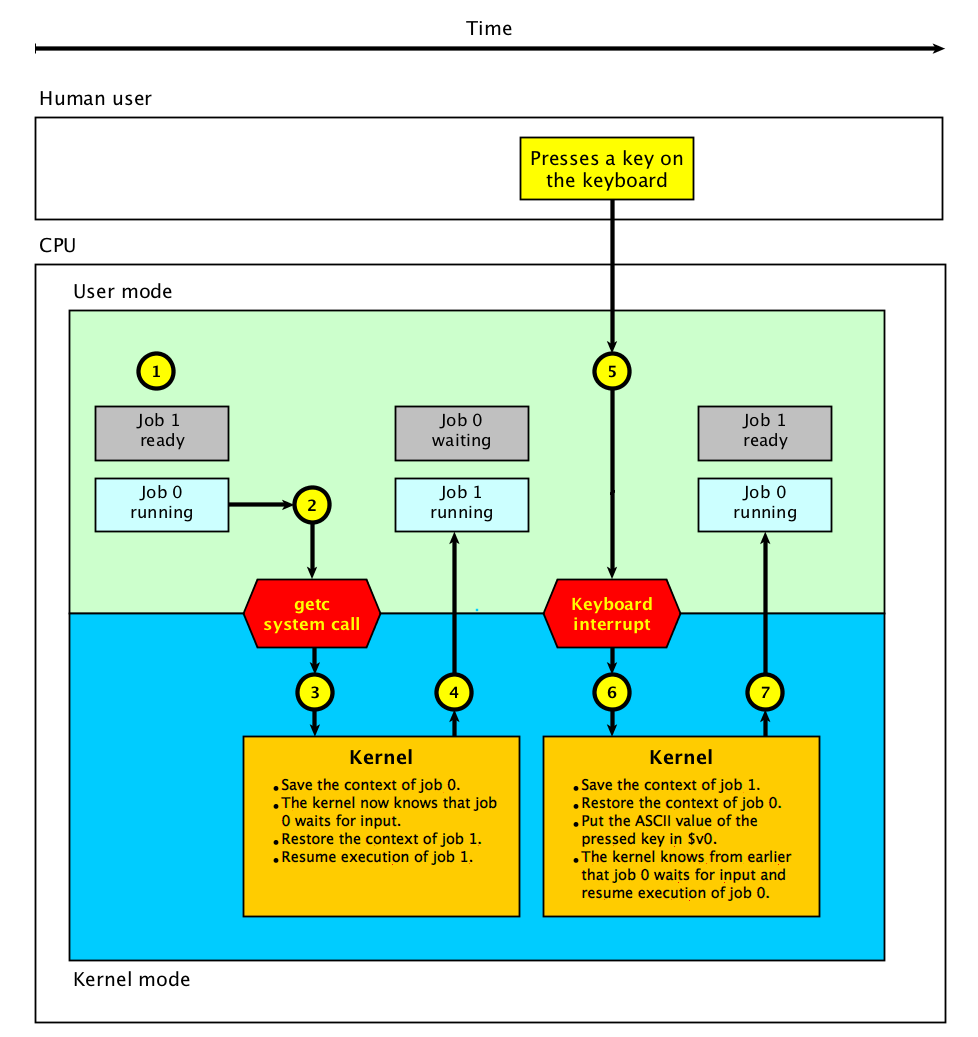
The below figure shows an example where job 1 calls the custom getc system
call and job 2 executes while job 1 waits for the user to press a key on
the keyboard.
In the above figure important events are marked with a number inside a yellow
circle.
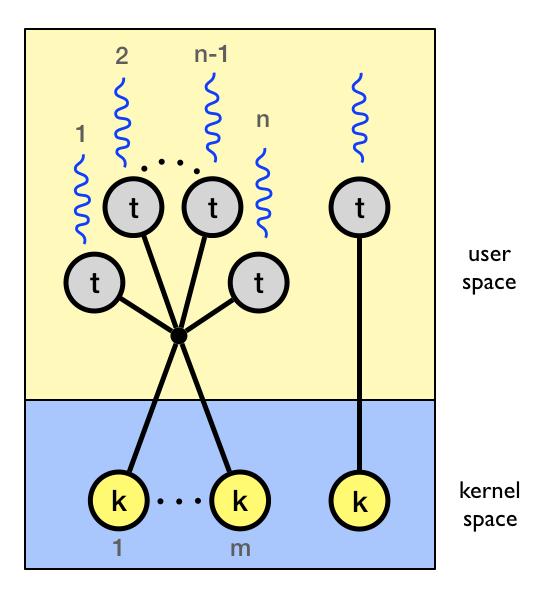
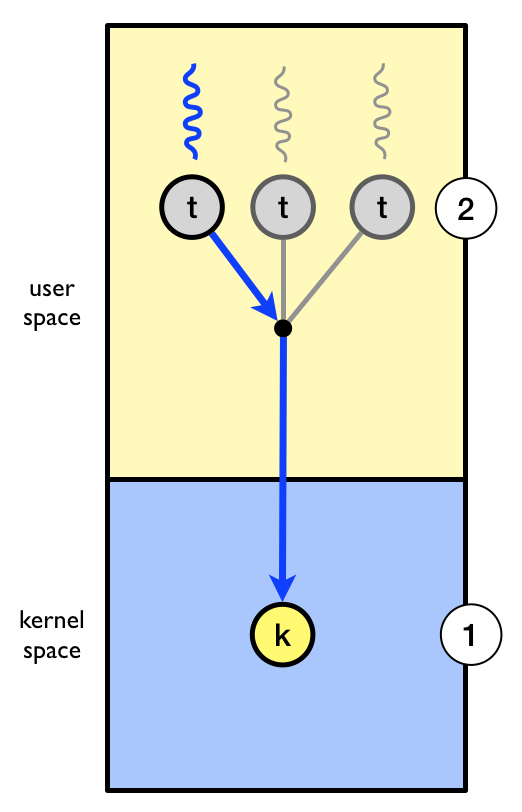
Job 2 is ready to run and job 1 is running.
Job 1 uses the getc system call to read a character from the
keyboard.
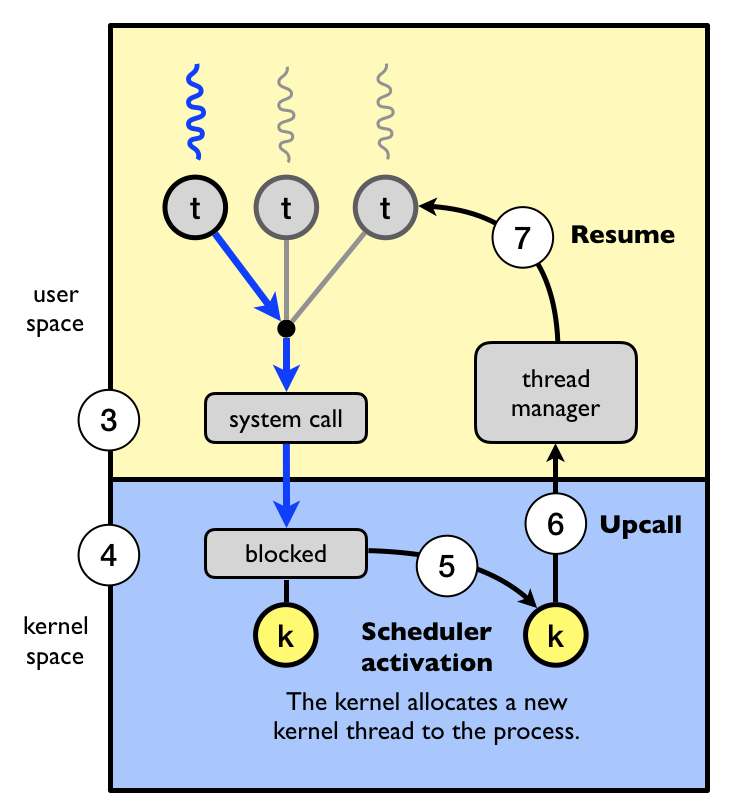
The system call uses a system call exception to enter the kernel.
The kernel saves the context (all register values) of job 1.
The kernel now knows that job 1 waits for input and changes its state from
running to waiting.
The kernel restores the context of job 2.
The kernel resumes execution of job 2. Job 1 and changes its state from
ready to running.
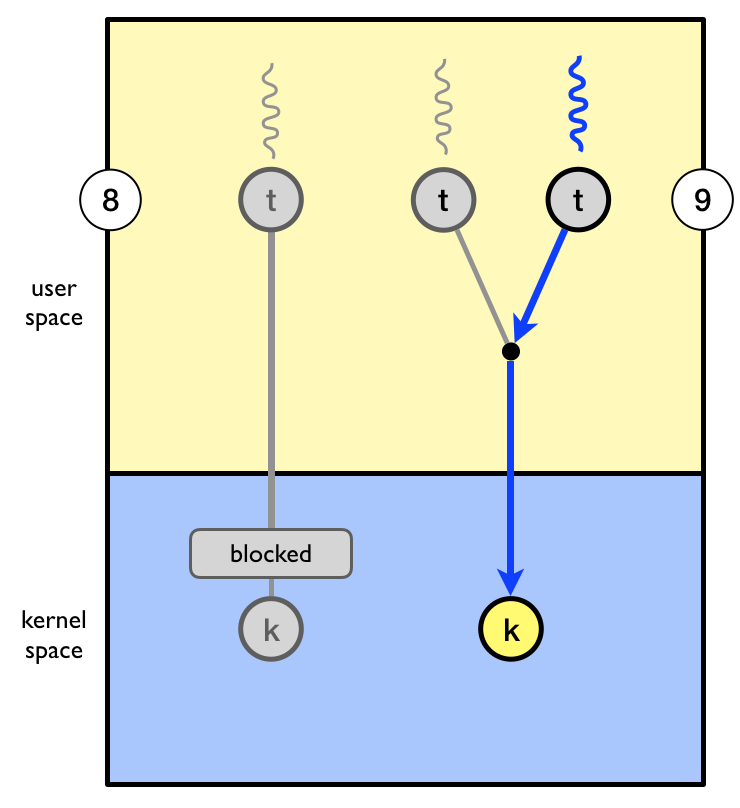
The human user presses a key on the keyboard.
The key-press causes a keyboard interrupt which is handled by the kernel.
The kernel saves the context of job 2 and changes its state from
running to ready.
The kernel knows that job 1 waits for the getc system call to complete.
The kernel restores the context of job 1 and changes its state from
waiting to running.
The ASCII value of the pressed key is made available to job 1.
The kernel resumes execution of job 1.
Multiprogramming
The result of the getc system call can not be obtained immediately, the kernel
must wait for the user to press a key on the keyboard. When handling the getc
system call, the kernel blocks the caller and make another job run until the
user presses a key on the keyboard.
Null-terminated strings
A null-terminated string is a character string stored as an array containing
the characters and terminated with a null character\0.
1
Read string system call design
We have already studied how interrupts can be used to wait for a single keypress
from a human user. How can we design a system call for inputting a string?
To input a string we simply needs to wait for each keyboard interrupt and
save the characters in an array (buffer).
When the user presses enter (or there is no more space in the buffer) the
buffer is terminated with null.
Input buffer
Where should the input buffer be allocated? In user space or in kernel space?
Memory safety
It is not desirable for a user program to be able to read arbitrary data
stored in the kernel.
A user program could (possibly by mistake) corrupt the kernel by
writing data outside the input buffer. This is called buffer overflow.
To enforce memory safety user programs are not allowed to access (read or write)
kernel data but the kernel is allowed to read and write data in user space.
Buffer pointer
The kernel must know the address (pointer) to the input buffer in user space.
Buffer size
The kernel must know the size of the input buffer and decide what to do when the
buffer is full.
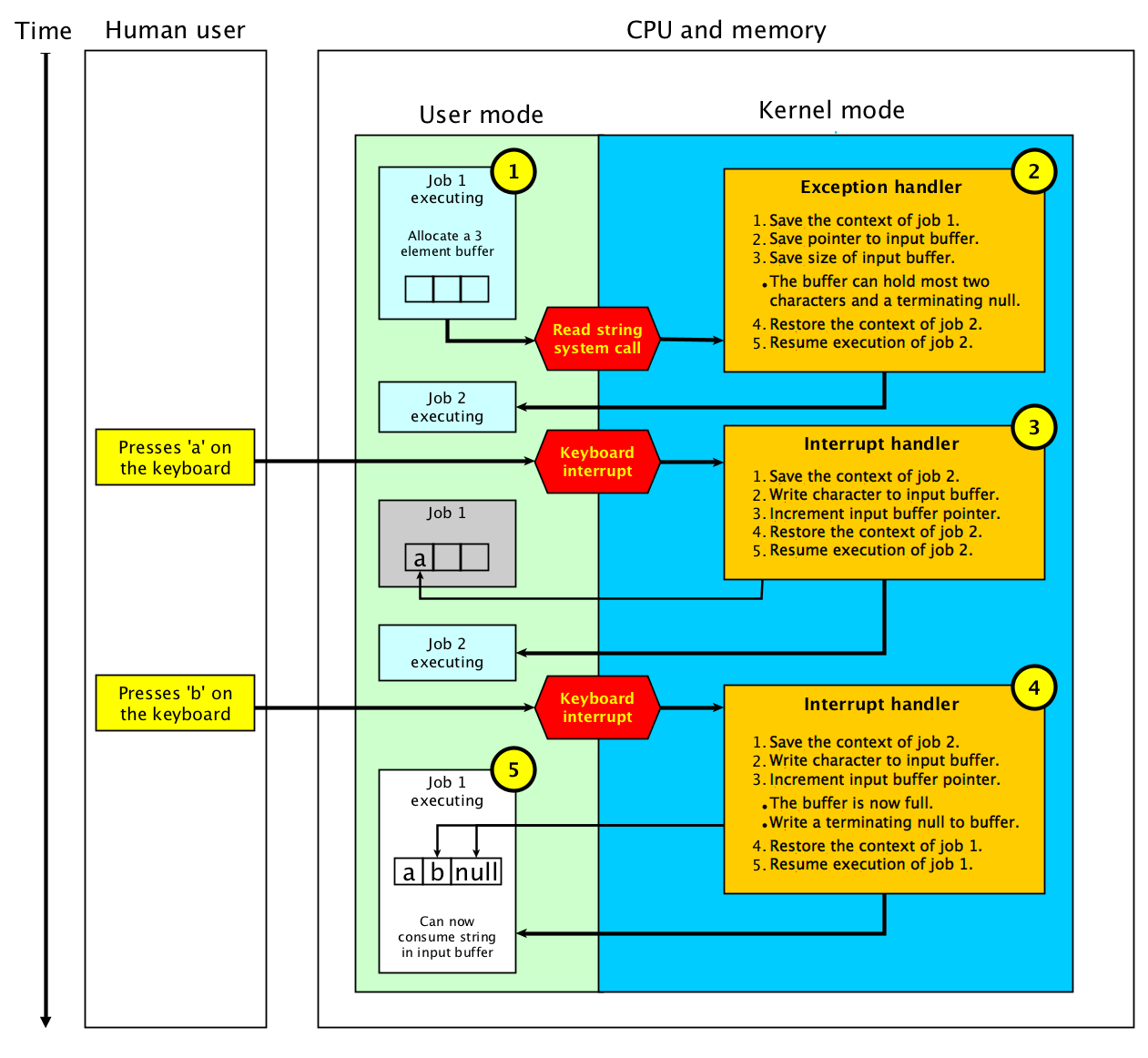
Read string system call example
To better understand the details of how the read string system call can be
implemented we will study a small example with two jobs. In this example, job 1 allocates a
3 element input buffer and uses a system call to request the operating
system to wait (using interrupts) for the user to fill this buffer with two
characters and terminate the buffer with null. Until the input buffer is full
the operating system (kernel) let job 2 execute between keyboard
interrupts.
System call convention
A common pattern for system calls and other library functions is for the caller
to allocate a struct or array in user space. The caller pass a pointer to the struct or array as an
argument to the system call or library function call. The system call or library
function writes result data to the struct or array in user space using the
provided pointer.
An alternative to the above patterns would be to return data (structure or array
elements) on the stack. So
why are pointers (call by reference) used instead of returning on the stack?
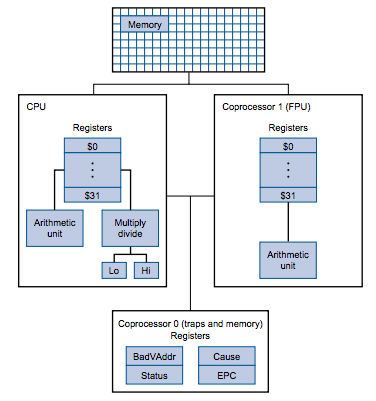
A MIPS processor consists of an integer processing unit (the CPU) and a
collection of coprocessors that perform ancillary tasks or operate on other
types of data such as floating-point numbers.
Integer arithmetic and logical operations are executed directly by the CPU.
Floating point operations are executed by Coprocessor 1. Coprocessor 0 is used
do manage exceptions and interrupts.
Normal user level code doesn’t have access Coprocessor 0, but interrupt and
exception aware code has to use it. Coprocessor 0 has several registers which
controls exceptions and interrupts.
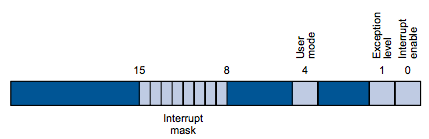
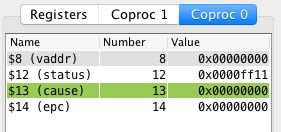
Status (register 12)
The coprocess 0 status register is a read-write register used to enable or disable various types of interrupts.
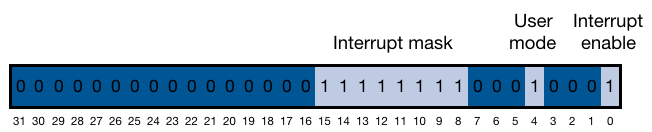
Interrupt enable
If the interrupt enable bit is 1, interrupts are allowed. If it is 0, they are disabled.
Exception level
The exception level bit is normally 0, but is set to 1 after an exception
occurs. When this bit is 1, interrupts are disabled and the EPC is not updated
if another exception occurs. This bit prevents an exception handler from being
disturbed by an interrupt or exception, but it should be reset when the handler
finishes.
User mode
The user mode bit is 0 if the processor is running in kernel mode and 1 if it is
running in user mode.
User mode fixed to 1 in Mars and Spim
Neither Mars nor Spim implements kernel mode and fixes the user mode bit to 1.
Interrupt mask
The 8 bit interrupt mask 8 field contains one bit for each of the 6 hardware level interrupts and the 2
software level interrupts. A mask bit set to 1 allows interrupts at that level
to interrupt the processor. A mask bit set to 0 disables interrupts at that
level.
Hardware interrupt level
Used for
Mars
Spim
Bit nr.
Bit mask
Bit nr.
Bit mask
0
Transmitter (terminal output)
9
0x00000200
10
0x00000400
1
Receiver (keyboard interrupt)
8
0x00000100
11
0x00000800
5
Timer
Not supported
15
0x00008000
Startup value
On startup the status register has the following value.
Register
MARS
SPIM
Status
0x0000ff11
0x3000ff10
To see which bits are set in the status register on startup we must translate the hexadecimal startup value to binary.
From hexadecimal to binary
When translating from hexadecimal to binary we do this by translating each hexadecimal digit to a four bit binary value.
0x0 = [binary] = 0000
0x1 = [binary] = 0001
0xf = [binary] = 1111
Next, we replace each hexadecimal digit with the corresponding four bit binary
number.
Mars initializes the status register in coprocessor 0 to 0x0000ff11 = [binary] = 0000 0000 0000 0000 1111 1111 0001 0001.
On startup:
Interrupts are enabled.
User mode is set to 1.
All interrupt mask bits are set to 1.
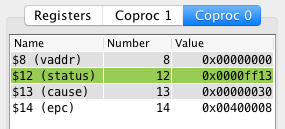
Cause (register 13)
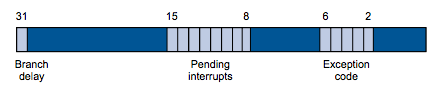
The Cause register, is a mostly read-only register whose value is set by the
system when an interrupt or exception occurs. It specifies what kind of
interrupt or exception just happened.
When an exception or interrupt occur, a code is stored in the cause register as
a 5 bit value (bits 2-6). This field is commonly referred to as the exception
code although it is used for both exceptions and interrupts.
Exception code
Name
Cause of exception
0
Int
Interrupt (hardware)
4
AdEL
Address Error exception (Load or instruction fetch)
5
AdES
Address Error exception (Store)
6
IBE
Instruction fetch Buss Error
7
DBE
Data load or store Buss Error
8
Sys
Syscall exception
9
Bp
Breakpoint exception
10
RI
Reversed Instruction exception
11
CpU
Coprocessor Unimplemented
12
Ov
Arithmetic Overflow exception
13
Tr
Trap
14
FPE
Floating Point Exception
EPC (register 14)
Exception Program Counter (EPC) register. When an interrupt or exception occurs,
the address of the currently executing instruction is copied from the Program
Counter (PC) to EPC. This is the address that your handler jumps back to when it
finishes.
Timer (register 9 and 11)
In SPIM, a timer is simulated with two more coprocessor registers: Count
(register 9), whose value is continuously incremented by the hardware, and
Compare (register 11), whose value can be set. When Count and Compare are
equal, an interrupt is raised, at Cause register bit 15.
To schedule a timer interrupt, a fixed amount called the time slice (quantum) is
stored in the Compare register. The smaller the time slice, the greater the
frequency of timer interrupts.
No timer in Mars
Timer interrupts are yet not implemented in MARS.
Accessing registers in Coprocessor 0
To access a register in Coprocessor the register value must be transferred from
Coprocessor 0 to one of the regular CPU registers. To update one of the
registers in Coprocessor 0 a value in one of the of the regular CPU register in
the CPU must be transferred to to one of the Coprocessor 0 registers.
If you want to modify a value in a Coprocessor 0 register, you need to move the
register’s value to a general- purpose register with mfc0, modify the value
there, and move the changed value back with mtc0.
mfc0
The mfc0 (Move From Coprocessor 0) instruction moves a value from a Coprocessor 0 register to a general-purpose register.
Example:
mfc0$t5, $13# Copy $13 (cause) from coprocessor 0 to $t5.
mtc0
The mtc0 (Move To Coprocessor 0) instruction moves a value from a
general-purpose register to a Coprocessor 0 register.
Example:
mtc0$v0, $12# Copy $v0 to $12 (status) in coprocessor 0.
In order to study exceptions and interrupts we will use the Mips 32 simulator
Mars. All instructions will be written for and tested using Mars but you
should be able to use the Spim simulator if you prefer.
Mips system architecture
A Mips processor consists of an integer processing unit (the CPU) and a
collection of coprocessors that perform ancillary tasks or operate on other
types of data such as floating-point numbers.
Both Mars and Spim
simulates two coprocessors:
Coprocessor 0 handles exceptions and interrupts.
Coprocessor 1 is the floating-point unit.
Integer arithmetic and logical operations are executed directly by the CPU.
Floating point operations are executed by Coprocessor 1. Coprocessor 0 are used
do manage exceptions and interrupts.
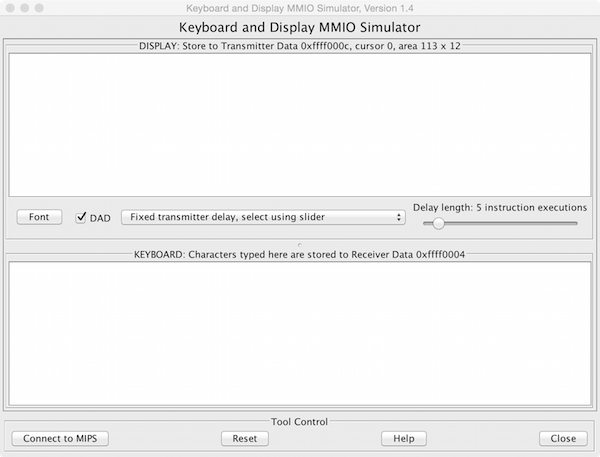
Receiver and transmitter
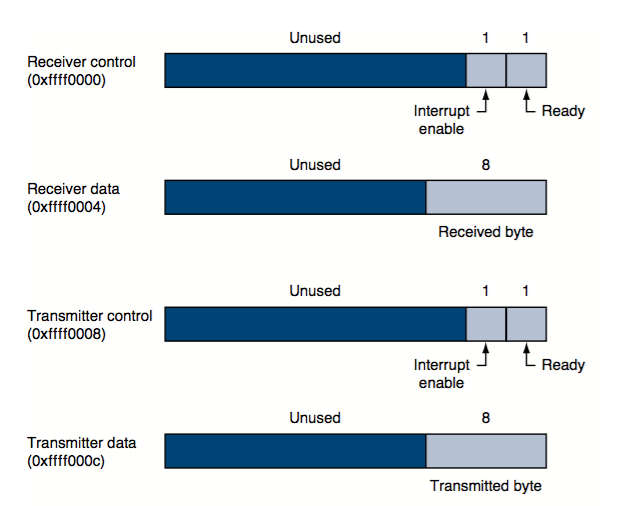
Mars simulates one I/O device: a memory-mapped console on which a
program can read and write characters. The terminal device consists of two
independent units: a receiver and a transmitter.
The receiver reads characters typed on the keyboard.
The transmitter display characters on the console.
Echo
The receiver and transmitter are completely independent. This means, for example, that
characters typed at the keyboard are not automatically echoed on the display.
Instead, a program must explicit echo a character by reading it from the receiver and
writing it to the transmitter.
Memory layout
To execute a Mips program memory must be allocated. The Mips computer can
address 4 Gbyte of memory, from address 0x0000 0000 to 0xffff ffff. User memory
is limited to locations below 0x7fff ffff. In the below figure the layout of the
memory allocated to a Mips program is shown.
The purpose of the various memory segments:
The user level code is stored in the text segment.
Static data (data know at compile time) use by the user program is stored
in the data segment.
Dynamic data (data allocated during runtime) by the user program is stored
in the heap.
The stack is used by the user program to store temporary data during for
example subroutine calls.
Kernel level code (exception and interrupt handlers) are stored in the
kernel text segment.
Static data used by the kernel is stored in the kernel data segment.
Memory mapped registers for IO devices are stored in the memory mapped IO
segment.
Memory-mapped terminal device
A program controls the terminal with four memory-mapped device registers.
Memory-mapped means that each register appears as a special memory location. In
this sense, these are not real registers but simply words (32 bit) values stored
in memory.
Receiver control
The Receiver Control register is at memory location 0xffff0000. Only two of its
bits are actually used.
Bit 0 is called ready:
If it is 1, it means that a character has arrived from the keyboard but has not
yet been read from the Receiver Data register.
The ready bit is read-only: writes to it are ignored.
The ready bit changes from 0 to 1 when a character is typed at the key- board,
and it changes from 1 to 0 when the character is read from the Receiver Data
register.
Bit 1 is the keyboard interrupt enable bit:
This bit may be both read and written by a program.
The interrupt enable is initially 0.
If it is set to 1 by a program, the terminal requests an interrupt at hardware
level 1 whenever a character is typed and the ready bit becomes 1. However,
for the interrupt to affect the processor, interrupts must also be enabled in
the Status register.
All other bits of the Receiver Control register are unused.
Receiver data
The second terminal device register is the Receiver Data register at memory
address 0xffff0004.
The low-order 8 bits of this register contain the last character typed at the
keyboard. All other bits contain 0s.
This register is read-only and changes only when a new character is typed at
the keyboard.
Reading the Receiver Data register resets the ready bit in the Receiver
Control register to 0.
The value in this register is undefined if the Receiver Control register is 0.
Transmitter control
The third terminal device register is the Transmitter Control register at memory
address 0xffff0008. Only the low-order 2 bits of this register are used. They
behave much like the corresponding bits of the Receiver Control register.
Bit 0 is called ready:
This bit is read-only.
If this bit is 1, the transmitter is ready to accept a new character for output.
If it is 0, the transmitter is still busy writing the previous character.
Bit 1 is the interrupt enable bit:
This bit is readable and writable.
If this bit is set to 1, then the terminal requests an interrupt at hardware
level 0 whenever the transmitter is ready for a new character and the ready
bit becomes 1.
Transmitter data
The final device register is the Transmitter Data register at memory address
0xffff000c.
Only the least 8 significant bits (the least significant byte) are used:
When a value is written into this location, its low-order 8 bits (i.e., an
ASCII character) are sent to the console.
When the Transmitter Data register is written, the ready bit in the
Transmitter Control register is reset to 0. This bit stays 0 until enough time
has elapsed to transmit the character to the terminal; then the ready bit
becomes 1 again.
The Transmitter Data register should only be written when the ready bit of the
Transmitter Control register is 1. If the transmitter is not ready, writes to
the Transmitter Data register are ignored (the write appears to succeed but
the character is not output).
Timing
In a physical computer sending a character to the terminal doesn’t happen
instantly, the operation takes some time to complete.
The simulators Mars and SPIM measures time by counting the number executed instructions
, not in real clock time. After writing a character to the receiver data register, this means that the transmitter does not
become ready again until the processor executes a fixed number of instructions.
If you stop the simulation and look at the ready bit, it will not change. However,
if you let the simulation continue, the bit eventually changes back to 1.
If you run macOS and tree is not installed, use Homebrew to install tree.
brew install tree
Introduction to exceptions and interrupts in Mips
Mandatory assignment
Learning outcomes
In this assignment you will study the differences between exceptions and
interrupts and how to implement a simple exception and interrupt handler. You
will also study how both exceptions and interrupts causes a transfer of control from
user mode to kernel mode and back to user mode after the exception or interrupt
have been handled by the kernel.
Method
To study exception and interrupt handling you will load a small Mips assembly
program into the Mips simulator Mars. The program will deliberately trigger the
following exceptions:
Arithmetic overflow.
Address error.
Trap.
By single-stepping the program you will examine in detail what actions are taken
in order to handle each exception.
You will also study keyboard interrupts and how this can be used make the CPU do
something different while waiting for user input.
To get a fully working system you must add or change the provided code at a few
places.
Preparations
Before you continue you must perform the following preparations.
Learn about Mips and Mars
If you haven’t done so already, go through the introduction
to Mips and Mars.
Install Mars on your private computer
Mars will run on any system (including Windows) as long as you
have [Java installed][java-install]. If you prefer, you may download
and install Mars on your private computer.
If you don’t have Mars installed on your private computer, you can log in to the department Linux system and start Mars from the Applications menu under Programming.
Mars should now start and you should see something similar to this.
Open file
Open the file mandatory/exceptions-and-interrupts.s in Mars.
Study the source code
Study the assembly source code of the loaded program in the built in editor
pane.
A brief overview
Read the code with the intention of
getting an overview of the overall structure. Focus on labels and jumps to
labels. Focus on the difference between the user text segment (.text) and
kernel text segment (.ktext). You will study the details later.
Don’t edit the source
You should not edit the source code at this stage.
User level code
After an introductory comment you find the .text assembler directive followed by
the label main which is the entry point of the user mode program. In main:
First an arithmetic overflow exception is triggered by adding 1 to the
largest positive 32 bit two’s complement value 0x7fffffff.
Next an address error exception is triggered by trying to load a value from an invalid memory address (address 0).
Finally, a trap exception is triggered using the teqi (Trap EQual Immediate) instruction.
At the end of main the program enters an infinite loop incrementing a counter
(register $s0).
Kernel level code
The assembler directive .ktext 0x80000180 instructs the assembler to place the
generated machine instructions in the kernel text segment starting at memory
address 0x80000180. Here the label __kernel_entry_point marks the entry point
of the exception handler (kernel). Note that this label is not needed but simply
included to make it obvious to a human reader where the exception handler
starts.
When an exception or interrupt occurs, the address of the program counter of
the currently executing program is automatically saved to the EPC register in
coprocessor 0 and control is transferred from user mode to kernel mode.
When entering the kernel, the kernel must determine whether this due to an
an exception or an interrupt.
First the kernel loads the value of the cause register from coprocessor 0.
Next the exception code is extracted from the cause register. The exception
code will be zero for an interrupt and non-zero for an exception.
Using a conditional branch execution will continue at the label __interrupt
for an interrupt and at label __exception for an exception.
For an exception, the exception code must be further examined to distinguish
between different exceptions. For interrupts the pending interrupt bits in the
cause register is used to distinguish between different interrupts. At the end
of the kernel text segment at label __resume, execution is resumed in user
mode at the address saved in the EPC register in coprocessor 0.
Adjust the run speed
Adjust the simulated run speed to 25 inst/sec or lower.
First test run
Before you continue, clear both the Mars Messages and Run I/O.
Assemble the file by clicking on the icon with the screwdriver and wrench.
You should see something similar to the following in the Mars Messages display pane.
Spend some time to see if you can come up with an explanation as to why the same
error message printed over and over again.
Click on the stop button to stop the simulation.
Before you continue, clear both the Mars Messages and Run I/O.
Pseudo instructions
In the Execute pane the source instructions are shown in the Source column and
the actual instructions produced by the assembler are shown in the Basic column.
Note that the first source instruction li $s0, 0x7fffffff is a pseudo
instruction that is translated to one lui instruction and one ori instruction,
both using the $at (Assembler Temporary) register, i.e., register $1.
Arithmetic overflow step by step
It is now time to study the execution in more detail by execute one instruction
at the time using the single step button .
Assemble the file.
The largest positive integer
The program starts by storing the largest 32 bit
positive two’s complement
integer in register $s0
using the li (Load Immediate) instruction. This instruction is a pseudo
instruction and translates to one lui instruction and one ori instruction.
Execute the li $s0, 0x7fffffff instruction.
Now, look at the register pane.
Note that register $at (register number 1) have been highlighted and that the value stored in $at
changed from the initial value 0x00000000 to 0x7fff0000 , i.e., the upper
half of the 32 bit value 0x7fffffff is now stored in $at.
Execute the ori $16, $1, 0x000ffff instruction.
Now $s0 (register number 4) will be highlighted in the register pane.
Register $s0 now holds the value value 0x7fffffff = [32 bit binary] = 0111 1111 1111 1111 1111 1111 1111 1111, i.e., the largest positive 32 bit
two’s two’s complement
integer.
The program counter
The program counter stores the address of the next instruction to execute.
In the register pane, look at the value of the program counter pc. We see that
pc = 0x00400008. Also note that in the execute pane the instruction at this
address is now highlighted.
The cause register
In the Coproc 0 tab in the register pane, look at the cause register (register
13).
The value in the cause register is currently 0x00000000.
Adding one
We will now try to add the value one (1) to the integer stored in $s0.
Execute the addi $s1, $s0, 1 instruction.
The program counter have now jumped from 0x00400008 to 0x80000180, i.e.,
execution has transition to the kernel entry point. Now the status
register (register 12) is highlighted in the register pane.
Note that the cause register changed from 0x00000000 to 0x00000030 and
that EPC have been set to
0x00400008, i.e., been set to the address of the addi instruction causing
the overflow exception.
Step backwards and forwards
One great feature of the Mars simulator is the possibility to execute the program backwards.
Undo the execution of addi $s1, $s0, 1 instruction by clicking on the undo
button.
Study the values of the program counter, the cause register and the EPC register.
Execute the addi $s1, $s0, 1 instruction.
Keep undo and redo the execution of the addi instruction and make sure you
understand that this addition causes a transfer of control from user mode to
kernel mode due to an overflow exception and that information about the
exception is stored in the cause register. When the exception happens, the
address of the faulty instruction is automatically saved in the EPC register.
Transition from user mode to kernel mode
As a consequence of the overflow exception, execution has now transition from
user mode to kernel mode. Execution now continues in the .ktext segment at the
label __kernel_entry_point at address 0x80000180.
Get the value in the cause register
To investigate what caused the transfer from user mode to kernel mode, the
kernel must fetch the value of the cause register from coprocessor 0.
Execute the mfc0 $k0, $13 instruction.
In the register pane register $k0 should now be highlighted with value
0x00000030 = [binary] = 0000 0000 0000 0000 0000 0000 0011 0000, i.e, a copy of the cause register.
Mask all but the exception code (bits 2 - 6) to zero
The bits of the cause registers have different meaning.
In general, we can’t be sure if other bits than the exception code bits (bits
2 - 6) are set in the cause register. To set all bits but the exception code
bits (bits 2 -6) to zero, the bitmask0x0000007C = [binary] = 0000 0000 0000 0000 0000 0000 0111 1100 is used together with bitwise and (andi).
Execute the andi $k1, $k0, 0x00007c instruction.
In the register pane, register $k1 should now have value 0x00000030 =
[binary] = 0000 0000 0000 0000 0000 0000 0011 0000.
Shift two steps to the right
To get the value of the exception code we need to shift the value in $k1 two
steps to the right.
Execute the srl $k1, $k1, 2 instruction.
Register $k1 now hold the exception code = 0x0000000c =
[binary] = 0000 0000 0000 0000 0000 0000 0000 1100 = [decimal] = 12.
Interrupt or exception
The exception code is zero for an interrupt and none zero for all exceptions.
The beqz instruction is now used to jump to the label __interrupt if the
exception code in $k1 is zero, otherwise execution continues on the next instruction.
Execute the beqz $k1, __interrupt instruction.
The exception code is non zero and the branch is not taken.
Branch depending on the exception code
Next the beq instruction is used to make a conditional jump to the label
__overflow_exception if the exception code in $k1 is equal to 12.
Execute the pseudo instruction beq $k1, 12, __overflow_exception by clicking twice on step the step forward button.
The branch is taken and execution continues at label __overflow_exception.
Print error message
Next a “magic” Mars builtin system call is used to print the error message
"===> Arithmetic overflow <===\n\n" stored as a null terminated string in
the .kdata segment at label OVERFLOW_EXCEPTION.
Mars magic
Unfortunately the built-in system calls in Mars are implemented as part of the
underlying Mips emulator. You cannot single-step the built-in system calls to
see how they are implemented. Hence they provide us with a little magic that we
cannot study or modify.
Single step four times execute the magic print
string system call.
In the Run I/O pane you should now see the following message.
===> Arithmetic overflow <===
Next an unconditional jump to label __resume_from_exception is done.
Execute the j __resume_from_exception instruction.
Resume from exception
Execution now continues at the label __resume_from_exception. Next the value
of the EPC register is fetched from the coprocessor 0 register $14 to the
CPU register $k0.
Execute the mfc0 $k0, $14 instruction.
Register $k0 now have the value 0x00400008. This is the address that was
automatically stored in EPC when the overflow exception occurred, i.e., the
address of the instruction causing the overflow exception.
Next, the value in the $k0 register is stored back to the EPC register in
coprocessor 0.
Execute the mtc0 $k0, $14 instruction.
Transfer control back to user mode
The exception have now been handled by the kernel. The last thing to be done is
to transfer control back to user mode using the eret instruction which makes
and unconditional jump to the address currently stored in EPC.
Execute the eret instruction.
Full circle
Execution now continues in user mode at the same instruction that caused the
overflow exception in the first place.
Click on the play button to continue execution. Don’t use the single-step
button, use the play button.
In the Run I/O display window you should see the following output.
The same message is printed repeatedly in the Run I/O display.
Click on the stop button to stop the simulation.
Solution
When resuming execution after an exception, we want to resume at the instruction
following the instruction at the address saved in EPC.
Each instruction is four bytes, hence we need to add four to EPC before
executing eret.
Click on edit to show the source code.
Press Ctrl-F and search for todo_1.
Uncomment the following line to add four to the EPC value.
#addi$k0, $k0, 4# TODO: Uncomment this instruction
Assemble the file.
Before you continue, clear both the Mars Messages and Run I/O.
Click on the play icon to run the program to completion.
In the Run I/O display window you should see the following output.
This time there is exactly one arithmetic overflow error message followed by two
messages about unhandled exceptions.
Infinite loop
The program is now stuck in the infinite loop at label infinite_loop. In the
register pane you should be able to see how the value of register $s0 is
constantly increasing.
Click on the stop button to stop the simulation.
Address error and trap exceptions
At label todo_2 you must add code to:
Branch to label __bad_address_exception for exception code 4.
Branch to label __trap__exception for exception code 13.
Assemble the file.
Before you continue, clear both the Mars Messages and Run I/O.
Click on the play icon to run the program to completion.
In the Run I/O display window you should see the following output.
===> Arithmetic overflow <===
===> Bad data address exception <===
===> Trap exception <===
Pause the simulation
This time you should not halt the simulation, instead you should pause the
simulation.
Click on the pause button to pause the simulation.
Keyboard interrupts
We will now make the keyboard generate an interrupt for each keypress. In order
to do this we must first setup the Mars MMIO simulator.
Enable the Keyboard and display MMIO simulator
To make MARS simulate the memory mapped keyboard receiver (and display
transmitter) you must enable this feature.
Open the Keyboard and Display MMIO Simulator window
From the Tools menu, select Keyboard and Display MMIO Simulator.
A new window should now open.
The lower white area of this window is the simulated keyboard.
Connect to MIPS
To make MARS aware of the simulated memory mapped receiver (keyboard), press the
Connect to MIPS button in the lower left corner of the Keyboard and Display
MMIO Simulator window.
Resume the simulation
Now you can resume the simulation.
Click on the play icon to resume the simulation.
Infinite loop
The program is now stuck in the infinite loop at label infinite_loop. In the
register pane you should be able to see how the value of register $s0 is
constantly increasing.
Type on the simulated keyboard
Click inside the lower white area of the MMIO simulator window and type a few
characters.
Nothing happens, the program is still stuck in the infinite loop.
Stop the simulation
Before you continue, make sure to stop the simulation.
Click on the stop button to stop the simulation.
Enable keyboard interrupts
At label todo_3 you must add code to enable keyboard interrupts. The simulated
keyboard is configured by setting bits in the memory mapped transmitter control
register which appears at address 0xffff0000.
To make the keyboard generate interrupts on keypresses, the bit 1 of receiver
control must be set to 1.
Assemble the file.
Click on the play icon to run the program to completion.
Type on the simulated keyboard
Click inside the lower white area of the MMIO simulator window and type a
single character.
When you type a character on the simulated keyboard a keyboard
interrupt is generated. The interrupt is handled by the kernel.
Adjust the run speed
Adjust the run speed to a slower speed in order to see how the asynchronous
keyboard interrupt causes control to be transferred from the user level infinite
loop to the kernel where the interrupt is handles and then back to the user
level infinite loop.
Click on the stop button to stop the simulation.
Known bug in Mars
There is a conflict between the built-in system call 12 read_char and the
Keyboard and Display MMIO Simulator.
Mars may hang
If the Keyboard and Display MMIO Simulator is open and connected, Mars
hangs if the user types a character on the simulated keyboard while Mars
waits for input using the built-in system call 12 read_char.
Echo
The ASCII value of the pressed key is stored in the memory mapped receiver data
register.
At label todo_4 you must uncomment a number of instructions to load the
ASCII value from receiver control and print it to Run I/O using the Mars builtin
system cal.
Assemble the file.
Click on the label __todo_4 in the labels window.
The instruction at label __todo_4 is now highlighted in the Execute pane. Add
a breakpoint at this address by checking the checkbox in the leftmost
Bkpt column.
Click on the play icon to run the program to completion.
Once again, execution is stuck in the infinite loop incrementing the $s0
register.
Type on the simulated keyboard
Click inside the lower white area of the MMIO simulator window and type a
single character.
Execution paused at the breakpoint
When you type a character on the simulated keyboard a keyboard
interrupt is generated. The interrupt is handled by the kernel and execution is
paused at the breakpoint.
Single step
Continue by single stepping and try to understand how the keyboard interrupt is
handled by the kernel and execution resumes in the user mode infinite loop after
the keyboard interrupt has been handled.
Once the keyboard interrupt have been handled you should see the pressed
character printed to Run I/O display.
Repeat
Now you can press play again, press a key on the
simulated keyboard and single step after the breakpoint. Repeat a few times to
make sure you understand how the keyboard interrupt is handled.
Conclusions
Interrupts and exceptions are used to notify the CPU of events that needs
immediate attention during program execution. Exceptions and interrupts are events that alters the normal sequence of
instructions executed by a processor.
Exceptions are internal and synchronous
Exceptions are used to handle internal program errors.
Overflow, division by zero and bad data address
are examples of internal errors in a program.
Another name for exception is trap. A trap (or exception) is a
software generated interrupt.
Exceptions are produced by the
CPU control unit while executing instructions and are considered to be
synchronous because the control unit issues them only after terminating the
execution of an instruction.
Interrupts are external and asynchronous
Interrupts are used to notify the CPU of external events.
Interrupts are generated by other hardware devices
outside the CPU at arbitrary times with respect to the CPU clock signals and are
therefore considered to be asynchronous.
Key-presses on a keyboard might happen at any
time. Even if a program is run multiple times with the
same input data, the timing of the key presses will
most likely vary.
Preparations for the code grading
This assignments is constructed more or less as a step-by-step tutorial. The
purpose of the code grading is not for you (the student) to show the
teaching staff that you got something to work as required.
The focus is for you to be able to explain and discuss what you’ve done and what you learnt.
In preparation for the code grading:
Make sure you understand as much as possible of all the details.
Single step the code in Mars.
Read all the provided comments.
Try to understand what happens in each step.
Focus on the fundamental concepts
During the code grading you will be:
Asked to show the code in Mars for the mandatory assignment.
Asked to test run your solution step-by-step in Mars.
Asked questions about the following core concepts and how they relate to the assignment:
Data segment
Text segment
Stack
Heap
Registers
PC
Global variables (data segment)
Local variables (stack)
The difference between exceptions and interrupts
EPC
CAUSE
Bitmaskning and bit shifting
Resuming from handling an exception or interrupt (should 4 always be added to EPC before resuming or not?)
Example of questions
Examples of questions you could be asked during the code grading.
In (Mips) Assembly, what are labels?
What actions are unconditionally taken by the MIPS CPU when an exception/interrupt occurs?
How do you determine if an exception or interrupt caused the transition to the kernel entry point?
In the original code you where given, the same exception was happening again and again and again in an infinite loop. Why? How to avoid this?
When you run the system in Mars, why is the $s0 register incrementing?
What pedagogical purpose do you think this incrementing loop serves?
For interrupts, how do you determine if it actually was a keyboard interrupt?
Why do you think the exception code uses a 5 bit numeric field allowing for 32 different kinds of exceptions and interrupts uses 8 pending bits, one each for the 8 types of - interrupts only allowing for 8 types of interrupts and not 2^8 = 256 types of interrupts?
How are you able to know which key was pressed?
Multiprogramming and custom system calls in Mips
Optional assignment for higher grade (3 points)
The Mars built-in system calls
Previously you have used a number
of system calls built in to MARS, for example to print
strings and integers. Before calling any of the Mars built-in system calls, the system call code is placed
in $v0. Next, the syscall instruction is used to invoke the system call.
In a real Mips system, the syscall instruction triggers a system call
exception (exception code 8) that causes control to be transferred from user
space to kernel space where the system call is handled. The kernel investigates
the value in $v0 to determine which specific system call the user requested.
In Mars the built-in system calls are handled by the simulator and not by the
kernel (exception and interrupt handler) code that you can study and modify. Unfortunately
this makes it impossible to provide custom implementations of system calls using
the syscall instruction.
No more magic
After all, this is a course about operating systems and we cannot be satisfied
with the magic provided by the system calls built in to Mars. It is now time to
implement our own custom system calls from scratch.
Timer interrupts
Unfortunately, Mars does not support timer interrupts. This makes it impossible
for the kernel to to use a timer to swap between running jobs at regular
intervals.
Multiprogramming
For the higher grade assignment you should implement a simplified version
of multiprogramming.
System overview
An overview of the system is shown in the below figure.
For simplicity there will be exactly two jobs in the system. The kernel will implement three custom system calls: getjid, getc and
gets. The kernel will use multiprogramming to switch job only when a job
requests I/O using the getc or gets system call.
Two non-terminating jobs
To make the system as simple as possible, the kernel only need to support two
non-terminating jobs. Only one job can execute on the CPU at the time.
Job id (jid)
The two jobs are identified by job id (jid) numbers 0 and 1 respectively.
No stack and no subroutines
To keep the system simple the jobs cannot use the stack nor can they make
subroutine calls.
No memory protection
Mars does not support any form of memory protection. As a consequence there will be no
memory protection between user space and kernel, nor will there be any memory
protection between jobs. Thetwo jobs:
execute in the same memory space
share the same data segment.
Only one job can request I/O
The whole purpose of multiprogramming is to maximize the usage of the CPU. A job
executes on the CPU until requesting I/O. When requesting I/O the job is blocked
waiting for the I/O request to complete. While waiting the other job executes
on the CPU.
In this simplified system, only one of the two non-terminating jobs can request
I/O. While a job is waiting for the I/O request to complete the other job
executes on the CPU.
States
At any time, each of the two non-terminating jobs job can be in one of the
following three states.
Running
The job is selected to execute on the CPU.
Ready
The job is not selected to execute on the CPU but ready to do so if selected.
Waiting
The job has made a request for I/O using either getc or gets and s blocked
from executing until the the request have been completed.
On startup of the system (boot) one job is selected to execute (running) and
the other is marked as ready to run.
State transitions
In this simplified version of a a multiprogramming system with only two jobs,
the following state transitions are possible.
From
To
Description
Running
Waiting
When the running job requests I/O, the job changes state from running to waiting.
Running
Ready
When an I/O requests completes, the running job changes state from running to ready.
Waiting
Running
When an I/O requests completes, the job waiting for the request to complete changes state from waiting to running.
In the below diagram a sequence of five events shows how the two jobs change
states.
Kernel
In this system the kernel is responsible for handling all exceptions and
interrupts. The kernel will also be responsible for managing the execution
of the two jobs.
Kernel stack
In order for the kernel to be able to use subroutines, the the kernel will
allocate a stack.
Job context
When a job executes it uses the CPU registers. At any time, the values of all
the registers is called the context of the running job.
In this simplified system each job is only allowed to use the following six
registers: $pc (program counter), $v0, $a0, $a1, $s0 and $at (should only
be used by pseudo instructions).
Each register is four byte, hence 6*4 = 24 bytes of storage is needed to store
the context. The contents of the registers are saved in the following order in each job
context.
Addressing the context
If the address to a context is in register $t0, the address to each of the
fields in the context is shown in the column Assembly notation in the
following table.
Field
Offset
Address
Assembly notation
$pc
0
$t0 + 0
0($t0)
$v0
4
$t0 + 4
4($t0)
$a0
8
$t0 + 8
8($t0)
$a1
12
$t0 + 12
12($t0)
$s0
16
$t0 + 16
16($t0)
Examples
In the following examples, the address to a context is in register $t0.
sw$t1, 8($t0) # Store $t1 to the $a0 field in the context.
lw$t2, 16($t0) # Load the $s0 field from the context into $t2.
Context array
To store the contexts of the two jobs, a two element array is used. The array is
indexed by job id (0 or 1). Each element of the array is a pointer to
storage allocated for the context.
Addressing the context array
The two element context array is indexed by job id (0 or 1). Each element of
the context array is a pointer to a job context, i.e., a four byte address to a
job context.
If ca is the address of the context array and jid the job id, the following table shows
how to calculate the address to the context pointer the job with id jid.
Job id (jid)
Offset to context pointer
Address of context pointer
0
0 == jid * 4
ca + jid * 4
1
4 == jid * 4
ca + jid * 4
Example
Multiplying with 4 is equivalent to shift left two bits. In Mips assembly the
sll (Shif Left Logical) instruction is used to bit shift to the left.
If the context array is stored at label __context_array and the job id (jid)
the of the running job is stored at label __running the following example shows how to
get the address to the context of the running job.
#Get job id (jid) of the running job.
lw$t0, __running
#Offset to context pointer (0 or 4) = jid *4.
sll$t1, $t0, 2# jid *4#Pointer to context.
lw$t3, __context_array($t1)
Now $3 contains the address of the running jobs context and can be used to
access fields within the context as described in the
section addressing the context.
Save context
When entering the kernel, the context of the running job must be saved. i.e., the
contents of $pc, $v0, $a0, $a1, $s0 and $at must be saved to memory.
Restore context
When the kernel resume the execution of a job, the job context is first
restored, i.e., the values of $pc, $v0, $a0, $a1, $s0 and $at that
previously been saved to memory are read from memory and restored.
Custom system calls
The kernel will implement the following system calls.
System call code
Name
Description
Arguments
Return value
0
getjid
Get job id of the caller
$a0 - job id of the caller
12
getc
Read a single character from the keyboard
$v0 - ASCII code of pressed key
8
gets
Read a string of characters from the keyboard
$a0 = buffer, $a1 = buffer size
The teqi instruction
The teqi (Trap EQual Immediate) instruction is used to conditionally trigger a
trap exception (exception code 13) that automatically transfers control to the kernel.
teqi rs, imm
The teqi instruction will cause a trap exception (exception code 13) if the value in
register rs is equal to the immediate constant imm.
**Example usage: **To trigger a trap exception we can compare $zero (allways
zero) with zero.
teqi$zero, 0
Instead of using the syscall instruction we use teqi $zero, 0 when we
want to perform one of the custom system calls.
Calling the custom getjid system call
An example showing how to use the custom getjid system call to get the job id
of the caller:
li$v0, 0teqi$zero, 0#On success $a0 will now contain the job id (jid) of the caller.
The below figure shows an example where job 1 calls the custom getjid
system call.
In the above figure important events are marked with a number inside a yellow
circle.
Job 1 is ready to run and job 0 is running.
Job 0 uses a the custom getc system call to read a character from the
keyboard.
The system call uses a trap exception to enter the kernel.
The kernel saves the context (all register values) of job 0.
Besides $k0 an $k1 the kernel can now safely use any of the registers saved to
the job 1 context.
The kernel knows that the running job has id 0.
The kernel restores the context of job 0.
The kernel put the value 0 (the job id) in register $a0.
The kernel resumes execution of job 0.
Calling the custom getc system call
An example showing how to use the custom getc system call to read a character
from the keyboard.
li$v0, 12teqi$zero, 0#On succes $v0 will now contain the ASCII code of the pressed key.
The below figure shows an example where job 1 calls the custom getc system
call and job 2 executes while job 1 waits for the user to press a key on
the keyboard.
In the above figure important events are marked with a number inside a yellow
circle.
Job 1 is ready to run and job 0 is running.
Job 0 uses the custom getc system call to read a character from the
keyboard.
The system call uses a trap exception to enter the kernel.
The kernel saves the context (all register values) of job 0.
The kernel now knows that job 0 waits for input and changes its state from
running to waiting.
The kernel restores the context of job 1.
The kernel resumes execution of job 1 and changes its state from
ready to running.
The human user presses a key on the keyboard.
The key-press causes a keyboard interrupt which is handled by the kernel.
The kernel knows from earlier that job 0 waits for the getc system call to complete.
The kernel saves the context of job 1 and changes its state from
running to ready.
The kernel restores the context of job 0 and changes its state from
waiting to running.
The ASCII value of the pressed key is placed in $v0.
The kernel resumes execution of job 0 with the ASCII value of the pressed key
in $v0.
Known bug in Mars
There is a conflict between the built-in system call 12 read_char and the
Keyboard and Display MMIO Simulator.
Mars may hang
If the Keyboard and Display MMIO Simulator is open and connected, Mars
hangs if the user types a character on the simulated keyboard while Mars
waits for input using the built-in system call 12 read_char.
You don’t have to start from scratch but can use the provided
higher-grade/multiprogramming.s as a starting point.
Higher grade points (max 3)
For 1 point your system must have working implementations of the custom getjid and
getc system calls. Follow the labels TODO_1,
TODO_2, …, TODO_8 in the provided multiprogramming.s file to guide you
step by step.
For 3 points, in addition to the 1 point requirements above, your system must have a working implementation of the custom gets
system call. You must also provide a user level job with a few test cases
showing that gets works for different buffer sizes.
The process concept and IPC
The fundamentals of program execution, processes and inter process communication (IPC).
Subsections of The process concept and IPC
Clone repository
Before you continue, you must clone the processes-and-ipc repository.
Use the git command
From the terminal, navigate to a directory where you want the cloned directory
to be created and execute the following command.
If you run macOS and tree is not installed, use Homebrew to install tree.
brew install tree
The exec family of system calls
The exec family of system calls replaces the program executed by a process.
When a process calls exec, all code (text)
and data in the process is lost and replaced with the executable of the new program.
Although all data is replaced, all open file descriptors remains open after
calling exec unless explicitly set to close-on-exec.
In the below diagram a process is executing Program 1. The program calls exec
to replace the program executed by the process to Program 2.
execlp
The execlp system call duplicates the actions of the shell in searching
for an executable file if the specified file name does not contain a slash (/)
character. The search path is the path specified in the environment by the PATH
variable. If this variable isn’t specified, the default path ":/bin:/usr/bin"
is used.
The execlp system call can be used when the number of arguments to the new
program is known at compile time. If the number of arguments is not known at
compile time, use execvp.
The const char *arg and subsequent ellipses can be thought of as arg0, arg1, ..., argn. Together they describe a list of one or more pointers to
null-terminated strings that represent the argument list available to the
executed program. The first argument, by convention, should point to the
filename associated with the file being executed. The list of arguments must be
terminated by a NULL pointer.
Example
In processes-and-ipc/examples/src/execlp_ls.c you find the following example program
demonstrating how execv can be used.
#include<unistd.h> // execlp()#include<stdio.h> // perror()#include<stdlib.h> // EXIT_SUCCESS, EXIT_FAILUREintmain(void) {
execlp("ls", "ls", "-l", NULL);
perror("Return from execlp() not expected");
exit(EXIT_FAILURE);
}
The program uses execlp to search the PATH for an executable file named ls
and passing
-l as argument to the new program. The new program is the same program used by
the shell command ls to list files in a directory.
Use make to compile:
make
Run the program.
./bin/execlp_ls
You should see something similar to this in the terminal.
-rw-r--r--@ 1 karl staff 410 Jan 27 21:16 Makefile
drwxr-xr-x 17 karl staff 578 Jan 28 22:08 bin
drwxr-xr-x 3 karl staff 102 Dec 12016 data
drwxr-xr-x 2 karl staff 68 Jan 28 22:08 obj
drwxr-xr-x 17 karl staff 578 Jan 28 22:08 src
The execvp system call will duplicate the actions of the shell in searching
for an executable file if the specified file name does not contain a slash (/)
character. The search path is the path specified in the environment by the PATH
variable. If this variable isn’t specified, the default path ":/bin:/usr/bin"
is used. In addition, certain errors are treated specially.
Argument vector. An array of pointers to
null-terminated strings that represent the argument list available to the new
program. The first argument, by convention, should point to the filename
associated with the file being executed. The array of pointers must be
terminated by a NULL pointer.
Example
In processes-and-ipc/examples/src/execvp_ls.c you find the following example program
demonstrating how execvp can be used.
The program uses execvp to search the PATH for an executable file named ls
and passing
-l as argument to the new program. The new program is the same program used by
the shell command ls to list files in a directory. In comparison to using
execv we don’t have to provide the full path to ls when using execvp, only
the name of the executable.
Use make to compile:
make
Run the program.
./bin/execvp_ls
You should see something similar to this in the terminal.
total 8-rw-r--r--@ 1 abcd1234 staff 410 Jan 27 21:16 Makefile
drwxr-xr-x 5 abcd1234 staff 170 Jan 27 21:17 bin
drwxr-xr-x 2 abcd1234 staff 68 Jan 27 21:17 obj
drwxr-xr-x 5 abcd1234 staff 170 Jan 27 21:16 src
execv
In comparison to execvp the execv system call doesn’t search the PATH.
Instead, the full path to the new executable must be specified. .
Argument vector. The argv argument is an array of character pointers
to null-terminated strings. The last member of this array must be a null
pointer. These strings constitute the argument list available to the new
process image. The value in argv[0] should point to the filename of the
executable for the new program.
Example
In processes-and-ipc/examples/src/execv_ls.c you find the following example program
demonstrating how execv can be used.
The program uses execv to replace itself with the /bin/ls program passing
-l as argument to the new program. The new program is the same program used by
the shell command ls to list files in a directory.
Use make to compile:
make
Run the program.
./bin/execv_ls
You should see something similar to this in the terminal.
total 8-rw-r--r--@ 1 abcd1234 staff 410 Jan 27 21:16 Makefile
drwxr-xr-x 5 abcd1234 staff 170 Jan 27 21:17 bin
drwxr-xr-x 2 abcd1234 staff 68 Jan 27 21:17 obj
drwxr-xr-x 5 abcd1234 staff 170 Jan 27 21:16 src
Process management
One of the philosophies behind Unix is the
motto do one thing and do it well. In this spirit, basic
process management is done with a number of system calls, each with a single
(simple) purpose. These system calls can then be combined to implement more complex behaviors.
The following system calls are used for basic process management.
fork
A parent process uses fork to create a new child process. The child process is
a copy of the parent. After fork, both parent and child executes the same
program but in separate processes.
exec
Replaces the program executed by a process. The child may use exec
after a fork to replace the process’ memory space with a new
program executable making the child execute a different program than the parent.
exit
Terminates the process with an exit status.
wait
The parent may use wait to suspend execution until a child terminates. Using
wait the parent can obtain the exit status of a terminated child.
Parent and child
The process invoking fork is called the parent. The new process created as the
result of a fork is the child of the parent.
After a successful fork, the child process is a copy of the parent. The parent
and child processes executes the same program but in separate processes.
Fork
The fork system call is the primary (and historically, only) method of process creation in
Unix-like operating systems.
#include<unistd.h>pid_tfork(void);
Return value
On success, the PID of the child process is returned in the parent, and 0 is
returned in the child. On failure, -1 is returned in the parent, no child
process is created, and errno is set appropriately.
Fork returns twice on success
On success fork returns twice: once in the parent and once in the child. After
calling fork, the program can use the fork return value to tell whether
executing in the parent or child.
If the return value is 0 the program
executes in the new child process.
If the return value is greater than zero,
the program executes in the parent process and the return value is the process
ID (PID) of the created child process.
On failure fork returns -1.
Template program
In the file examples/src/fork-template.c you find a template for a
typical program using fork.
1#include<stdio.h> // perror() 2#include<stdlib.h> // exit(), EXIT_SUCCESS, EXIT_FAILURE 3#include<unistd.h> // fork() 4 5intmain(void) {
6 7pid_t pid;
8 9switch (pid =fork()) {
1011case-1:12// On error fork() returns -1.
13perror("fork failed");
14exit(EXIT_FAILURE);
1516case0:17// On success fork() returns 0 in the child.
1819// Add code for the child process here.
2021exit(EXIT_SUCCESS);
2223default:24// On success fork() returns the pid of the child to the parent.
2526// Add code for the parent process here.
2728exit(EXIT_SUCCESS);
29 }
30}
Header files
On lines 1-3 a number of header files are included to get access to a few functions
and constants from the C Standard library.
pid_t
One line 7 the variable pid of type pid_t is declared. The pid_t data
type is the data type used for process IDs.
fork
On line 9 the parent process calls fork and stores the return value in the
variable pid.
switch
On line 9 a switch-statement is used to check the return value of fork.
Error (case -1)
On failure fork returns -1 and execution continues in the case -1 branch
of the switch statement (line 11). The operating system was not able to create a
new process. The parent uses perror to print an error message (line 13) and
then terminates with exit status EXIT_FAILURE (line 14).
Child (case 0)
On success fork returns 0 in the new child process and execution continues
in the case 0 branch of the switch statement (line 16). Any code to be executed
only by the child is placed here (line 19). The child terminates with exit
status EXIT_SUCCESS (line 21).
Parent (default)
If the value fork returned by fork was neither -1 (error) nor 0 (child), execution continues
in the parent process in the default branch of the switch statement (line 23). In this case, the value returned by fork
is the process ID (PID) of the newly created child process.
A first fork example
In the file examples/fork.c you find a program with the following
main function.
intmain(void) {
pid_t pid;
switch (pid =fork()) {
case-1:// On error fork() returns -1.
perror("fork failed");
exit(EXIT_FAILURE);
case0:// On success fork() returns 0 in the child.
child();
default:// On success fork() returns the pid of the child to the parent.
parent(pid);
}
}
The code for the child is in the function child and the code for the parent in
the function parent.
voidchild() {
printf(" CHILD <%ld> I'm alive! My PID is <%ld> and my parent got PID <%ld>.\n",
(long) getpid(), (long) getpid(), (long) getppid());
printf(" CHILD <%ld> Goodbye!\n",
(long) getpid());
exit(EXIT_SUCCESS);
}
voidparent(pid_t pid) {
printf("PARENT <%ld> My PID is <%ld> and I spawned a child with PID <%ld>.\n",
(long) getpid(), (long) getpid(), (long) pid);
printf("PARENT <%ld> Goodbye!\n",
(long) getpid());
exit(EXIT_SUCCESS);
}
Both parent and child prints two messages and then
terminates.
Navigate to the examples directory. Compile using make.
make
Run the program.
./bin/fork
You should see output similar to this in the terminal.
PARENT <87628> Spawned a child with PID = 87629.
PARENT <87628> Goodbye.
CHILD <87629> I'm alive and my PPID = 1.
CHILD <87629> Goodbye.
Run the program multiple times and look specifically at the PPID value
reported by the child. Sometimes the child reports PPID = 1 but
sometimes it is equal to the PID of the parent. Clearly the PID of the parent is
not 1? Why doesn’t report the “correct” PPID value all the time?
Orphans
An orphan process is a process whose parent process has terminated, though it
remains running itself. Any orphaned process will be immediately adopted by the
special init system process with PID 1.
Processes execute concurrently
Both the parent process and the child process competes for the CPU with all
other processes in the system. The operating systems decides which process to
execute when and for how long. The process in the system
execute concurrently.
In our example program:
most often the parent terminates before the child and
the child becomes an orphan process adopted by init (PID = 1) and therefore
reports PPID = 1
sometimes the child process terminates before its parent and then the child is
able to report PPID equal to the PID of the parent.
Wait
The wait system call blocks the caller until one of its child process
terminates. If the caller doesn’t have any child processes, wait returns
immediately without blocking the caller. Using wait the parent can obtain the
exit status of the terminated child.
If status is not NULL, wait store the exit status of the terminated child in the
int to which status points. This integer can be inspected using the
WIFEXITED and WEXITSTATUS macros.
Return value
On success, wait returns the PID of the terminated child. On failure (no
child), wait returns -1.
The integer status value set by the wait system call.
Return value
The exit status of the child. This consists of the least significant 8 bits of
the status argument that the child specified in a call to exit or
as the argument for a return statement in main. This macro should be employed
only if WIFEXITED returned true.
Example using wait
In the examples/fork_exit_wait.c example program the parent execute
the parent function.
On line 6 the parent calls wait(NULL) to wait for the
child process to terminate.
Compile and run the program. Now the parent should always wait for the child to terminate before terminating
itself. As a consequence the child should:
newer be adopted by init
new report PPID = 1
always report PPID equal to the PID of the parent.
Example using wait to obtain the exit status of the child
In the examples/fork_exit_wait_status.c example program the parent execute
the parent function.
One line 2 the parent creates the variable status. On line 7 the parent calls
wait(&status) to wait for the child process to terminate. The & is the
address-of operator and &status returns the address of the status variable.
When the child terminates the exit status of the child will be stored in
variable status.
Compile using make.
make
Run the program.
./bin/fork_exit_wait_status
In the output you should be able to see that the
parent obtained the exit status of the child.
PARENT <99340> Spawned a child with PID = 99341.
CHILD <99341> I'm alive and my PPID = 99340.
CHILD <99341> Goodbye, exit with status 42.
PARENT <99340> Child with PID =99341 and exit status =42 terminated.
PARENT <99340> Goodbye.
Zombies
A terminated process is said to be a zombie or defunct until the parent does
wait on the child.
When a process terminates all of the memory and resources associated with it
are deallocated so they can be used by other processes.
However, the exit status is maintained in the PCB until the parent picks up
the exit status using wait and deletes the PCB.
A child process always first becomes a zombie.
In most cases, under normal system operation zombies are immediately waited on
by their parent.
Processes that stay zombies for a long time are generally an error and cause a
resource leak.
An example with a zombie process
In the examples/fork_zombie.c example program the child terminates
before the parent does wait on the child and becomes a zombie process.
The parent execute
the parent function.
1voidparent(pid_t pid) {
2 3printf("PARENT <%ld> Spawned a child with PID = %ld.\n",
4 (long) getpid(), (long) pid);
5 6printf("PARENT <%ld> Press any key to reap a zombie!\n",
7 (long) getpid());
8 9getchar();
1011 pid =wait(NULL);
1213printf("PARENT <%ld> Zombie child with PID = %ld",
14 (long) getpid(), (long) pid);
1516exit(EXIT_SUCCESS);
17}
On line 9 the parent uses getchar to block itself until
the user presses a key on the keyboard.
When the child terminates, the exit status of the child is stored in the
child process
control block (PCB). The operating system deallocates all memory used by the
child but the PCB cannot be deallocated until the parent does wait on the
child.
Compile using make.
make
Run the program.
./bin/fork_zombie
In the output you should be able to see that the child terminates and that the
parent blocks waiting for a keypress.
PARENT <4636> Spawned a child with PID = 4637.
PARENT <4636> Press any key to reap a zombie!
CHILD <4637> I'm alive and my PPID = 4636.
CHILD <4637> Goodbye.
The child process has terminated but the parent has yet not read the exit status
of the child using wait. The child process has now become a zombie process.
Monitor
On Unix-like systems, the top command produces an ordered list of running
processes selected by user-specified criteria, and updates it periodically.
There are a few differences between the top command used by OS X and Linux. The
tools/monitor tools provides a simple but portable alternative for
monitoring processes with a specified command name.
Open a second terminal and navigate to the processes-and-ipc directory.
The tools/monitor tool can be used to view process status information
about process.
Use the --help flag to see the documentation.
./tools/monitor --help
This is the built in documentation for the monitor tool.
Usage: monitor [-s delay][-p pid] cmd
A top-like command that only lists USER, PID, STAT and COMM for the
current user and and processes with a command name with a grep match of cmd.
Options:
-s delay Delay in seconds between refresh, default = 1.
-p pid Include process with PID pid.
The cmd argument is the name of the program executed by the processes we want
to monitor.
Now let’s try and use the monitor tool to view process status information
for the parent and child, both executing the fork_zombie example program.
./tools/monitor fork_zombie
On Linux you should see something similar to this.
Monitoring processes matching: fork_zombie
Press Ctrl-C to exit
USER PID PPID S COMMAND
abcd1234 46364311 S fork_zombie
abcd1234 46374636 Z fork_zombie <defunct>
In the PID column you see the PID of the listed processes. The first line shows
information about the parent and the second line shows information about the
child.
The S column show the status of the process.
The parent got status S (sleep) meaning the process is waiting for an event
to complete. In this case the parent is blocked waiting for the call to
getchar() to return, i.e, the parent is blocked waiting for a key to be
pressed on the keyboard.
The child got status Z (zombie) meaning the process terminated but not
yet reaped by its parent, i.e., the parent is alive but have not yet done
wait on the terminated child.
Another name used for a zombie process is defunct.
Reap the zombie
From the terminal used to run the fork_zombie program, press any key to make the
parent do wait on the child.
PARENT <4636> Spawned a child with PID = 4637.
PARENT <4636> Press any key to reap a zombie!
CHILD <4637> I'm alive and my PPID = 4636.
CHILD <4637> Goodbye.
PARENT <4636> Zombie child with PID =4637 reaped!
PARENT <4636> Press any key to terminate!
In the terminal used to run monitor the zombie process should have disappear,
leaving only the parent process.
Monitoring processes matching: fork
Press Ctrl-C to exit
USER PID PPID S COMMAND
abcd1234 46364311 S fork_zombie
The parent is now blocked, waiting for user input.
Terminate the parent
From the terminal used to run the fork_zombie program, press any key to make the
parent terminate.
PARENT <4636> Spawned a child with PID = 4637.
PARENT <4636> Press any key to reap a zombie!
CHILD <4637> I'm alive and my PPID = 4636.
CHILD <4637> Goodbye.
PARENT <4636> Zombie child with PID =4637 reaped!
PARENT <4636> Press any key to terminate!
PARENT <4636> Goodbye!
Execute a new program in the child
If you don’t want to execute the same program in both the parent and the child,
you will need to use a system call of the exec family. The exec system calls
will replace the currently executing program with a new executable.
In examples/src/child.c you this small program.
#include<stdio.h> // puts(), printf(), perror(), getchar()#include<stdlib.h> // exit(), EXIT_SUCCESS, EXIT_FAILURE#include<unistd.h> // getpid(), getppid()intmain(void) {
printf(" CHILD <%ld> I'm alive and my PPID = %ld.\n",
(long) getpid(), (long) getppid());
printf(" CHILD <%ld> Press any key to make me terminate!\n",
(long) getpid());
getchar();
printf(" CHILD <%ld> Goodbye!\n",
(long) getpid());
exit(127);
}
Compile using make.
make
Run the program.
./bin/child
First this program simply prints two messages to the terminal and then wait for a key-press.
CHILD <33172> I'm alive and my PPID = 81166.
CHILD <33172> Press any key to make me terminate!
After you press any key in the terminal the program terminates.
CHILD <33172> I'm alive and my PPID = 81166.
CHILD <33172> Press any key to make me terminate!
CHILD <33172> Goodbye!
The examples/src/fork_exec.c program uses execv to make the child process execute the examples/bin/child executable. After fork the child executes the child functions.
1voidchild() {
2char*const argv[] = {"./bin/child", NULL};
3 4printf(" CHILD <%ld> Press any key to make me call exec!\n",
5 (long) getpid());
6 7getchar();
8 9execv(argv[0], argv);
1011perror("execv");
12exit(EXIT_FAILURE);
13}
On line 2 the needed argument vector is constructed. On line 7 the child waits
for a key-press. After the key-press, on line 9, the child use execv to
replace the program executed by the child process by the child executable. If
execv is successful control will never be returned and lines 11 and 12 should
not be reached.
Compile using make.
make
Run the program.
./bin/fork_exec
PARENT <33422> Spawned a child with PID = 33423.
CHILD <33423> Press any key to make me call exec!
Open a second terminal and use the ps command with the -p option to see
information about the child process.
Note that the child process now executes the ./bin/child executable.
In the first terminal, press any key to make the child process terminate. Now
the parent performs wait on the child and reports the child exit status.
CHILD <33423> Goodbye!
PARENT <33422> Child with PID =33423 and exit status =127 terminated.
PARENT <33422> Goodbye!
Signals
Mandatory assignment
Signals are a limited form of inter-process communication (IPC), typically used
in Unix, Unix-like, and other POSIX-compliant operating systems. 1
A signal is used to notify a process of an synchronous or asynchronous event.
When a signal is sent, the operating system interrupts the target process'
normal flow of execution to deliver the signal. If the process has previously registered a
signal handler, that routine is executed. Otherwise, the default signal handler
is executed. 1
Each signal is represented by an integer value. Instead of using the numeric
values directly, the named constants defined in signals.h
should be used.
The signal_handler function will handle signals sent to
the process. A switch statement is used to determine which
signal has been received. An alternative is to use one signal handling function for each signal
but here a single signal handling function is used.
main
All C programs starts to execute in the main function.
The process ID (PID) is obtained using the getpid function and printed to
the terminal with printf.
A number of lines are commented out, we’ll get back to these later.
The function puts is used to print the string I'm done! on a separate line
to the terminal.
Finally, exit is used to terminate the process with exit status
EXIT_SUCCESS defined in stdlib.h.
Program, executable and process
Let’s repeat the differences between a program, an executable and a process.
Program
A set of instructions which is in human readable format. A
passive entity stored on secondary storage.
Executable
A compiled form of a program including machine
instructions and static data that a computer can load and execute. A
passive entity stored on secondary storage.
Process
An excutable loaded into memory and executing or waiting. A
process typically executes for only a short time before it either
finishes or needs to perform I/O (waiting). A process is an active
entity and needs resources such as CPU time, memory etc to execute.
The make build tool
The make build tool is used together with the Makefile to compile all programs in
the mandatory/src directory.
Compile all programs
From a terminal, navigate to the mandatory directory. To compile all
programs, type make and press enter.
make
When compiling, make places all executables in the bin directory.
First test run
Run the signals program.
./bin/signals
You should now see output similar to this in the terminal.
My PID =81430I'm done!
Note that the PID value you see will be different.
New process
Run the program a few times. Note that each time you run the same program the
process used to execute the program gets a new process ID (PID).
C comments
In C, // is used to start a comment reaching to the end of the line.
Division by zero
To make the program divide by zero, uncomment the following line.
// divide_by_zero();
Compile with make.
make
Run the program.
./bin/signals
In the terminal you should see something similar to this.
My PID =81836[2]81836 floating point exception ./bin/signals
Division by zero causes an exception. When the OS handles the exception it sends
the SIGFPE (fatal arithmetic error) signal to the process executing the division by zero. The default
handler for the SIGFPE signal terminates the process and this is exactly
what happened here.
Division by zero on Mac
On some versions of Mac hardware, integer division by zero does not cause a
SIGFPE signal to be sent, instead a SIGILL (illegal instruction) signal
is sent. On other combinations of Mac hardware and C compiler, some other
signal might be sent, or no signal is sent at all.
If you run on Mac hardware and the process does not terminate when dividing by
zero, you can:
try to catch the SIGILL signal instead of the
SIGFPE signal
or, you could simply skip the whole division by zero part of
this assignment.
Run the program a few times. Each time you run the program the same error
(division by zero) happens, causing an exception, causing the OS to send the
process the SIGFPE signal, causing the process to terminate.
Synchronous signals
Synchronous signals are delivered to the same process that performed the operation that caused the
signal. Division by zero makes the OS send the process the synchronous signal
SIGFPE.
Installing a signal handler
A program can install a signal handler using the signal function.
signal(sig, handler);
sig
The signal you want to specify a signal handler for.
handler
The function you want to use for handling the signal.
Handling SIGFPE
Uncomment the following line to install the signal_handler function as the
signal handler for the SIGFPE signal.
// signal(SIGFPE, signal_handler);
Compile with make.
make
Run the program.
./bin/signals
In the terminal you should see something similar to this.
My PID =81979Caught SIGFPE: arithmetic exception, such as divide by zero.
This time the signal doesn’t terminate the process immediately. When the process
receives the SIGFPE signal the function signal_handler is executed with the
signal number as argument. After printing a message to the terminal the signal
handler terminates the process with status EXIT_FAILURE.
No more division by zero
Comment out the following line.
divide_by_zero();
Compile and run the program Make sure you see output similar to this in the
terminal.
My PID =82040I'm done!
Segfault
A segmentation fault (aka segfault) are caused
by a program trying to read or write an illegal memory location.
To make the program cause a segfault, uncomment the following line.
// segfault();
Compile with make.
make
Run the program.
./bin/signals
In the terminal you should see something similar to this.
My PID =82084[2]82084 segmentation fault ./bin/signals
The illegal memory access causes an exception. When the OS handles the exception it sends
the SIGSEGV signal to the process executing the illegal memory access. The default
handler for the SIGSEGV signal terminates the process and this is exactly
what happened here.
Run the program a few times. Each time you run the program the same error
(illegal memory access) happen, causing an exception, causing the OS to send the
process the SIGSEGV signal, causing the process to terminate.
Synchronous signals
Synchronous signals are delivered to the same process that performed the operation that caused the
signal. An illegal memory access makes the OS send the process the synchronous signal
SIGSEGV.
Handling SIGSEGV
Add code to install the function signal_handler as the signal handler for the
SIGSEGV signal.
When you run the program you should output similar to this in the terminal.
My PID =82161Caught SIGSEGV: segfault.
No more segfault
Comment out the following line.
segfault();
Compile and run the program Make sure you see output similar to this in the
terminal.
My PID =82040I'm done!
Wait for a signal
The pause function is used to block a process until it receives a signal (any
signal will do).
Uncomment the following line.
// pause();
Compile and run the program. You should see output similar to this in the
terminal.
My PID =82249
The process is now blocked, waiting for any signal to be sent to the process.
Ctrl+C
To terminate the process, press Ctrl+C in the terminal.
My PID =82249^C
Note that once the process terminates you get the terminal prompt back.
Asynchronous signals
Asynchronous signals are generated by an event external to a running process.
Pressing Ctrl+C is an external event causing the OS to send the asynchronous SIGINT
(terminal interrupt) signal to the process.
The default signal SIGINT handler terminates the process.
Handling SIGINT
Add code to install the function signal_handler as the signal handler for the
SIGINT signal.
When you run the program the process blocks waiting for any signal. When you
press Ctrl+C you should now see output similar to this in the terminal.
My PID =82477^CCaught SIGINT: interactive attention signal, probably a ctrl+c.
I'm done!
Open a second terminal
Open a second terminal.
Sending signals from the terminal
Compile and run the program in one of the terminals. The program should block
waiting for any signal. Note the PID of the blocked process.
My PID =82629
The command kill can be used to send signals to processes from the terminal.
To send the SIGINT signal to the blocked process, execute the following command in
the terminal where you replace <PID> with the PID of the blocked process.
kill -s INT <PID>
In the other terminal you should now see the blocked process execute the signal
handler, then continue in main after pause(), print I'm done! and terminate.
My PID =82629Caught SIGINT: interactive attention signal, probably a ctrl+c.
I'm done!
Handle SIGUSR1
Add code to make the program print “Hello!” when receiving the SIGUSR1 signal.
Compile and run the program from one terminal.
Send the SIGUSR1 signal to the process from the other terminal using the
kill command where you replace <PID> with the PID of the blocked process.
kill -s SIGUSR1 <PID>
Don’t terminate on SIGUSR1
How can you make the program print Hello! every time the signal SIGUSR1 is
received without terminating?
Set the global variable done to true
In the signal_hanlder function, set the global variable done to true when handling the
SIGINT signal.
Block until done
In main, replace the line:
pause();
, with the following while loop:
while (!done);
In C ! is the logical not operator. This while loop repeatedly checks the global
variable done until it becomes true.
Compile, run and test
Compile and run the program from one terminal and send signals to the process from
the other terminal.
Are you able to send multiple SIGUSR1 signals to the process?
Are you able to break out of the while loop and terminate the process by sending the signal SIGINT to the
process, or by pressing Ctrl+C from the terminal?
Bug?
Depending on your compiler the program may not break out of the while(!done) loop
An optimizing compiler
An optimizing compiler may detect that the variable done is not changed in the
while(!done); loop and replace the loop with if (!false);.
Volatile
Do you remember the volatile keyword?
Volatile
The volatile keyword is used to make sure that the contents of a variable
is always read from memory.
Make the global variable done volatile.
Compile, run and test
Compile and run the program from one terminal and send signals to the process from
the other terminal.
Make sure you are able to send multiple SIGUSR1 signals to the process.
Make sure you can terminate the process by sending the signal SIGINT to the
process, or by pressing Ctrl+C from the terminal.
sig_atomic_t
The data type sig_atomic_t guarantees that reading and writing a variable happen in a single
instruction, so there’s no way for a signal handler to run “in the middle” of an
access. In general, you should always make any global variables changed by a
signal handler be of the data type sig_atomic_t.
Change the datatype of the global variable done from bool to sig_atomic_t.
Use pause instead
Using a while loop to repeatedly check the global variable done is not a
very efficient use of the CPU. A better way is to change the loop to:
while (pause()) {
if (done) break;
};
Why is this more efficient?
Code grading questions
Here are a few examples of questions that you should be able to answer, discuss
and relate to the source code of you solution during the code grading.
What is a signal?
How do signals relate to exceptions and interrupts?
What is a signal handler?
How do you register a signal handler?
What happens if you don’t register a signal handler?
What causes a segfault?
What is meant by a synchronous signal?
What do the systemcall pause() do?
What happens when you press Ctrl-C in the controlling terminal of a process?
How do you send signals to other processes?
Why is the keyword volatile needed when declaring the global variable done?
Why is the datatype sig_atomic_t needed when declaring the global variable done?
Why is it more efficient to use pause() instead of simply loop and check the done variable?
Your task is to create a system with one parent process and two
child processes where the children communicate using a pipe.
Open a terminal
Open a terminal and navigate to the mandatory directory.
List directory contents (ls)
The ls shell command list directory content. Execute the ls command in the
terminal.
ls
You should now see this:
Makefile bin obj src
The -F option appends a slash / to directory entries.
ls -F
The only file in the directory is Makefile. The directory contains the
subdirectories bin, obj and src.
Makefile bin/ obj/ src/
Add the -1 option to:
ls -F -1
, print each entry on a separate line:
Makefile
bin/
obj/
src/
Line numbering filter (nl)
The nl shell command is a filter that reads lines from stdin and echoes each
line prefixed with a line number to stdout. In the terminal, type nl and press
enter.
nl
The nl command now waits for stdin input. Type Some text and press enter.
Some text
1 Some text
Type More text and press enter.
More text
2 More text
For each line you type, the line is echoed back with a line number. Play around
some more with the nl command. Press Ctrl+D (End Of File) to make the nl
command exit.
Pipeline
One of the philosophies behind Unix is the
motto do one thing and do it well. In this spirit, each shell command
usually have a very specific purpose. More complicated commands can be
constructed by combining simpler commands in a pipeline such that the output
of one command becomes the input to another command.
The standard shell syntax for
pipelines is to list multiple commands, separated by vertical bars | (the pipe
character). In the below example the output from the ls -F -1
command is piped to input of the nl command.
ls -F -1 | nl
Now the result of ls -F -1 is printed with line numbers added at the front of each line.
1 Makefile
2 bin/
3 obj/
4 src/
Shell commands are ordinary programs
All shell commands are ordinary programs. When the shell executes a command, the
shell first forks a new process and uses exec to make the new process execute
the command program.
Which programs
The which utility locates a program executable in the user’s PATH. Use which to
see which program executables the shell uses for the ls and nl commands.
which ls
The executables for the ls command program is found in the /bin directory.
/bin/ls
What about the nl command?
which nl
The executables for the nl command programs is also located in the
/bin directory.
/bin/nl
System overview
Your task is to create a program that mimics the ls -F -1 | nl pipeline. The
parent process uses fork to create two child processes. Child A uses exec
to execute the ls -F -1 command and Child B uses exec to execute the
nl command. The children uses a pipe to communicate. The stdout of Child A is
redirected to the write end of the pipe. The stdin of the Child B is redirected
to the read end of the pipe.
Pipe
How can you make the child process share a pipe? Which process should create the
pipe? When should the pipe be created?
Parent forks twice
The parent must use fork twice, once for each child process.
Parent waits twice
The parent should use wait twice to wait for both child processes to
terminate.
The children uses execlp
The child process should use execlp to execute their
commands.
The children uses dup2
The child process should use dup2 to redirect stdout and stdin.
Process A redirects stdout to write to the pipe.
Process B redirects stdin to read from the pipe.
Close unused pipe file descriptors
Don’t forget to close unused pipe file descriptors, otherwise a reader or writer
might be blocked .
Attempt
Conditions
Result
Read
Empty pipe, writers attached
Reader blocked
Read
Empty pipe, no writer attached
End Of File (EOF) returned
Write
Full pipe, readers attached
Writer blocked
Write
No readers attached
SIGPIPE
Closing a read descriptor to early may cause a SIGPIPE.
Beware of SIGPIPE
The default SIGPIPE signal handler causes the process to terminate.
Check return values
You should check the return values of all system calls to detect errors. On error use
perror to print an error message and then terminate with exit(EXIT_FAILURE).
pipeline.c
Use the file src/pipeline.c to implement your solution.
You must add code the the main function. You must add code here.
After fork, Child A should execute the child_a function. You must add code here.
After fork, Child B should execute the child_b function. You must add code here.
You may add your own functions to further structure your solution.
Compile and run
Use make to compile.
make
Run the program.
./bin/pipeline
When running the finished program you should see output similar to this, where
$ is your shell prompt.
Here are a few examples of general questions not directly related to the source
code that you should be able to answer and discuss during the code
grading.
What do we mean with a process pipeline?
What is a pipe?
How are pipes used to construct process pipelines?
Show an example of a proccess pipeline in the terminal (shell).
How are shell (terminal) commands implemented?
What happens to the file descriptor table after a successful creation of a new pipe?
Here are a few examples of questions that you should be able to answer, discuss
and relate to the source code of you solution during the code grading.
How many times does the parent calls fork and why?
Why do the children need to call execlp()?
Explain how each child is able to redirect stdin or stdout from or to the pipe?
How will the consumer know when there is no more data to expect from the pipe?
Why is it important for a process to close any pipe file descriptors it does not intend to use?
What could happen if you close a read descriptor to early?
Shell
Optional assignment for higher grade (3 points)
A shell is an interface between a user and the
operating system. It lets us give commands to the system and start other
programs.
Your task is to program a simple shell similar to for
example Bash, which probably is the command shell you normally use
when you use a Unix/Linux system.
Preparations
When programming a shell, several of the POSIX system calls you studied already
will be useful. Before you continue, make sure you have a basic understanding of
at least the following system calls: fork(), execvp(), getpid(), getppid(),
wait(), pipe(), dup2() and close().
Files to use
In the higher-grade/src directory you find the following files.
parser.h
Header file for a provided command line parser.
parser.c
Implementation of the provided command line parser.
shell.c
Here you will implement your shell.
Compile and run
Navigate to the higher-grade directory. Use make to compile.
make
Run the shell.
./bin/shell
The provided version of the shell uses >>> as the prompt and is able to execute single commands, for
example ls.
>>> ls
>>> Makefile bin obj src
Note that something is wrong with the shell prompt >>> . When executing a
command, the prompt is printed immediately after the command, and not after the
command has completed. This is something you need to fix.
Let’s try to pipe two commands together.
>>> ls | nl
>>> Makefile bin obj src
When trying to pipe two commands together, only the first command is executed.
The second command is not executed. The output of the first command in not piped
to as input to the second command. This is something you need to fix.
Higher grade points (max 3)
For 1 point your shell must be able to handle a single command and a pipeline
with two commands. When executing a command line, the prompt >>> must be
printed after the execution of the command line has finished.
For 3 points, in addition to the 1 point requirements above, the shell must be able to
handle a pipeline with two, three or more commands.
You must also make sure that after a command line has finished, all
descriptor to created pipes are closed. Otherwise the operating system will not
be able to deallocate the pipes and potentially re-use the descriptor values.
Command data
In the file parser.h the following C structure is defined.
/**
* Structure holding all data for a single command in a command pipeline.
*/typedefstruct {
char* argv[MAX_ARGV]; // Argument vector.
position_t pos; // Position within the pipeline (single, first, middle or last).
int in; // Input file descriptor.
int out; // Output file descriptor.
} cmd_t;
The above structure is used to hold data for a single command in a command pipe
line.
Command array
In the file shell.c command data for all commands in
a command pipeline is stored in a global array.
/**
* For simplicitiy we use a global array to store data of each command in a
* command pipeline .
*/cmd_t commands[MAX_COMMANDS];
Parser
In parser.h you find the following prototype.
/**
* parses the string str and populates the commands array with data for each
* command.
*/intparse_commands(char*str, cmd_t* commands);
This function parse a command line string str such as "ls -l -F | nl" and populates the commands array with command data.
Program design
The below figure shows the overall structure of the shell.
When a user types a command line on the form A | B | C the parent parses the
user input and creates one child process for each of the commands in the
pipeline. The child processes communicates using pipes. Child A redirects stdout
to the write end of pipe 1. Child B redirects stdin to the read end of pipe 1
and stdout to the write end of pipe 2. Child C redirects stdin to the read end
of pipe 2.
parser.c
In the parser.c file you must complete the
implementation of the following function.
/**
* n - number of commands.
* i - index of a command (the first command has index 0).
*
* Returns the position (single, first, middle or last) of the command at index
* i.
*/position_tcmd_position(int i, int n) {
shell.c
Use shell.c to implement your solution. This file
already implements the most basic functionality but it is far from complete.
Feel free to make changes
When implementing your solution, you are allowed to:
add your own functions
modify existing functions
add (or remove) arguments to existing functions
modify existing data structures
add you own data structures.
Alternative program design
The provided code is based on a design where the shell (parent) process creates
one child process for each command in the pipeline.
An alternative design is for the first child process to create the second child,
the second child to create the third child etc. If you prefer this design, this
might require you to modify the provided source code to fit this alternative
design.
Threads and synchronization
Introduction to threads and synchronization.
Subsections of Threads and synchronization
Definitions
Concurrency
Concurrency refers to the ability of different parts or units of a program,
algorithm, or problem to be executed out-of-order or in partial order, without
affecting the final outcome. This allows for parallel execution of the
concurrent units, which can significantly improve overall speed of the execution
in multi-processor and multi-core systems. 1
Two tasks are concurrent if the order in which the two tasks are executed in
time is not predetermined.
Tasks are actually split up into chunks that share the processor with chunks
from other tasks by interleaving the execution in a time-slicing way. Tasks can
start, run, and complete in overlapping time periods.
Process
To run a program the operating system must allocate memory and creates a
process. A processes has a stack, a heap, a data segment and a text segment in user
space. The CPU context and file descriptor table are kept in kernel space. When
executing the program, the program counter (PC) jumps around in the text
segment.
Threads
A process can have one or more threads of execution. Threads share heap, data
segment, text segment and file descriptor table but have separate stacks and
CPU contexts. Each thread has a private program counter and threads executes
concurrently. Depending on how threads are implemented, the CPU contexts can be
stored in user space or kernel space. In the below figure a process with three
threads is shown.
Concurrent tasks
If not explicitly stated otherwise, the term task will be used to refer to a
concurrent unit of execution such as a thread or a process.
Atomic operations
In concurrent programming, an operation (or set of operations) is atomic if
it appears to the rest of the system to occur at once without being interrupted.
Other words used synonymously with atomic
are: linearizable, indivisible or uninterruptible.
2
Non-atomic operations
Incrementing and decrementing a variable are examples of non-atomic operations.
The following C expression,
X++;
, is translated by the compiler to three instructions:
loadX from memory into a CPU register.
incrementX and save result in a CPU register.
store result back to memory.
Similarly, the following C expression,
X--;
, is translated by the compiler to three instructions:
loadX from memory into a CPU register.
decrementX and save result in a CPU register.
store the new value of X back to memory.
Race condition
A race condition or race hazard is the behaviour of an electronic, software or
other system where the output is dependent on the sequence or timing of other
uncontrollable events. It becomes a bug when events do not happen in the
intended order. The term originates with the idea of two signals racing each
other to influence the output first. 3
Data race
A data race occurs when two instructions from different threads access the same
memory location and:
at least one of these accesses is a write
and there is no synchronization that is mandating any particular order among
these accesses.
Critical section
Concurrent accesses to
shared resources can lead to unexpected or erroneous behavior, so parts of the
program where the shared resource is accessed are protected. This protected
section is the critical section or critical region.
Typically, the critical section
accesses a shared resource, such as a data structure, a peripheral device, or a
network connection, that would not operate correctly in the context of multiple
concurrent accesses.4
Mutual exclusion (mutex)
In computer science, mutual exclusion is a property of concurrency
control, which is instituted for the purpose of
preventing race conditions; it is the requirement that
one thread of execution never enter its critical section
at the same time that another concurrent thread of execution enters its own
critical section.5
Often the word mutex is used as a short form of mutual exclusion.
If you run macOS and tree is not installed, use Homebrew to install tree.
brew install tree
The all utility
In the threads-synchronization-deadlock directory you find the all utility script.
The all utility can be used to run a shell command in all subdirectories,
i.e., run a command in all of the three directories examples, higher grade
and mandatory. In the terminal, navigate to the threads-synchronization-deadlock directory.
For example, you can use the all utility together with make to compile all
programs.
./all make
The all utility can also be used to delete all objects files and executables.
./all make clean
Mutual exclusion
Mandatory assignment
In this assignment you will study different methods to enforce mutual
exclusion.
Linux or macOS on Intel CPUs only
This assignment make use of atomic
operations available only on computers with
Intel CPUs running Linux or macOS.
The department Linux system
If you are working on Windows or on Linux or macOS but with a non-Intel CPU, you
can use the department Linux system for this assignment. You may still use your
private computer to access the department Linux system using SSH but make sure
to log in to one of the Linux hosts.
Overview
File to use
mandatory/src/mutex.c
Description
In this program, a process creates a number of threads and waits for their
termination. The threads are divided into two sets I (increment) and D
(decrement). A shared variable which works as a counter is initialized to 0
and then incremented by the threads in set I and decremented by the threads in
set D. The sum of all the increments is equal to the absolute value of the sum
of all the decrements.
Example
There are five threads in set I, each incrementing the counter 20 times
by 2. In total the counter will be incremented by 5*20*2 = 200.
There are two threads in set D, each decrementing the counter 20 times by 5. In
total the counter will be decremented by 2*20*5 = 200.
Desired behavior
When all threads are done executing the value of the shared counter should be
0 (the same as value it was initialized with).
A collection of tests
The provided program will execute 4 different tests. For each test, a different
approach to synchronization will be used by the threads updating the shared
counter variable.
Compile and run
In the terminal, navigate to the mandatory directory. Use
make to compile the program.
make
The executable will be named mutex and placed in the bin sub directory. Run the program from the terminal.
./bin/mutex
Summary of all the tests
At the end of the program output, a summary of the four tests will be printed.
Questions
Run the program several times and study the provided source code.
Does the program work according to the specification?
Can you predict the output before execution? Why?
Identify the critical sections
Identify the critical sections in the
program. The critical sections should be as small as possible.
Mutual exclusion
Your task is to make sure that at any time, at most one thread execute in a
critical section, i.e., access to the critical sections should be mutual
exclusive. You will use three different methods to ensure that updates to the
shared counter variable appear to the system to occur instantaneously,
i.e., make sure updates are atomic.
Test 0 - no synchronization
In test 0 the threads uses the functions inc_no_syncx and dec_no_sync to
update the shared variable counter. Updates are done with no
synchronization.
You don’t have to change or add any code to these two functions. This test is
used to demonsrate the effects of unsynchronized updates to shared variables.
Test 1 - pthread mutex locks
The first synchronization option you will study is to use the
mutex lock provided by the pthreads library to enforce mutual exclusion
when accessing the shared counter variable.
Add the needed synchronization in the functions inc_mutex and dec_mutex to make
the program execute according to the desired behavior.
An alternative to mutex locks is to use the
atomic test-and-set built-in provided by the GCC compiler to implement
a spinlock.
Linux or macOS on Intel CPUs
This part of the assignment make use of atomic
operations available only on computers with
Intel CPUs running Linux or macOS.
If you are working on Windows or on Linux or macOS but with a non-Intel CPU, you
can use the department Linux system for this assignment. You may still use your
private computer to access the department Linux system using SSH but make sure
to log in to one of the Linux hosts.
You will use the following function to access the underlying test-and-set
operation.
int __sync_lock_test_and_set(int *lock, int value)
This atomic operation sets *lock to value and returns the previous
contents of *lock.
At the beginning of mutex.c you find the following declaration.
/* Shared variable used to implement a spinlock */volatileint lock = false;
Todo:
Use the shared lock variable to implement the spin_lock() and spin_unlock()
operations.
Change the functions inc_tas_spinlock and dec_tas_spinlock to use use the
test-and-set spinlock to enforce mutual exclusion.
A third option is to use the atomic addition and subtraction GCC built-ins.
Linux or macOS on Intel CPUs
This part of the assignment make use of atomic
operations available only on computers with
Intel CPUs running Linux or macOS.
If you are working on Windows or on Linux or macOS but with a non-Intel CPU, you
can use the department Linux system for this assignment. You may still use your
private computer to access the department Linux system using SSH but make sure
to log in to one of the Linux hosts.
You will use the following functions to access the underlying atomic increment
and decrement operations.
int __sync_fetch_and_add(int *counter, int n)
This atomic operation increments *counter by n and returns the
previous value of *counter.
int __sync_fetch_and_sub(int *counter, int n)
This atomic operation decrements *counter by n and returns the
previous value of *counter.
Change the functions inc_atomic and dec_atomic to use atomic addition and
subtraction to make the program execute according to the desired behavior.
Study the test summary table printed after all tests have completed.
Make sure all test but test 0 (no synchronization) are successful.
Compare the execution times for the 4 tests.
Which method of synchronization is the fasted?
Which method of synchronization is the slowest?
Which method of synchronization is neither the fastest, nor the slowest?
Why do you think the speed of the three methods of synchronization are
ordered like this?
Code grading questions
Here are a few examples of questions that you should be able to answer, discuss
and relate to the source code of you solution during the code grading.
Explain the following concepts and relate them to the source code and the behavior of the program.
Critical section.
Mutual exclusion (mutex).
Race condition.
Data race.
Locks and semaphores:
What is the purpose of mutex locks?
If you had to make a choice between using a semaphore or a mutex to enforce
mutex, what would you recommend and why?
How do you construct a spinlock using the atomic test-and-set instruction?
Performance analysis:
Discuss and analyze the results in test summary table.
Portable semaphores
Linux and macOS natively supports different types of semaphores. In order to
have a single (simple) semaphore API that works on both Linux and macOS you will
use a portable semaphore library named psem.
In the psem/psem.h header file you find the documentation of the
portable semaphore API.
Example usage
A small example program that demonstrates how to use the sempaphores provided by
the psem library.
#include"psem.h"intmain(void) {
// Create a new semaphore and initialize the semaphore counter to 3.
psem_t*sem =psem_init(3);
// Wait on the semaphore.
psem_wait(sem);
// Signal on the semaphore.
psem_signal(sem);
// Destroy the semaphore (deallocation)
psem_destroy(sem)
}
Example program
In mandatory/src/psem_test.c you find a complete example program with
two threads (main and a pthread) that synchronize their execution using a psem
semaphore.
Compile
In the terminal, navigate to the examples directory. Use
make to compile the program.
make
Run
Run the program from the terminal.
./bin/psem_test
Two thread barrier synchronization
Mandatory assignment
Background
A mutex lock is meant to first be taken and then released, always in that order, by each
task that uses the shared resource it protects.
In general, semaphores should not be used to enforce mutual exclusion.
The correct use of a semaphore is to signaling from one task to another, i.e., a
task either signal or wait on a semaphore, not both.
In this assignment you will solve the two thread barrier problem using semaphores. This
problem clearly demonstrates the type of synchronization that can be provided by
semaphores.
Supported platforms
The provided code has been developed and tested on the department Linux system
and macOS. Most likely you will be able to use any reasonable modern version of
Linux.
Overview
File to use
mandatory/src/two_thread_barrier.c
Description
In this program, a process creates two threads A and B, and waits for their termination.
Each thread performs N iterations. In each iteration the threads print their name (A or B)
and sleeps for some random amount of time. For each iteration the order between the threads
should not be restricted.
Compile and run
In the terminal, navigate to the mandatory directory.
Use make to compile the program.
make
The executable will be named barrier and placed in the bin sub directory.
Run the program from the terminal.
./bin/two_thread_barrier
Questions
Run the programs several times and study the source code. Think about the
following questions.
Could you predict the output before execution? Why?
Adjust the sleeping duration of one thread (or both threads) to have a
different output (ie. another interleaving of the tasks traces). Could you
predict this output? Why?
Rendezvous
Rendezvous or rendez-vous (French pronunciation: [ʁɑ̃devu]) refers to a planned
meeting between two or more parties at a specific time and place.
1
Barrier synchronization (desired behavior)
We now want to put in a barrier in each thread that enforces the two threads to have rendezvous
at the barrier in each iteration.
For each iteration the order between the threads should not be restricted.
The first thread to reach the barrier must wait for the other thread to also reach the barrier.
Once both threads have reached the barrier the threads are allowed to continue with the next iteration.
Examples of execution traces:
AB BA BA AB BA (valid barrier synchronization)
AB BB AB AA AB (invalid synchronization)
Lock-step and rendezvous
Other names for barrier synchronization are lock-step and rendezvous.
Two thread barrier implementation
Your task is to use semaphores to enforce barrier synchronization between the two threads A and B.
Before you continue think about the following questions.
What needs to be initialized?
What needs to be done by each thread inside the barrier?
Compile and run
Compile:
make
, and run the program:
./bin/two_thread_barrier
Example incorrect synchronization
This is an example of an invalid execution trace when running the two_thread_barrier program.
Two threads A and B doing 5 iterations each in lockstep.
Iteration 0 A
B
Iteration 1 B
A
Iteration 2 B
B <===== ERROR: should have been A
Example of correct synchronization
This is an example of a valid execution trace when running the two_thread_barrier program.
Two threads A and B doing 5 iterations each in lockstep.
Iteration 0 A
B
Iteration 1 A
B
Iteration 2 B
A
Iteration 3 A
B
Iteration 4 A
B
SUCCESS: All iterations done in lockstep!
Configuration
In the beginning of two_thread_barrier.c you find the following definitions.
#define ITERATIONS 10 // Number of iterations each thread will execute. #define MAX_SLEEP_TIME 3 // Max sleep time (seconds) for each thread.
Experiment by changing the number of iterations and the max sleep time.
Does the output change?
What are the possible outputs?
Portable semaphores
Use the psem semaphores to enforce rendezvous between the two threads.
This is how you declare and initialize a portable psem semaphore.
psem_t*semaphore;
semaphore =psem_init(0);
Number of semaphores
How many semaphores are needed to enforce barrier synchronization between two threads?
Can this be achieved using a single semaphore?
Do you need to use two semaphores?
Do you need more than two semaphores?
Declare global semaphore variables
For simplicity, declare all psem_t semaphore variables globally.
Initial semaphore values
Initialize your semaphore(s) in the beginning of main(). Should the semaphore(s) be initialized with counter value:
0?
1?
some other value?
Destroy semaphores after use
At the end of main(), don’t forget to destroy any semaphores you have initialized.
Automatic error detection
Instead of printing their identity (A or B) directly, the threads uses the provided trace function.
In each iteration thread A calls trace('A') and thread B calls trace('B').
The trace functions prints the thread identity and keeps track of the next valid thread identity
in the traced sequence. If the wrong thread identity is traced an error is reported and the process is terminated.
Code grading questions
Here are a few examples of questions that you should be able to answer, discuss
and relate to the source code of you solution during the code grading.
How are mutex locks different compared to semaphores?
In general, what will happen when you wait on a semaphore?
In general, What will happen when you signal on a semaphore?
Explain the barrier synchronization concept.
How can semaphores be used to enforce barrier synchronization between two threads?
Why can’t mutex locks be used as drop-in replacements for the semaphores in your solution
with lock instead of wait and unlock instead of signal?
This is a new 1 point higher grade assignment replacing the N Thread barrier
assignment.
In this higher grade assignment you will do a simple simulation of money
transfers between bank accounts.
Git pull
In order to get the new source files and the updated Makefile for this new
assignment, you need to pull the updates from the GitHub repo.
git pull
Overview
In the higher-grade/src directory you find the following files.
bank.h
Header file with the API of the simple bank.
bank.c
The implementation of the bank API.
bank_test.c
A program testing the implemented bank API.
The bank API
The simple bank API is defined in bank.h.
A single bank account is represented by the following C structure.
typedefstruct {
int balance;
} account_t;
What more is needed to be added to the structure?
One ore more pthread mutex locks?
Anything else?
These are the functions in the simple bank API.
/**
* account_new()
* Creates a new bank account.
*
* balance
* The initial balance for the new account.
*
* NOTE: You may need to add more parameters.
*
*/account_t*account_new(unsignedint balance);
/**
* account_destroy()
* Destroys a bank account, freeing the resources it might hold.
*
* account:
* Pointer to a bank account.
*
*/voidaccount_destroy(account_t* account);
/**
* transfer()
* Attempts to transfer money from one account to another.
*
* amount:
* Amount to transfer.
*
* from:
* The account to transfer money from. Money should only be transferred if
* thee are sufficient funds.
*
* to:
* The account to transfer the money to.
*
* return value:
* Return -1 if not sufficient funds in the from account. Otherwise returns 0.
*
*/inttransfer(int amount, account_t* from, account_t* to);
Add synchronization
You must add the needed synchronization.
Prevent deadlocks
You must make sure to prevent deadlocks.
Pthread mutex locks
This is an example of how you can declare and initialize a Pthread mutex lock.
In bank_test.c you find a working program testing your implementation.
Compile and run the test of the simple bank API.
Compile:
make
, and run the test program:
./bin/bank_test
Example of correct synchronization
This is an example showing two rounds of correct synchronization.
Account Amount
------------------
0 5001 02 03 2004 05 06 07 08 09 0------------------
Sum: 700Round 1 of 100From Amount To Result
7 ---- 200 ---> 8 Insufficient funds
1 ---- 200 ---> 7 Insufficient funds
2 ---- 200 ---> 7 Insufficient funds
0 ---- 150 ---> 4 Ok
3 ---- 200 ---> 0 Ok
Account Amount
------------------
0 5501 02 03 04 1505 06 07 08 09 0------------------
Sum: 700Total amount of money was initially 700 and is now 700.
System invariant (conservation of money) not broken.
Example of incorrect synchronization
In this example, everything looks ok in round 4, but in round 5 a race condition
is detected.
Round 4 of 100From Amount To Result
8 ---- 050 ---> 3 Insufficient funds
1 ---- 200 ---> 7 Insufficient funds
4 ---- 100 ---> 6 Insufficient funds
2 ---- 150 ---> 6 Insufficient funds
4 ---- 150 ---> 7 Insufficient funds
Account Amount
------------------
0 5001 502 03 504 05 06 1007 08 09 0------------------
Sum: 700Total amount of money was initially 700 and is now 700.
System invariant (conservation of money) not broken.
Round 5 of 100From Amount To Result
4 ---- 250 ---> 9 Insufficient funds
9 ---- 150 ---> 3 Insufficient funds
8 ---- 100 ---> 0 Insufficient funds
0 ---- 100 ---> 5 Ok
0 ---- 100 ---> 9 Ok
Account Amount
------------------
0 4001 502 03 504 05 1006 1007 08 09 100------------------
Sum: 800Total amount of money was initially 700 and is now 800.
RACE CONDITION: System invariant (conservation of money) broken!
Deadlock
You must make sure the simulation never deadlocks. If a deadlock occur, the
simulation will halt, for example like this.
Round 57 of 100From Amount To Result
1 ---- 250 ---> 7 Insufficient funds
6 ---- 150 ---> 3 Insufficient funds
6 ---- 100 ---> 3 Insufficient funds
9 ---- 100 ---> 7 Insufficient funds
8 ---- 100 ---> 5 Ok
Account Amount
------------------
0 501 502 503 504 05 1006 07 1008 3009 0------------------
Sum: 700Total amount of money was initially 700 and is now 700.
System invariant (conservation of money) not broken.
Round 58 of 100From Amount To Result
0 ---- 200 ---> 1 Insufficient funds
2 ---- 050 ---> 7 Ok
3 ---- 200 ---> 7 Insufficient funds
Bounded buffer
Mandatory assignment
Introduction
The bounded-buffer problems (aka the producer-consumer problem) is a classic
example of concurrent access to a shared resource. A bounded buffer lets
multiple producers and multiple consumers share a single buffer. Producers write data
to the buffer and consumers read data from the buffer.
Producers must block if the buffer is full.
Consumers must block if the buffer is empty.
Preparations
Among the slides you find self study material about classic
synchronization problems. In these slides the bounded buffer
problem is described. Before you continue, make sure to read the self study
slides about the bounded buffer problem.
Synchronization
A bounded buffer with capacity N has can store N data items. The places used
to store the data items inside the bounded buffer are called slots. Without
proper synchronization the following errors may occur.
The producers doesn’t block when the buffer is full.
Two or more producers writes into the same slot.
The consumers doesn’t block when the buffer is emtpy.
A Consumer consumes an empty slot in the buffer.
A consumer attempts to consume a slot that is only half-filled by a producer.
Two or more consumers reads the same slot.
And possibly more …
Overview of the provided source code
You will implement the bounded buffer as an abstract datatype. These
are the files you will use to implement and test your implementation.
bounded_buffer.h
The internal representation of the bounded buffer and the public API is
defined in mandatory/src/bounded_buffer.h.
bounded_buffer.c
The implementation of the API will be in the
mandatory/src/bounded_buffer.c file.
bounded_buffer_test.c
To test your various aspect of your implementation a collection of tests are provided in the
mandatory/src/bounded_buffer_test.c file. Here you can add your own
tests if you want.
bounded_buffer_stress_test.c
The mandatory/src/bounded_buffer_test.c program make it easy to
test the implementation for different sizes of the buffer and different numbers
of producers and consumers.
Supported platforms
The provided code has been developed and tested on the department Linux system
and macOS. Most likely you will be able to use any resonable modern version of
Linux.
Semaphores
You will us the psem semaphores to synchronize the bounded buffer.
Data structures
To implement the bounded buffer you will use two C structures
and an array of C structures.
Tuple
The buffer will store tuples (pairs) with two integer
elements a and b. A tuple is represented by the following C struct.
typedefstruct {
int a;
int b;
} tuple_t;
Buffer array
To implement the bounded buffer a finite size array in memory is shared by a
number for producer and consumer threads.
Producer threads “produce” an item and place the item in the array.
Consumer threads remove an item from the array and “consume” it.
In addition to the shared array, information about the state of the buffer must
also be shared.
Which slots in buffer are free?
To which slot should the next data item be stored?
Which parts of the buffer are filled?
From which slot should the next data item be read?
In the below example three data items B, C and D are currently in the buffer. On
the next write data will be written to index in = 4 . On the next read
data will be read from index out = 1.
Buffer struct
The buffer is represented by the following C struct.
typedefstruct {
tuple_t*array;
int size;
int in;
int out;
psem_t*mutex;
psem_t*data;
psem_t*empty;
} buffer_t;
The purpose of the struct members are described below.
tuple_t *array
This pointer will point to a dynamically allocated array of buffer items of
type tuple_t.
int size
The number of elements in the array, i.e., the size of the buffer.
int in
The index in the array where the next item should be produced.
int out
The index in the array from where the next item should be consumed.
psem_t *mutex
A binary semaphore used to enforce mutual exclusive updates to the buffer.
psem_t *data
A counting semaphore used to count the number of items in the buffer. This
semaphore will be used to block consumers if the buffer is empty.
psem_t *empty
A counting semaphore used to count the number of empty slots in the buffer.
This semaphore will be used to block producers if the buffer is full.
Critical sections and mutual exclusion
All updates to the buffer state must be done in a critical section. More
specifically, mutual exclusion must be enforced between the following critical
sections:
A producer writing to a buffer slot and updatingin.
A consumer reading from a buffer slot and updatingout.
A binary semaphore can be used to protect access to the critical sections.
Synchronize producers and consumers
Producers must block if the buffer is full. Consumers must block if the buffer is
empty. Two counting semaphores can be used for this.
Use one semaphore named empty to count the empty slots in the buffer.
Initialise this semaphore to N.
A producer must wait on this semaphore before writing to the buffer.
A consumer will signal this semaphore after reading from the buffer.
Use one semaphore named data to count the number of data items in the buffer.
Initialise this semaphore to 0.
A consumer must wait on this semaphore before reading from the buffer.
A producer will signal this semaphore after writing to the buffer.
Initialization example
A new bounded buffer with 10 elements will be represented as follows.
The empty semaphore counts the number of
empty slots in the buffer and is initialized to 10. Initially there are no
data element to be consumed in the buffer and the data semaphore is
initialized to 0. The mutex semaphore will be used to enforece mutex when
updating the buffer and is initialized to 1.
Implementation
To complete the implementation you must add code at a few places.
For each step you will need to add code to a single function in the
mandatory/src/bounded_buffer.c source file. For each step there
is also a test in the mandatory/src/bounded_buffer_test.c source
file that should pass without any failed assertions.
In the terminal, navigate to the mandatory directory. Use make to compile the program.
make
Run the test(s).
./bin/bounded_buffer_test
An example of a failed test where the assertion that the buffer size should be
10 fails.
==== init_test ====Assertion failed: (buffer.size ==10), function init_test, file src/bounded_buffer_test.c, line 24.
When a test passes you will see the following output.
Test SUCCESSFUL :-)
Step 1 - Buffer initialization
You must complete the buffer initialization.
Function
buffer_init
Test
init_test
Make sure to initialize all members of the buffer_t struct.
Step 2 - Buffer destruction
You must complete the buffer destruction.
Function
buffer_destroy
Test
destroy_test
Deallocate all resources allocated by buffer_init().
Set all pointers to NULL after dealloacation to avoid dangling
pointers.
Step 3 - Print the buffer
Function
buffer_print
Test
print_test
Add code to print all elements of the buffer array.
Step 4 - Put an item into the buffer
Function
buffer_put
Test
put_test
Here you need to:
add the needed synchronization
update the buffer->in index make sure it wraps around.
Step 5 - Get an item out of the buffer
Function
buffer_get
Test
get_test
Here you need to:
add the needed synchronization
update the buffer->out index make sure it wraps around.
Step 6 - Concurrent puts and gets
For this step you only need to run the concurrent_put_get_test. If the test
doesn’t terminate you most likely have made a mistake with the synchronization of
buffer_put and/or buffer_get that result in a deadlock.
Stress testing
It is now time to test the bounded buffer with multiple concurrent producers and
consumers. In mandatory/src/bounded_buffer_stress_test.c you find a
complete test program that creates:
a bounded buffer of size s
p producer threads, each producing n items into the buffer
c consumer threads, each consuming m items from the buffer
For the test program to terminate, the total number of consumed items (c*m)
must equal the total number of items produced (p*n). Run the stress test.
./bin/bounded_buffer_stress_test
Default stress test
The default stress test will now be exuded. On success you should see output
similar to the following.
Test buffer of size 10 with:
20 producers, each producing 10000 items.
20 consumers, each consuming 10000 items.
Verbose: false
The buffer when the test ends.
---- Bounded Buffer ----
size: 10 in: 0 out: 0array[0]: (7, 9994)array[1]: (15, 9999)array[2]: (13, 9998)array[3]: (4, 9999)array[4]: (7, 9995)array[5]: (13, 9999)array[6]: (7, 9996)array[7]: (7, 9997)array[8]: (7, 9998)array[9]: (7, 9999)---------------------draft: false
---
====> TEST SUCCESS <====
Note the ====> TEST SUCCESS <==== at the end.
Overriding the default parameters
The default values for test parameters can be overridden using the following
flags.
Flag
Description
Argument
-s
Size of the buffer
positive integer
-p
Number of producer threads
positive integer
-n
Number of items produced by each producer
positive integer
-c
Number of consumer threads
positive integer
-m
Number of items consumed by each consumer
positive integer
-v
Turns on verbose output
no argument
In the following example, the default buffer size 10 is changed to 3.
./bin/bounded_buffer_stress_test -s 3
Experiment with different values for the test parameters.
Code grading questions
Here are a few examples of questions that you should be able to answer, discuss
and relate to the source code of you solution during the code grading.
What do we mean by a counting semaphore?
What happens when you do wait on counting semaphore?
What happens when you do signal on a counting semaphore?
Explain how producers and consumers are synchronized in order to:
block consumers if the buffer is empty
block producers if the buffer is full.
Explain why mutex locks cannot be used to synchronize the blocking of
consumers and producers.
Explain why you must ensure mutual exclusive (mutex) when updating the the
buffer array and the in and out array indexes.
Explain how you achieve mutual exclusion (mutex) when updating the the
buffer array and the in and out array indexes.
Implementing threads
A thread library provides programmers with an API for creating and managing
threads. Support for threads must be provided either at the user level or by the kernel.
Kernel level threads are supported and managed directly by the operating
system.
User level threads are supported above the kernel in user space and are
managed without kernel support.
Kernel level threads
Kernel level threads are supported and managed directly by the operating
system.
The kernel knows about and manages all threads.
One process control block (PCP) per process.
One thread control block (TCB) per thread in the system.
Provide system calls to create and manage threads from user space.
Advantages
The kernel has full knowledge of all threads.
Scheduler may decide to give more CPU time to a process having a large number of
threads.
Good for applications that frequently block.
Disadvantages
Kernel manage and schedule all threads.
Significant overhead and increase in kernel complexity.
Kernel level threads are slow and inefficient compared to user level threads.
Thread operations are hundreds of times slower compared to user-level threads.
User level threads
User level threads are supported above the kernel in user space and are
managed without kernel support.
Threads managed entirely by the run-time system (user-level library).
Ideally, thread operations should be as fast as a function call.
The kernel knows nothing about user-level threads and manage them as if they
where single-threaded processes.
Advantages
Can be implemented on an OS that does not support kernel-level threads.
Does not require modifications of the OS.
Simple representation: PC, registers, stack and small thread control block all
stored in the user-level process address space.
Simple management: Creating, switching and synchronizing threads done in
user-space without kernel intervention.
Fast and efficient: switching threads not much more expensive than a function
call.
Disadvantages
Not a perfect solution (a trade off).
Lack of coordination between the user-level thread manager and the kernel.
OS may make poor decisions like:
scheduling a process with idle threads
blocking a process due to a blocking thread even though the process has other
threads that can run
giving a process as a whole one time slice irrespective of whether the process
has 1 or 1000 threads
unschedule a process with a thread holding a lock.
May require communication between the kernel and the user-level thread manager
(scheduler activations) to overcome the above problems.
User-level thread models
In general, user-level threads can be implemented using one of four models.
Many-to-one
One-to-one
Many-to-many
Two-level
All models maps user-level threads to kernel-level threads.
A kernel thread is similar to a process in a
non-threaded (single-threaded) system.
The kernel thread is the unit of execution that is scheduled by the
kernel to execute on the CPU. The term virtual processor is often used instead
of kernel thread.
Many-to-one
In the many-to-one model all user level threads execute on the same kernel
thread. The process can only run one user-level thread at a time because there is only
one kernel-level thread associated with the process.
The kernel has no knowledge of user-level threads. From its perspective, a
process is an opaque black box that occasionally makes system calls.
One-to-one
In the one-to-one model every user-level thread execute on a separate
kernel-level thread.
In this model the kernel must provide a system call for creating a new kernel
thread.
Many-to-many
In the many-to-many model the process is allocated m number of kernel-level threads to execute n number of
user-level thread.
Two-level
The two-level model is similar to the many-to-many model but also allows for
certain user-level threads to be bound to a single kernel-level thread.
Scheduler activations
In both the many-to-many model and the two-level model there must be some way
for the kernel to communicate with the user level thread manager to
maintain an appropriate number of kernel threads allocated to the process.
This mechanism is called scheduler
activations.
The kernel provides the application
with a set of kernel threads (virtual processors), and then the application has complete control
over what threads to run on each of the kernel threads (virtual processors). The number of
kernel threads (virtual processors) in the set is controlled by the kernel, in response to the
competing demands of different processes in the system.1
The kernel notify
the user-level thread manager of important kernel events using upcalls from the kernel to
the user-level thread manager. Examples of such events includes a thread making a
blocking system call and the kernel allocating a new kernel thread to the
process.1
Example
Let’s study an example of how scheduler activations can be used.
The kernel has allocated one kernel thread (1) to a process with three user-level
threads (2). The three user level threads take turn executing on the single kernel-level
thread.
The executing thread makes a blocking system call (3) and the the kernel blocks the calling user-level thread and
the kernel-level thread used to execute the user-level thread (4).
Scheduler activation: the kernel decides to
allocate a new kernel-level thread to the process (5).
Upcall: the kernel notifies the user-level thread manager which user-level thread
that is now blocked and that a new kernel-level thread is available (6).
The user-level thread manager move the other threads to the new kernel
thread and resumes one of the ready threads (7).
While one user-level thread is blocked (8) the other threads can take turn
executing on the new kernel thread (9).
User-level thread scheduling
Scheduling of the usea-level threads among the available kernel-level threads is done by
a thread scheduler implemented in user space.
There are two main methods: cooperative and preemptive thread scheduling.
Cooperative scheduling of user-level threads
The cooperative model is similar to multiprogramming where a process executes on the CPU
until making a I/O request. Cooperative user-level threads execute on the
assigned kernel-level thread until they voluntarily give back the kernel thread
to the thread manager.
In the cooperative model, threads yield to each other, either explicitly (e.g., by
calling a yield() provided by the user-level thread library) or implicitly (e.g., requesting a
lock held by another thread). In the below figure a many-to-one system with
cooperative user-level threads is shown.
Preemptive scheduling of user-level threads
The preemptive model is similar to multitasking (aka time sharing). Multitasking
is a logical extension of multiprogramming where a timer is
set to cause an interrupt at a regular time interval and the
running process is replaced if the job requests I/O or if the job is interrupted
by the timer. This way, the running job is given a time slice of execution than
cannot be exceeded.
In the preemptive model, a timer is used to cause
execution flow to jump to a central dispatcher thread, which chooses the next
thread to run. In the below figure a many-to-one system with preemptive
user-level threads is shown.
Cooperative and preemptive (hybrid) scheduling of user-level threads
A hybrid model between cooperative and preemptive scheduling is also possible
where a running thread may yield() or preempted by a timer.
In this assignment you will implement a simplified version of many-to-one user level
threads in form of a library that we give the name Simple Threads.
Preparations
Before you continue make sure you’ve read the implementing threads page.
Among the slides in Studium you also find self study material about implementing threads.
The ucontext.h header file defines the ucontext_t type as a structure that
can be used to store the execution context of a user-level thread in user space.
The same header file also defines a small set of functions used to manipulate
execution contexts. Read the following manual pages.
In examples/src/contexts.c you find an example program demonstrating
how to create and manipulate execution contexts.
Study the source. To compile, navigate to the examples directory in the terminal, type make
and press enter.
Study the source and pay attention to all comments.
First compile and test run
In the terminal, navigate to the higher-grade directory. Use make to
compile.
make
Run the test program.
./bin/sthreads_test
The program prints the following to terminal and terminates.
==== Test program for the Simple Threads API ====
Cooperative scheduling (2 points)
For grade 2 points you must implement all the functions in the Simple Threads API
exceptdone() and join. This includes cooperative scheduling where
threads yield() control back to the thread manager.
The test program’s main() thread and all threads
created by main() share a single
kernel-level thread. The threads must call yield() to pass control to the thread
manager. When
calling yield() one of the ready threads is selected to execute and changes
state from ready to running. The thread calling yield() changes state from
running to ready.
Non-terminating threads
For grade 4 you may assume the main thread and all other threads are
non-terminating loops.
Preemptive scheduling (3 points)
For 3 points, you must also implement the done() and join() functions in the
Simple Threads API. In addition to cooperative scheduling with yield() you must also implement
preemptive scheduling.
If a thread doesn’t call yield() within its time slice it will be preempted
and one of the threads in the ready queue will be resumed. The preempted thread
changes state from running to ready. The resumed thread changes state from ready
to running.
Timer
To implement preemptive scheduling you need to set a timer. When the timer
expires the kernel will send a signal to the process. You must register a signal
handler for the timer signal. In the signal handler you must figure out a way to
suspend the running thread and resume one of the threads in the ready queue.
Timer example
In examples/src/timer.c you find an example of how to set a timer.
When the timer expires the kernel sends a signal to the process. A signal
handler is used to catch the timer signal.